 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel in Distress: Sentiment Analysis on French Synthetic Social Media
Apr 20, 2026Automated analysis of customer feedback on social media is hindered by three challenges: the high cost of annotated training data, the scarcity of evaluation sets, especially in multilingual settings, and privacy concerns that prevent data sharing and reproducibility. We address these issues by developing a generalizable synthetic data generation pipeline applied to a case study on customer distress detection in French public transportation. Our approach utilizes backtranslation with fine-tuned models to generate 1.7 million synthetic tweets from a small seed corpus, complemented by synthetic reasoning traces. We train 600M-parameter reasoners with English and French reasoning that achieve 77-79% accuracy on human-annotated evaluation data, matching or exceeding SOTA proprietary LLMs and specialized encoders. Beyond reducing annotation costs, our pipeline preserves privacy by eliminating the exposure of sensitive user data. Our methodology can be adopted for other use cases and languages.
From Where Words Come: Efficient Regularization of Code Tokenizers Through Source Attribution
Apr 15, 2026Efficiency and safety of Large Language Models (LLMs), among other factors, rely on the quality of tokenization. A good tokenizer not only improves inference speed and language understanding but also provides extra defense against jailbreak attacks and lowers the risk of hallucinations. In this work, we investigate the efficiency of code tokenization, in particular from the perspective of data source diversity. We demonstrate that code tokenizers are prone to producing unused, and thus under-trained, tokens due to the imbalance in repository and language diversity in the training data, as well as the dominance of source-specific, repetitive tokens that are often unusable in future inference. By modifying the BPE objective and introducing merge skipping, we implement different techniques under the name Source-Attributed BPE (SA-BPE) to regularize BPE training and minimize overfitting, thereby substantially reducing the number of under-trained tokens while maintaining the same inference procedure as with regular BPE. This provides an effective tool suitable for production use.
The Company You Keep: How LLMs Respond to Dark Triad Traits
Mar 04, 2026Large Language Models (LLMs) often exhibit highly agreeable and reinforcing conversational styles, also known as AI-sycophancy. Although this behavior is encouraged, it may become problematic when interacting with user prompts that reflect negative social tendencies. Such responses risk amplifying harmful behavior rather than mitigating it. In this study, we examine how LLMs respond to user prompts expressing varying degrees of Dark Triad traits (Machiavellianism, Narcissism, and Psychopathy) using a curated dataset. Our analysis reveals differences across models, whereby all models predominantly exhibit corrective behavior, while showing reinforcing output in certain cases. Model behavior also depends on the severity level and differs in the sentiment of the response. Our findings raise implications for designing safer conversational systems that can detect and respond appropriately when users escalate from benign to harmful requests.
Better Call Claude: Can LLMs Detect Changes of Writing Style?
Aug 01, 2025This article explores the zero-shot performance of state-of-the-art large language models (LLMs) on one of the most challenging tasks in authorship analysis: sentence-level style change detection. Benchmarking four LLMs on the official PAN~2024 and 2025 "Multi-Author Writing Style Analysis" datasets, we present several observations. First, state-of-the-art generative models are sensitive to variations in writing style - even at the granular level of individual sentences. Second, their accuracy establishes a challenging baseline for the task, outperforming suggested baselines of the PAN competition. Finally, we explore the influence of semantics on model predictions and present evidence suggesting that the latest generation of LLMs may be more sensitive to content-independent and purely stylistic signals than previously reported.
Team "better_call_claude": Style Change Detection using a Sequential Sentence Pair Classifier
Aug 01, 2025Style change detection - identifying the points in a document where writing style shifts - remains one of the most important and challenging problems in computational authorship analysis. At PAN 2025, the shared task challenges participants to detect style switches at the most fine-grained level: individual sentences. The task spans three datasets, each designed with controlled and increasing thematic variety within documents. We propose to address this problem by modeling the content of each problem instance - that is, a series of sentences - as a whole, using a Sequential Sentence Pair Classifier (SSPC). The architecture leverages a pre-trained language model (PLM) to obtain representations of individual sentences, which are then fed into a bidirectional LSTM (BiLSTM) to contextualize them within the document. The BiLSTM-produced vectors of adjacent sentences are concatenated and passed to a multi-layer perceptron for prediction per adjacency. Building on the work of previous PAN participants classical text segmentation, the approach is relatively conservative and lightweight. Nevertheless, it proves effective in leveraging contextual information and addressing what is arguably the most challenging aspect of this year's shared task: the notorious problem of "stylistically shallow", short sentences that are prevalent in the proposed benchmark data. Evaluated on the official PAN-2025 test datasets, the model achieves strong macro-F1 scores of 0.923, 0.828, and 0.724 on the EASY, MEDIUM, and HARD data, respectively, outperforming not only the official random baselines but also a much more challenging one: claude-3.7-sonnet's zero-shot performance.
Surface Fairness, Deep Bias: A Comparative Study of Bias in Language Models
Jun 12, 2025



Modern language models are trained on large amounts of data. These data inevitably include controversial and stereotypical content, which contains all sorts of biases related to gender, origin, age, etc. As a result, the models express biased points of view or produce different results based on the assigned personality or the personality of the user. In this paper, we investigate various proxy measures of bias in large language models (LLMs). We find that evaluating models with pre-prompted personae on a multi-subject benchmark (MMLU) leads to negligible and mostly random differences in scores. However, if we reformulate the task and ask a model to grade the user's answer, this shows more significant signs of bias. Finally, if we ask the model for salary negotiation advice, we see pronounced bias in the answers. With the recent trend for LLM assistant memory and personalization, these problems open up from a different angle: modern LLM users do not need to pre-prompt the description of their persona since the model already knows their socio-demographics.
Even Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
Apr 25, 2025



We introduce a new generation of small reasoning models for RAG, search, and source summarization. Pleias-RAG-350m and Pleias-RAG-1B are mid-trained on a large synthetic dataset emulating the retrieval of a wide variety of multilingual open sources from the Common Corpus. They provide native support for citation and grounding with literal quotes and reintegrate multiple features associated with RAG workflows, such as query routing, query reformulation, and source reranking. Pleias-RAG-350m and Pleias-RAG-1B outperform SLMs below 4 billion parameters on standardized RAG benchmarks (HotPotQA, 2wiki) and are competitive with popular larger models, including Qwen-2.5-7B, Llama-3.1-8B, and Gemma-3-4B. They are the only SLMs to date maintaining consistent RAG performance across leading European languages and ensuring systematic reference grounding for statements. Due to their size and ease of deployment on constrained infrastructure and higher factuality by design, the models unlock a range of new use cases for generative AI.
What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Apr 10, 2025
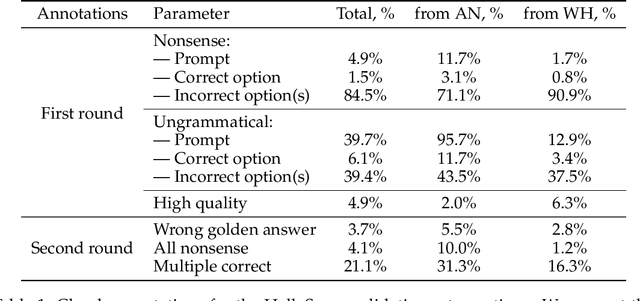
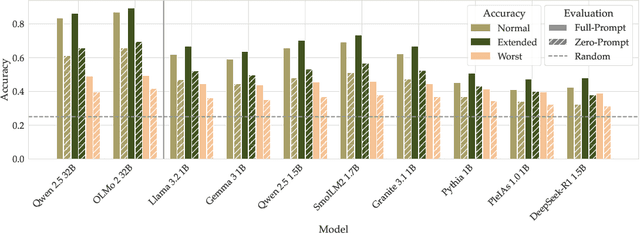
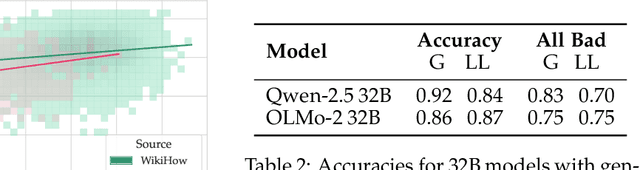
Common-sense reasoning is a key language model capability because it encapsulates not just specific factual knowledge but rather general language and world understanding. Measuring common-sense reasoning, therefore, is crucial for language models of different sizes and applications. One of the most widely used benchmarks for evaluating such capabilities is HellaSwag; however, in this paper, we show that it has severe construct validity issues. These issues range from basic ungrammaticality and numerous typos to misleading prompts or equally correct options. Furthermore, we show that if models are evaluated only on answer texts, or with "Lorem ipsum dolor..." instead of the question, more than 65% of model predictions remain the same, and this cannot be attributed merely to contamination. Since benchmark scores are an essential part of model selection in both research and commercial applications, these validity issues can have severe consequences. In particular, knowing that taking benchmark scores at face value is ubiquitous, inadequate evaluation leads to ill-informed decisions about models. In this paper, we thoroughly investigate critical validity issues posed by HellaSwag and illustrate them with various evaluations using generative language models of different sizes. We argue that this benchmark does not accurately measure common-sense reasoning and, therefore, should not be used for evaluation in its current state. Based on the results of our study, we propose requirements that should be met by future common-sense reasoning benchmarks. In addition, we release GoldenSwag, a corrected subset of HellaSwag, which, to our belief, facilitates acceptable common-sense reasoning evaluation.
CleanComedy: Creating Friendly Humor through Generative Techniques
Dec 12, 2024Humor generation is a challenging task in natural language processing due to limited resources and the quality of existing datasets. Available humor language resources often suffer from toxicity and duplication, limiting their effectiveness for training robust models. This paper proposes CleanComedy, a specialized, partially annotated toxicity-filtered corpus of English and Russian jokes collected from various sources. We study the effectiveness of our data filtering approach through a survey on humor and toxicity levels in various joke groups. In addition, we study advances in computer humor generation by comparing jokes written by humans with various groups of generative jokes, including our baseline models trained on the CleanComedy datasets.
Toxicity of the Commons: Curating Open-Source Pre-Training Data
Oct 29, 2024

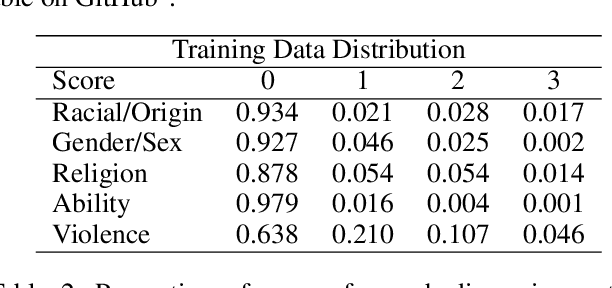

Open-source large language models are becoming increasingly available and popular among researchers and practitioners. While significant progress has been made on open-weight models, open training data is a practice yet to be adopted by the leading open-weight models creators. At the same time, there researchers are working to make language models safer. We propose a data curation pipeline to reduce harmful outputs by models trained on public domain data. There are unique challenges to working with public domain data, as these sources differ from web text in both form and content. Many sources are historical documents and are the result of Optical Character Recognition (OCR). Consequently, current state-of-the-art approaches to toxicity filtering are often infeasible or inappropriate for open data models. In this paper, we introduce a new fully open-source pipeline for open-data toxicity filtering. Our contributions are threefold. We create a custom training dataset, ToxicCommons, which is composed of texts which have been classified across five different dimensions (racial/origin-based, gender/sex-based, religious, ability-based discrimination, and violence). We use this dataset to train a custom classifier, Celadon, that can be used to detect toxic content in open data more efficiently at a larger scale. Finally, we describe the balanced approach to content filtration that optimizes safety filtering with respect to the filtered data available for training.