 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel in Distress: Sentiment Analysis on French Synthetic Social Media
Apr 20, 2026Automated analysis of customer feedback on social media is hindered by three challenges: the high cost of annotated training data, the scarcity of evaluation sets, especially in multilingual settings, and privacy concerns that prevent data sharing and reproducibility. We address these issues by developing a generalizable synthetic data generation pipeline applied to a case study on customer distress detection in French public transportation. Our approach utilizes backtranslation with fine-tuned models to generate 1.7 million synthetic tweets from a small seed corpus, complemented by synthetic reasoning traces. We train 600M-parameter reasoners with English and French reasoning that achieve 77-79% accuracy on human-annotated evaluation data, matching or exceeding SOTA proprietary LLMs and specialized encoders. Beyond reducing annotation costs, our pipeline preserves privacy by eliminating the exposure of sensitive user data. Our methodology can be adopted for other use cases and languages.
From Show Programmes to Data: Designing a Workflow to Make Performing Arts Ephemera Accessible Through Language Models
Dec 08, 2025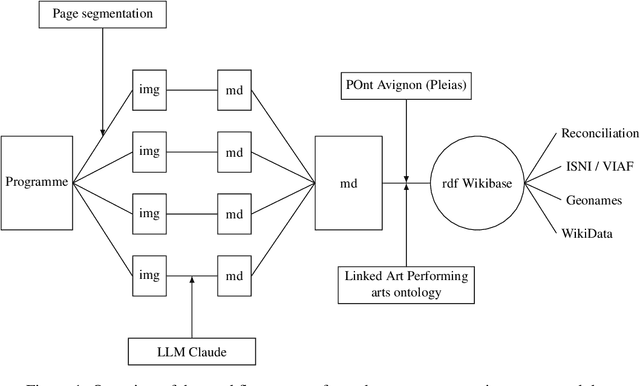


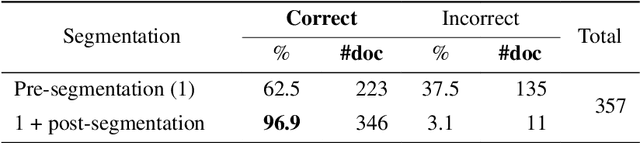
Many heritage institutions hold extensive collections of theatre programmes, which remain largely underused due to their complex layouts and lack of structured metadata. In this paper, we present a workflow for transforming such documents into structured data using a combination of multimodal large language models (LLMs), an ontology-based reasoning model, and a custom extension of the Linked Art framework. We show how vision-language models can accurately parse and transcribe born-digital and digitised programmes, achieving over 98% of correct extraction. To overcome the challenges of semantic annotation, we train a reasoning model (POntAvignon) using reinforcement learning with both formal and semantic rewards. This approach enables automated RDF triple generation and supports alignment with existing knowledge graphs. Through a case study based on the Festival d'Avignon corpus, we demonstrate the potential for large-scale, ontology-driven analysis of performing arts data. Our results open new possibilities for interoperable, explainable, and sustainable computational theatre historiography.
Even Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
Apr 25, 2025



We introduce a new generation of small reasoning models for RAG, search, and source summarization. Pleias-RAG-350m and Pleias-RAG-1B are mid-trained on a large synthetic dataset emulating the retrieval of a wide variety of multilingual open sources from the Common Corpus. They provide native support for citation and grounding with literal quotes and reintegrate multiple features associated with RAG workflows, such as query routing, query reformulation, and source reranking. Pleias-RAG-350m and Pleias-RAG-1B outperform SLMs below 4 billion parameters on standardized RAG benchmarks (HotPotQA, 2wiki) and are competitive with popular larger models, including Qwen-2.5-7B, Llama-3.1-8B, and Gemma-3-4B. They are the only SLMs to date maintaining consistent RAG performance across leading European languages and ensuring systematic reference grounding for statements. Due to their size and ease of deployment on constrained infrastructure and higher factuality by design, the models unlock a range of new use cases for generative AI.
What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Apr 10, 2025
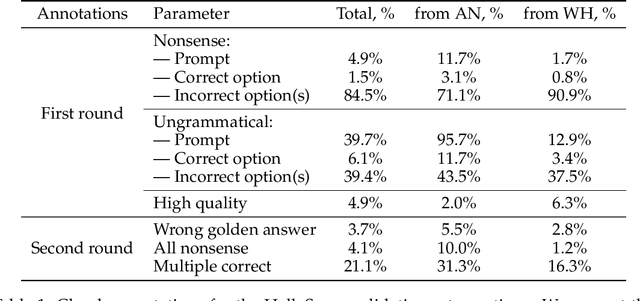
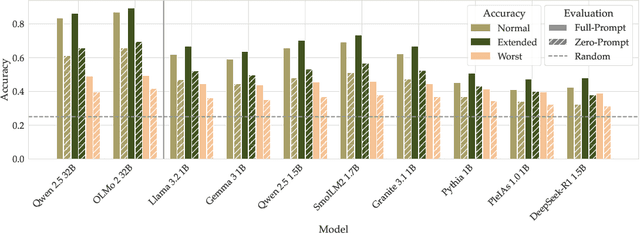
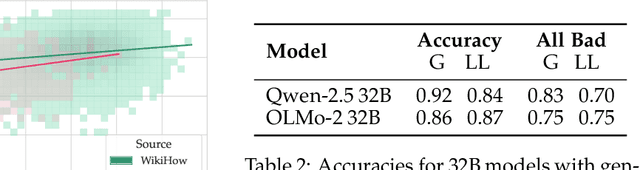
Common-sense reasoning is a key language model capability because it encapsulates not just specific factual knowledge but rather general language and world understanding. Measuring common-sense reasoning, therefore, is crucial for language models of different sizes and applications. One of the most widely used benchmarks for evaluating such capabilities is HellaSwag; however, in this paper, we show that it has severe construct validity issues. These issues range from basic ungrammaticality and numerous typos to misleading prompts or equally correct options. Furthermore, we show that if models are evaluated only on answer texts, or with "Lorem ipsum dolor..." instead of the question, more than 65% of model predictions remain the same, and this cannot be attributed merely to contamination. Since benchmark scores are an essential part of model selection in both research and commercial applications, these validity issues can have severe consequences. In particular, knowing that taking benchmark scores at face value is ubiquitous, inadequate evaluation leads to ill-informed decisions about models. In this paper, we thoroughly investigate critical validity issues posed by HellaSwag and illustrate them with various evaluations using generative language models of different sizes. We argue that this benchmark does not accurately measure common-sense reasoning and, therefore, should not be used for evaluation in its current state. Based on the results of our study, we propose requirements that should be met by future common-sense reasoning benchmarks. In addition, we release GoldenSwag, a corrected subset of HellaSwag, which, to our belief, facilitates acceptable common-sense reasoning evaluation.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
Toxicity of the Commons: Curating Open-Source Pre-Training Data
Oct 29, 2024

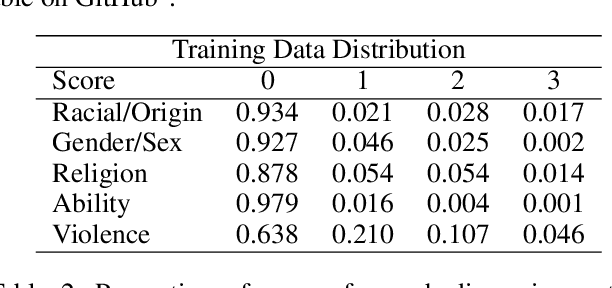

Open-source large language models are becoming increasingly available and popular among researchers and practitioners. While significant progress has been made on open-weight models, open training data is a practice yet to be adopted by the leading open-weight models creators. At the same time, there researchers are working to make language models safer. We propose a data curation pipeline to reduce harmful outputs by models trained on public domain data. There are unique challenges to working with public domain data, as these sources differ from web text in both form and content. Many sources are historical documents and are the result of Optical Character Recognition (OCR). Consequently, current state-of-the-art approaches to toxicity filtering are often infeasible or inappropriate for open data models. In this paper, we introduce a new fully open-source pipeline for open-data toxicity filtering. Our contributions are threefold. We create a custom training dataset, ToxicCommons, which is composed of texts which have been classified across five different dimensions (racial/origin-based, gender/sex-based, religious, ability-based discrimination, and violence). We use this dataset to train a custom classifier, Celadon, that can be used to detect toxic content in open data more efficiently at a larger scale. Finally, we describe the balanced approach to content filtration that optimizes safety filtering with respect to the filtered data available for training.