 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEven Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
Apr 25, 2025



We introduce a new generation of small reasoning models for RAG, search, and source summarization. Pleias-RAG-350m and Pleias-RAG-1B are mid-trained on a large synthetic dataset emulating the retrieval of a wide variety of multilingual open sources from the Common Corpus. They provide native support for citation and grounding with literal quotes and reintegrate multiple features associated with RAG workflows, such as query routing, query reformulation, and source reranking. Pleias-RAG-350m and Pleias-RAG-1B outperform SLMs below 4 billion parameters on standardized RAG benchmarks (HotPotQA, 2wiki) and are competitive with popular larger models, including Qwen-2.5-7B, Llama-3.1-8B, and Gemma-3-4B. They are the only SLMs to date maintaining consistent RAG performance across leading European languages and ensuring systematic reference grounding for statements. Due to their size and ease of deployment on constrained infrastructure and higher factuality by design, the models unlock a range of new use cases for generative AI.
What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Apr 10, 2025
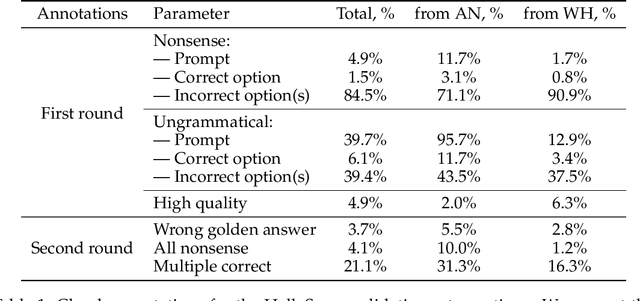
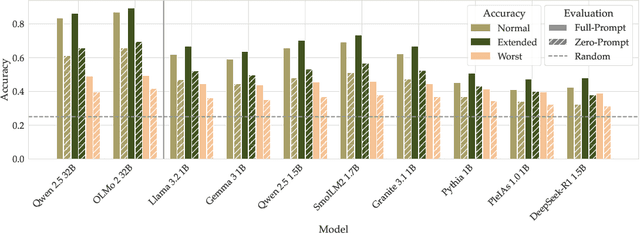
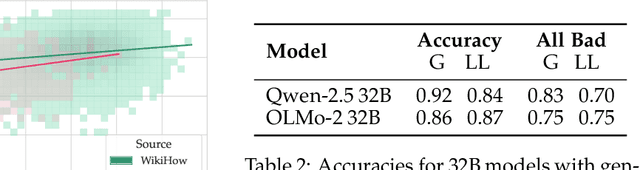
Common-sense reasoning is a key language model capability because it encapsulates not just specific factual knowledge but rather general language and world understanding. Measuring common-sense reasoning, therefore, is crucial for language models of different sizes and applications. One of the most widely used benchmarks for evaluating such capabilities is HellaSwag; however, in this paper, we show that it has severe construct validity issues. These issues range from basic ungrammaticality and numerous typos to misleading prompts or equally correct options. Furthermore, we show that if models are evaluated only on answer texts, or with "Lorem ipsum dolor..." instead of the question, more than 65% of model predictions remain the same, and this cannot be attributed merely to contamination. Since benchmark scores are an essential part of model selection in both research and commercial applications, these validity issues can have severe consequences. In particular, knowing that taking benchmark scores at face value is ubiquitous, inadequate evaluation leads to ill-informed decisions about models. In this paper, we thoroughly investigate critical validity issues posed by HellaSwag and illustrate them with various evaluations using generative language models of different sizes. We argue that this benchmark does not accurately measure common-sense reasoning and, therefore, should not be used for evaluation in its current state. Based on the results of our study, we propose requirements that should be met by future common-sense reasoning benchmarks. In addition, we release GoldenSwag, a corrected subset of HellaSwag, which, to our belief, facilitates acceptable common-sense reasoning evaluation.