 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Beyond U-Net: Assessing Vision Transformers for Semantic Segmentation in Microscopy Image Analysis
Sep 25, 2024Segmentation is a crucial step in microscopy image analysis. Numerous approaches have been developed over the past years, ranging from classical segmentation algorithms to advanced deep learning models. While U-Net remains one of the most popular and well-established models for biomedical segmentation tasks, recently developed transformer-based models promise to enhance the segmentation process of microscopy images. In this work, we assess the efficacy of transformers, including UNETR, the Segment Anything Model, and Swin-UPerNet, and compare them with the well-established U-Net model across various image modalities such as electron microscopy, brightfield, histopathology, and phase-contrast. Our evaluation identifies several limitations in the original Swin Transformer model, which we address through architectural modifications to optimise its performance. The results demonstrate that these modifications improve segmentation performance compared to the classical U-Net model and the unmodified Swin-UPerNet. This comparative analysis highlights the promise of transformer models for advancing biomedical image segmentation. It demonstrates that their efficiency and applicability can be improved with careful modifications, facilitating their future use in microscopy image analysis tools.
COIN: Counterfactual inpainting for weakly supervised semantic segmentation for medical images
Apr 19, 2024Deep learning is dramatically transforming the field of medical imaging and radiology, enabling the identification of pathologies in medical images, including computed tomography (CT) and X-ray scans. However, the performance of deep learning models, particularly in segmentation tasks, is often limited by the need for extensive annotated datasets. To address this challenge, the capabilities of weakly supervised semantic segmentation are explored through the lens of Explainable AI and the generation of counterfactual explanations. The scope of this research is development of a novel counterfactual inpainting approach (COIN) that flips the predicted classification label from abnormal to normal by using a generative model. For instance, if the classifier deems an input medical image X as abnormal, indicating the presence of a pathology, the generative model aims to inpaint the abnormal region, thus reversing the classifier's original prediction label. The approach enables us to produce precise segmentations for pathologies without depending on pre-existing segmentation masks. Crucially, image-level labels are utilized, which are substantially easier to acquire than creating detailed segmentation masks. The effectiveness of the method is demonstrated by segmenting synthetic targets and actual kidney tumors from CT images acquired from Tartu University Hospital in Estonia. The findings indicate that COIN greatly surpasses established attribution methods, such as RISE, ScoreCAM, and LayerCAM, as well as an alternative counterfactual explanation method introduced by Singla et al. This evidence suggests that COIN is a promising approach for semantic segmentation of tumors in CT images, and presents a step forward in making deep learning applications more accessible and effective in healthcare, where annotated data is scarce.
Metadata Improves Segmentation Through Multitasking Elicitation
Aug 18, 2023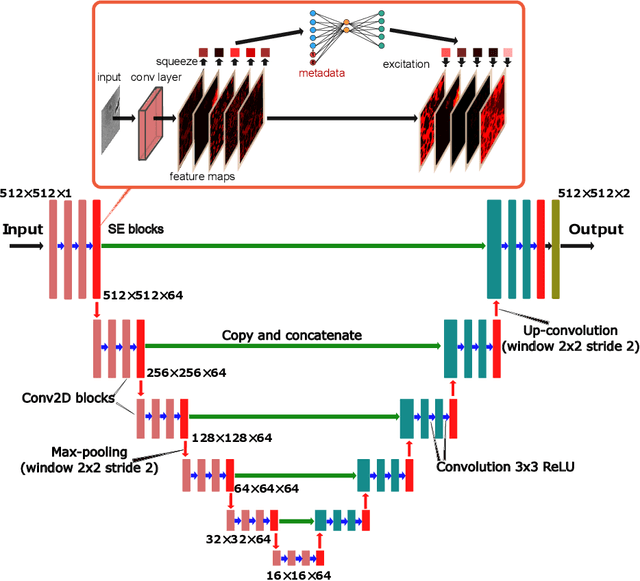
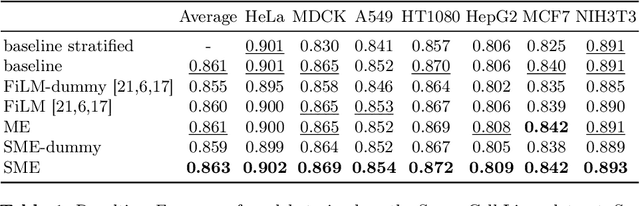
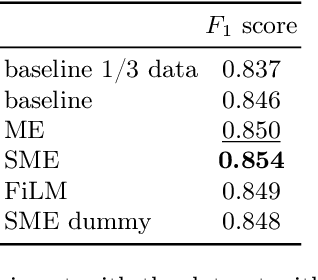
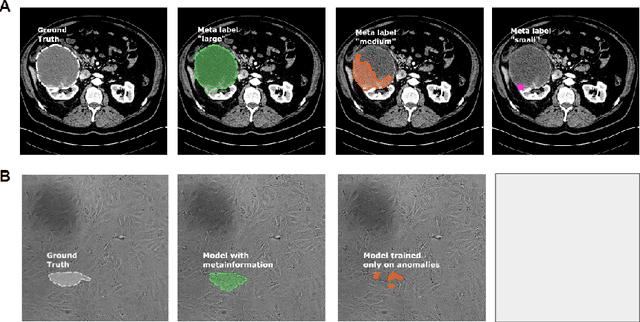
Metainformation is a common companion to biomedical images. However, this potentially powerful additional source of signal from image acquisition has had limited use in deep learning methods, for semantic segmentation in particular. Here, we incorporate metadata by employing a channel modulation mechanism in convolutional networks and study its effect on semantic segmentation tasks. We demonstrate that metadata as additional input to a convolutional network can improve segmentation results while being inexpensive in implementation as a nimble add-on to popular models. We hypothesize that this benefit of metadata can be attributed to facilitating multitask switching. This aspect of metadata-driven systems is explored and discussed in detail.
Noise2Stack: Improving Image Restoration by Learning from Volumetric Data
Nov 10, 2020
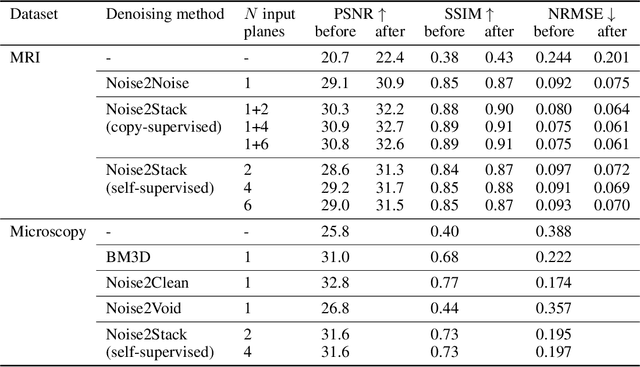
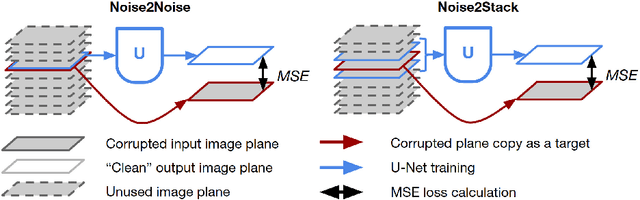

Biomedical images are noisy. The imaging equipment itself has physical limitations, and the consequent experimental trade-offs between signal-to-noise ratio, acquisition speed, and imaging depth exacerbate the problem. Denoising is, therefore, an essential part of any image processing pipeline, and convolutional neural networks are currently the method of choice for this task. One popular approach, Noise2Noise, does not require clean ground truth, and instead, uses a second noisy copy as a training target. Self-supervised methods, like Noise2Self and Noise2Void, relax data requirements by learning the signal without an explicit target but are limited by the lack of information in a single image. Here, we introduce Noise2Stack, an extension of the Noise2Noise method to image stacks that takes advantage of a shared signal between spatially neighboring planes. Our experiments on magnetic resonance brain scans and newly acquired multiplane microscopy data show that learning only from image neighbors in a stack is sufficient to outperform Noise2Noise and Noise2Void and close the gap to supervised denoising methods. Our findings point towards low-cost, high-reward improvement in the denoising pipeline of multiplane biomedical images. As a part of this work, we release a microscopy dataset to establish a benchmark for the multiplane image denoising.
Recommendations for machine learning validation in biology
Jun 25, 2020

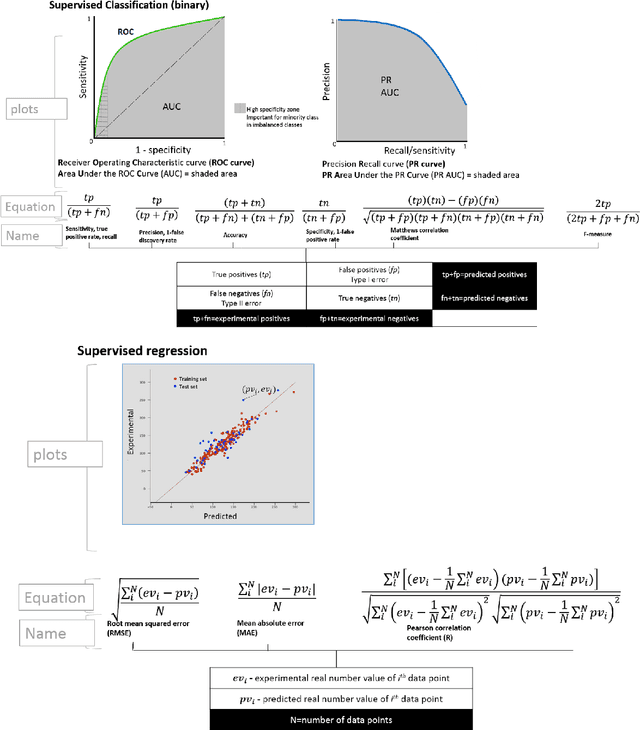
Modern biology frequently relies on machine learning to provide predictions and improve decision processes. There have been recent calls for more scrutiny on machine learning performance and possible limitations. Here we present a set of community-wide recommendations aiming to help establish standards of machine learning validation in biology. Adopting a structured methods description for machine learning based on DOME (data, optimization, model, evaluation) will allow both reviewers and readers to better understand and assess the performance and limitations of a method or outcome. The recommendations are complemented by a machine learning summary table which can be easily included in the supplementary material of published papers.
A Survey of End-to-End Driving: Architectures and Training Methods
Mar 13, 2020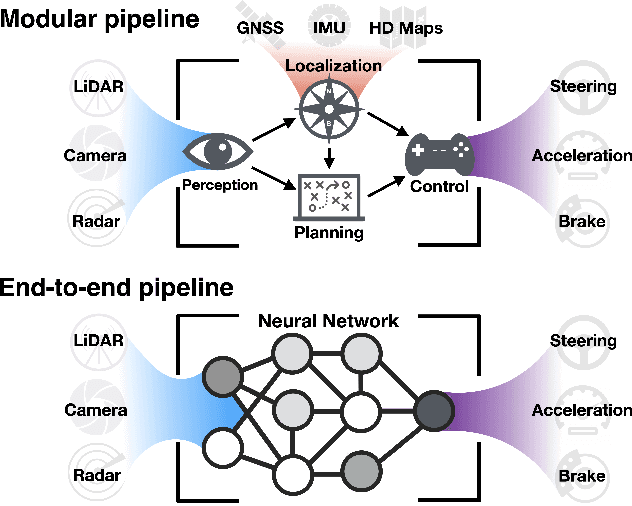
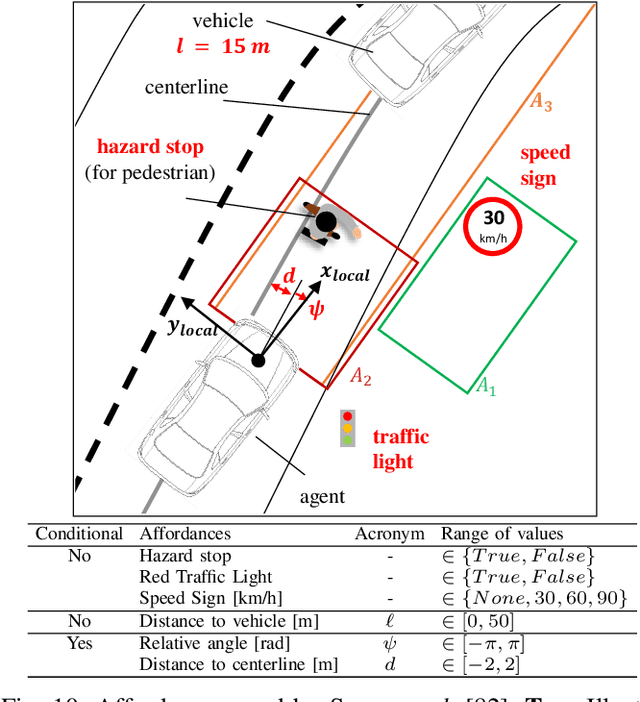


Autonomous driving is of great interest to industry and academia alike. The use of machine learning approaches for autonomous driving has long been studied, but mostly in the context of perception. In this paper we take a deeper look on the so called end-to-end approaches for autonomous driving, where the entire driving pipeline is replaced with a single neural network. We review the learning methods, input and output modalities, network architectures and evaluation schemes in end-to-end driving literature. Interpretability and safety are discussed separately, as they remain challenging for this approach. Beyond providing a comprehensive overview of existing methods, we conclude the review with an architecture that combines the most promising elements of the end-to-end autonomous driving systems.