 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Company You Keep: How LLMs Respond to Dark Triad Traits
Mar 04, 2026Large Language Models (LLMs) often exhibit highly agreeable and reinforcing conversational styles, also known as AI-sycophancy. Although this behavior is encouraged, it may become problematic when interacting with user prompts that reflect negative social tendencies. Such responses risk amplifying harmful behavior rather than mitigating it. In this study, we examine how LLMs respond to user prompts expressing varying degrees of Dark Triad traits (Machiavellianism, Narcissism, and Psychopathy) using a curated dataset. Our analysis reveals differences across models, whereby all models predominantly exhibit corrective behavior, while showing reinforcing output in certain cases. Model behavior also depends on the severity level and differs in the sentiment of the response. Our findings raise implications for designing safer conversational systems that can detect and respond appropriately when users escalate from benign to harmful requests.
Surface Fairness, Deep Bias: A Comparative Study of Bias in Language Models
Jun 12, 2025



Modern language models are trained on large amounts of data. These data inevitably include controversial and stereotypical content, which contains all sorts of biases related to gender, origin, age, etc. As a result, the models express biased points of view or produce different results based on the assigned personality or the personality of the user. In this paper, we investigate various proxy measures of bias in large language models (LLMs). We find that evaluating models with pre-prompted personae on a multi-subject benchmark (MMLU) leads to negligible and mostly random differences in scores. However, if we reformulate the task and ask a model to grade the user's answer, this shows more significant signs of bias. Finally, if we ask the model for salary negotiation advice, we see pronounced bias in the answers. With the recent trend for LLM assistant memory and personalization, these problems open up from a different angle: modern LLM users do not need to pre-prompt the description of their persona since the model already knows their socio-demographics.
Even Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
Apr 25, 2025



We introduce a new generation of small reasoning models for RAG, search, and source summarization. Pleias-RAG-350m and Pleias-RAG-1B are mid-trained on a large synthetic dataset emulating the retrieval of a wide variety of multilingual open sources from the Common Corpus. They provide native support for citation and grounding with literal quotes and reintegrate multiple features associated with RAG workflows, such as query routing, query reformulation, and source reranking. Pleias-RAG-350m and Pleias-RAG-1B outperform SLMs below 4 billion parameters on standardized RAG benchmarks (HotPotQA, 2wiki) and are competitive with popular larger models, including Qwen-2.5-7B, Llama-3.1-8B, and Gemma-3-4B. They are the only SLMs to date maintaining consistent RAG performance across leading European languages and ensuring systematic reference grounding for statements. Due to their size and ease of deployment on constrained infrastructure and higher factuality by design, the models unlock a range of new use cases for generative AI.
What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Apr 10, 2025
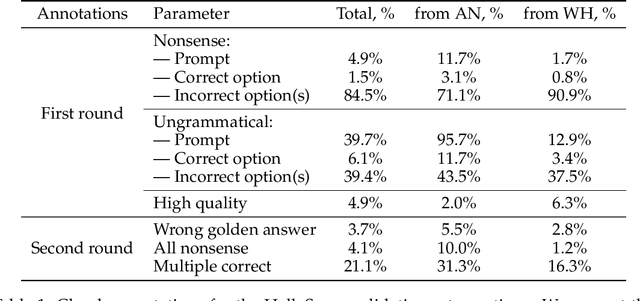
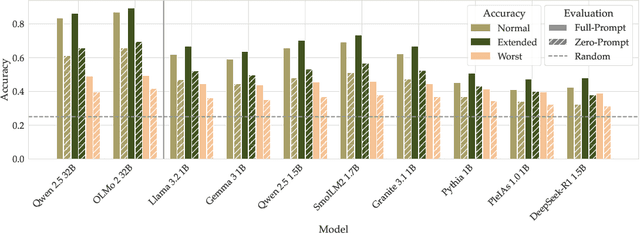
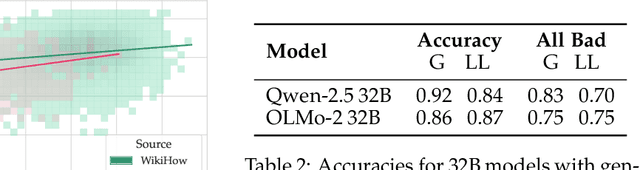
Common-sense reasoning is a key language model capability because it encapsulates not just specific factual knowledge but rather general language and world understanding. Measuring common-sense reasoning, therefore, is crucial for language models of different sizes and applications. One of the most widely used benchmarks for evaluating such capabilities is HellaSwag; however, in this paper, we show that it has severe construct validity issues. These issues range from basic ungrammaticality and numerous typos to misleading prompts or equally correct options. Furthermore, we show that if models are evaluated only on answer texts, or with "Lorem ipsum dolor..." instead of the question, more than 65% of model predictions remain the same, and this cannot be attributed merely to contamination. Since benchmark scores are an essential part of model selection in both research and commercial applications, these validity issues can have severe consequences. In particular, knowing that taking benchmark scores at face value is ubiquitous, inadequate evaluation leads to ill-informed decisions about models. In this paper, we thoroughly investigate critical validity issues posed by HellaSwag and illustrate them with various evaluations using generative language models of different sizes. We argue that this benchmark does not accurately measure common-sense reasoning and, therefore, should not be used for evaluation in its current state. Based on the results of our study, we propose requirements that should be met by future common-sense reasoning benchmarks. In addition, we release GoldenSwag, a corrected subset of HellaSwag, which, to our belief, facilitates acceptable common-sense reasoning evaluation.
Going Beyond U-Net: Assessing Vision Transformers for Semantic Segmentation in Microscopy Image Analysis
Sep 25, 2024Segmentation is a crucial step in microscopy image analysis. Numerous approaches have been developed over the past years, ranging from classical segmentation algorithms to advanced deep learning models. While U-Net remains one of the most popular and well-established models for biomedical segmentation tasks, recently developed transformer-based models promise to enhance the segmentation process of microscopy images. In this work, we assess the efficacy of transformers, including UNETR, the Segment Anything Model, and Swin-UPerNet, and compare them with the well-established U-Net model across various image modalities such as electron microscopy, brightfield, histopathology, and phase-contrast. Our evaluation identifies several limitations in the original Swin Transformer model, which we address through architectural modifications to optimise its performance. The results demonstrate that these modifications improve segmentation performance compared to the classical U-Net model and the unmodified Swin-UPerNet. This comparative analysis highlights the promise of transformer models for advancing biomedical image segmentation. It demonstrates that their efficiency and applicability can be improved with careful modifications, facilitating their future use in microscopy image analysis tools.
BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Sep 06, 2024Language models can largely benefit from efficient tokenization. However, they still mostly utilize the classical BPE algorithm, a simple and reliable method. This has been shown to cause such issues as under-trained tokens and sub-optimal compression that may affect the downstream performance. We introduce Picky BPE, a modified BPE algorithm that carries out vocabulary refinement during tokenizer training. Our method improves vocabulary efficiency, eliminates under-trained tokens, and does not compromise text compression. Our experiments show that our method does not reduce the downstream performance, and in several cases improves it.
SwinIA: Self-Supervised Blind-Spot Image Denoising with Zero Convolutions
May 09, 2023The essence of self-supervised image denoising is to restore the signal from the noisy image alone. State-of-the-art solutions for this task rely on the idea of masking pixels and training a fully-convolutional neural network to impute them. This most often requires multiple forward passes, information about the noise model, and intricate regularization functions. In this paper, we propose a Swin Transformer-based Image Autoencoder (SwinIA), the first convolution-free architecture for self-supervised denoising. It can be trained end-to-end with a simple mean squared error loss without masking and does not require any prior knowledge about clean data or noise distribution. Despite its simplicity, SwinIA establishes state-of-the-art on several common benchmarks.