 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlots Unlock Time-Series Understanding in Multimodal Models
Oct 03, 2024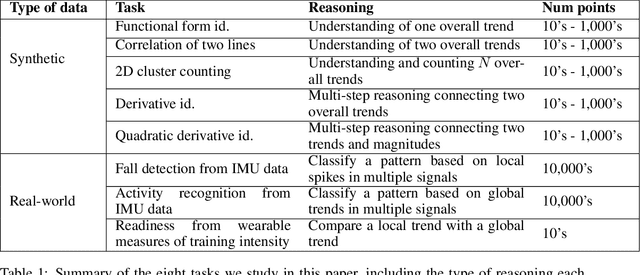

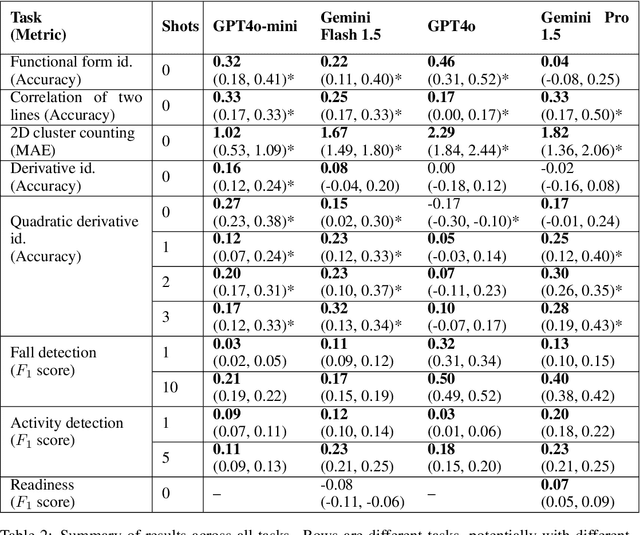
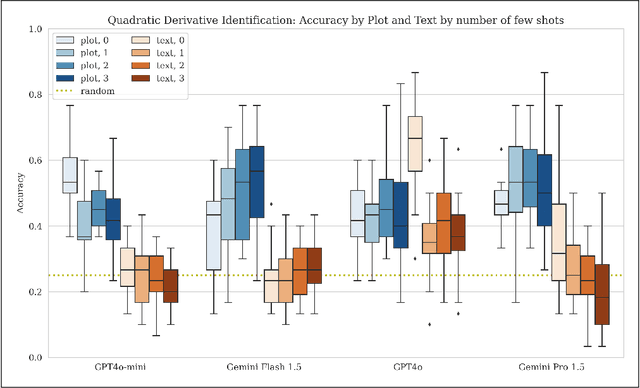
While multimodal foundation models can now natively work with data beyond text, they remain underutilized in analyzing the considerable amounts of multi-dimensional time-series data in fields like healthcare, finance, and social sciences, representing a missed opportunity for richer, data-driven insights. This paper proposes a simple but effective method that leverages the existing vision encoders of these models to "see" time-series data via plots, avoiding the need for additional, potentially costly, model training. Our empirical evaluations show that this approach outperforms providing the raw time-series data as text, with the additional benefit that visual time-series representations demonstrate up to a 90% reduction in model API costs. We validate our hypothesis through synthetic data tasks of increasing complexity, progressing from simple functional form identification on clean data, to extracting trends from noisy scatter plots. To demonstrate generalizability from synthetic tasks with clear reasoning steps to more complex, real-world scenarios, we apply our approach to consumer health tasks - specifically fall detection, activity recognition, and readiness assessment - which involve heterogeneous, noisy data and multi-step reasoning. The overall success in plot performance over text performance (up to an 120% performance increase on zero-shot synthetic tasks, and up to 150% performance increase on real-world tasks), across both GPT and Gemini model families, highlights our approach's potential for making the best use of the native capabilities of foundation models.
Metadata Improves Segmentation Through Multitasking Elicitation
Aug 18, 2023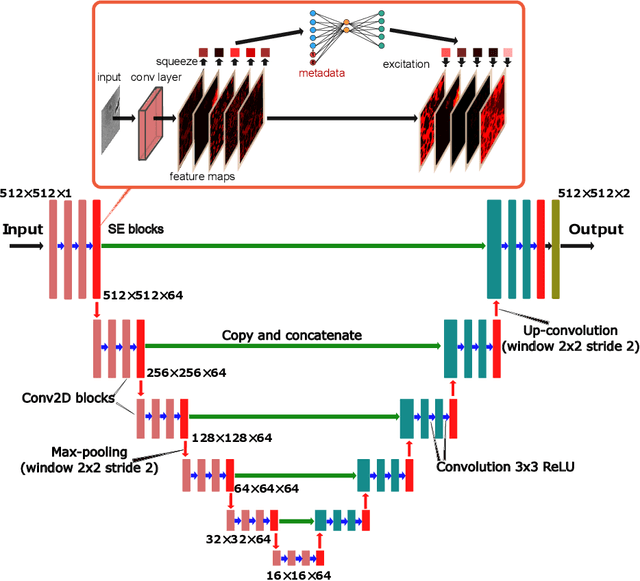
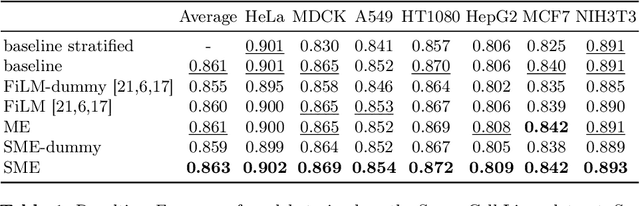
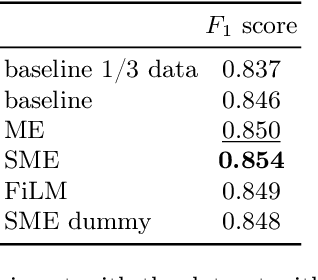
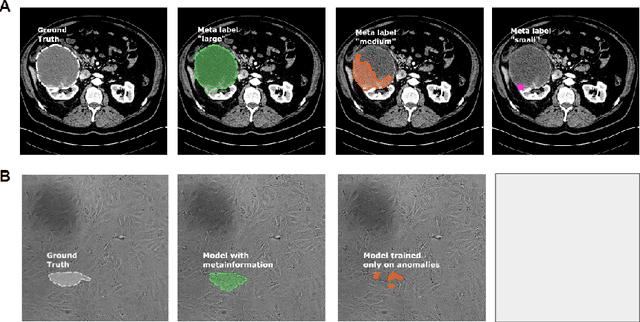
Metainformation is a common companion to biomedical images. However, this potentially powerful additional source of signal from image acquisition has had limited use in deep learning methods, for semantic segmentation in particular. Here, we incorporate metadata by employing a channel modulation mechanism in convolutional networks and study its effect on semantic segmentation tasks. We demonstrate that metadata as additional input to a convolutional network can improve segmentation results while being inexpensive in implementation as a nimble add-on to popular models. We hypothesize that this benefit of metadata can be attributed to facilitating multitask switching. This aspect of metadata-driven systems is explored and discussed in detail.
Self-Supervised Single-Image Deconvolution with Siamese Neural Networks
Aug 18, 2023



Inverse problems in image reconstruction are fundamentally complicated by unknown noise properties. Classical iterative deconvolution approaches amplify noise and require careful parameter selection for an optimal trade-off between sharpness and grain. Deep learning methods allow for flexible parametrization of the noise and learning its properties directly from the data. Recently, self-supervised blind-spot neural networks were successfully adopted for image deconvolution by including a known point-spread function in the end-to-end training. However, their practical application has been limited to 2D images in the biomedical domain because it implies large kernels that are poorly optimized. We tackle this problem with Fast Fourier Transform convolutions that provide training speed-up in 3D microscopy deconvolution tasks. Further, we propose to adopt a Siamese invariance loss for deconvolution and empirically identify its optimal position in the neural network between blind-spot and full image branches. The experimental results show that our improved framework outperforms the previous state-of-the-art deconvolution methods with a known point spread function.
SwinIA: Self-Supervised Blind-Spot Image Denoising with Zero Convolutions
May 09, 2023The essence of self-supervised image denoising is to restore the signal from the noisy image alone. State-of-the-art solutions for this task rely on the idea of masking pixels and training a fully-convolutional neural network to impute them. This most often requires multiple forward passes, information about the noise model, and intricate regularization functions. In this paper, we propose a Swin Transformer-based Image Autoencoder (SwinIA), the first convolution-free architecture for self-supervised denoising. It can be trained end-to-end with a simple mean squared error loss without masking and does not require any prior knowledge about clean data or noise distribution. Despite its simplicity, SwinIA establishes state-of-the-art on several common benchmarks.
Noise2Stack: Improving Image Restoration by Learning from Volumetric Data
Nov 10, 2020
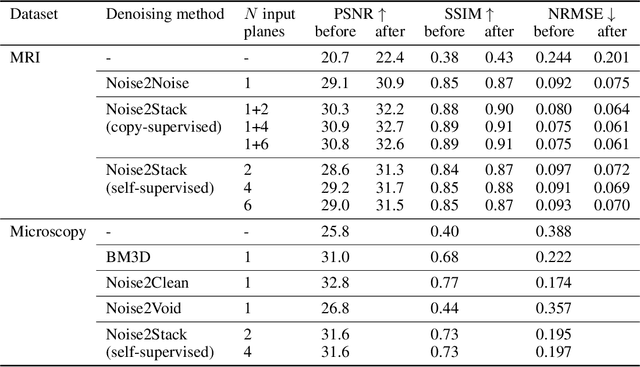
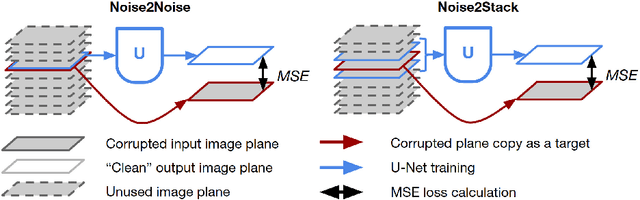

Biomedical images are noisy. The imaging equipment itself has physical limitations, and the consequent experimental trade-offs between signal-to-noise ratio, acquisition speed, and imaging depth exacerbate the problem. Denoising is, therefore, an essential part of any image processing pipeline, and convolutional neural networks are currently the method of choice for this task. One popular approach, Noise2Noise, does not require clean ground truth, and instead, uses a second noisy copy as a training target. Self-supervised methods, like Noise2Self and Noise2Void, relax data requirements by learning the signal without an explicit target but are limited by the lack of information in a single image. Here, we introduce Noise2Stack, an extension of the Noise2Noise method to image stacks that takes advantage of a shared signal between spatially neighboring planes. Our experiments on magnetic resonance brain scans and newly acquired multiplane microscopy data show that learning only from image neighbors in a stack is sufficient to outperform Noise2Noise and Noise2Void and close the gap to supervised denoising methods. Our findings point towards low-cost, high-reward improvement in the denoising pipeline of multiplane biomedical images. As a part of this work, we release a microscopy dataset to establish a benchmark for the multiplane image denoising.