 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Don't Just "Fix it in Post": A Science of AI Must Study Training Dynamics
Jun 03, 2026What would it mean to have a scientific understanding of AI? Models are not static objects: they are snapshots of time-evolving processes shaped by data, objectives, architectures, and optimization dynamics. Yet much of AI research treats models as fixed artifacts, analyzing behaviors after training rather than asking why they emerge. This position paper argues that a science of AI must move beyond post-hoc fixes and study the training dynamics that produce model behavior. Such a science should support progressively stronger forms of understanding: predicting outcomes from early training signals, intervening when trajectories go wrong, and ultimately designing training procedures that more reliably produce desired properties. Scaling laws have made prediction routine for loss; the challenge is extending this success to capabilities, biases, robustness, and safety-relevant behaviors. We articulate requirements for such theories grounded in the history and philosophy of science, examine progress in mechanistic interpretability, fairness, memorization, and simplicity bias, and identify concrete open problems.
Weight Tying Biases Token Embeddings Towards the Output Space
Mar 27, 2026Weight tying, i.e. sharing parameters between input and output embedding matrices, is common practice in language model design, yet its impact on the learned embedding space remains poorly understood. In this paper, we show that tied embedding matrices align more closely with output (unembedding) matrices than with input embeddings of comparable untied models, indicating that the shared matrix is shaped primarily for output prediction rather than input representation. This unembedding bias arises because output gradients dominate early in training. Using tuned lens analysis, we show this negatively affects early-layer computations, which contribute less effectively to the residual stream. Scaling input gradients during training reduces this bias, providing causal evidence for the role of gradient imbalance. This is mechanistic evidence that weight tying optimizes the embedding matrix for output prediction, compromising its role in input representation. These results help explain why weight tying can harm performance at scale and have implications for training smaller LLMs, where the embedding matrix contributes substantially to total parameter count.
How Open Must Language Models be to Enable Reliable Scientific Inference?
Mar 27, 2026How does the extent to which a model is open or closed impact the scientific inferences that can be drawn from research that involves it? In this paper, we analyze how restrictions on information about model construction and deployment threaten reliable inference. We argue that current closed models are generally ill-suited for scientific purposes, with some notable exceptions, and discuss ways in which the issues they present to reliable inference can be resolved or mitigated. We recommend that when models are used in research, potential threats to inference should be systematically identified along with the steps taken to mitigate them, and that specific justifications for model selection should be provided.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Evaluating Morphological Alignment of Tokenizers in 70 Languages
Jul 08, 2025While tokenization is a key step in language modeling, with effects on model training and performance, it remains unclear how to effectively evaluate tokenizer quality. One proposed dimension of tokenizer quality is the extent to which tokenizers preserve linguistically meaningful subwords, aligning token boundaries with morphological boundaries within a word. We expand MorphScore (Arnett & Bergen, 2025), which previously covered 22 languages, to support a total of 70 languages. The updated MorphScore offers more flexibility in evaluation and addresses some of the limitations of the original version. We then correlate our alignment scores with downstream task performance for five pre-trained languages models on seven tasks, with at least one task in each of the languages in our sample. We find that morphological alignment does not explain very much variance in model performance, suggesting that morphological alignment alone does not measure dimensions of tokenization quality relevant to model performance.
BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization
May 30, 2025Byte Pair Encoding (BPE) tokenizers, widely used in Large Language Models, face challenges in multilingual settings, including penalization of non-Western scripts and the creation of tokens with partial UTF-8 sequences. Pretokenization, often reliant on complex regular expressions, can also introduce fragility and unexpected edge cases. We propose SCRIPT (Script Category Representation in PreTokenization), a novel encoding scheme that bypasses UTF-8 byte conversion by using initial tokens based on Unicode script and category properties. This approach enables a simple, rule-based pretokenization strategy that respects script boundaries, offering a robust alternative to pretokenization strategies based on regular expressions. We also introduce and validate a constrained BPE merging strategy that enforces character integrity, applicable to both SCRIPT-BPE and byte-based BPE. Our experiments demonstrate that SCRIPT-BPE achieves competitive compression while eliminating encoding-based penalties for non-Latin-script languages.
On the Acquisition of Shared Grammatical Representations in Bilingual Language Models
Mar 05, 2025



While crosslingual transfer is crucial to contemporary language models' multilingual capabilities, how it occurs is not well understood. In this paper, we ask what happens to a monolingual language model when it begins to be trained on a second language. Specifically, we train small bilingual models for which we control the amount of data for each language and the order of language exposure. To find evidence of shared multilingual representations, we turn to structural priming, a method used to study grammatical representations in humans. We first replicate previous crosslingual structural priming results and find that after controlling for training data quantity and language exposure, there are asymmetrical effects across language pairs and directions. We argue that this asymmetry may shape hypotheses about human structural priming effects. We also find that structural priming effects are less robust for less similar language pairs, highlighting potential limitations of crosslingual transfer learning and shared representations for typologically diverse languages.
Why do language models perform worse for morphologically complex languages?
Nov 21, 2024Language models perform differently across languages. It has been previously suggested that morphological typology may explain some of this variability (Cotterell et al., 2018). We replicate previous analyses and find additional new evidence for a performance gap between agglutinative and fusional languages, where fusional languages, such as English, tend to have better language modeling performance than morphologically more complex languages like Turkish. We then propose and test three possible causes for this performance gap: morphological alignment of tokenizers, tokenization quality, and disparities in dataset sizes and measurement. To test the morphological alignment hypothesis, we present MorphScore, a tokenizer evaluation metric, and supporting datasets for 22 languages. We find some evidence that tokenization quality explains the performance gap, but none for the role of morphological alignment. Instead we find that the performance gap is most reduced when training datasets are of equivalent size across language types, but only when scaled according to the so-called "byte-premium" -- the different encoding efficiencies of different languages and orthographies. These results suggest that no language is harder or easier for a language model to learn on the basis of its morphological typology. Differences in performance can be attributed to disparities in dataset size. These results bear on ongoing efforts to improve performance for low-performing and under-resourced languages.
Toxicity of the Commons: Curating Open-Source Pre-Training Data
Oct 29, 2024

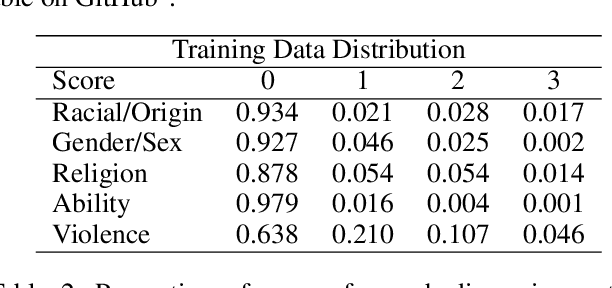

Open-source large language models are becoming increasingly available and popular among researchers and practitioners. While significant progress has been made on open-weight models, open training data is a practice yet to be adopted by the leading open-weight models creators. At the same time, there researchers are working to make language models safer. We propose a data curation pipeline to reduce harmful outputs by models trained on public domain data. There are unique challenges to working with public domain data, as these sources differ from web text in both form and content. Many sources are historical documents and are the result of Optical Character Recognition (OCR). Consequently, current state-of-the-art approaches to toxicity filtering are often infeasible or inappropriate for open data models. In this paper, we introduce a new fully open-source pipeline for open-data toxicity filtering. Our contributions are threefold. We create a custom training dataset, ToxicCommons, which is composed of texts which have been classified across five different dimensions (racial/origin-based, gender/sex-based, religious, ability-based discrimination, and violence). We use this dataset to train a custom classifier, Celadon, that can be used to detect toxic content in open data more efficiently at a larger scale. Finally, we describe the balanced approach to content filtration that optimizes safety filtering with respect to the filtered data available for training.
BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Sep 06, 2024Language models can largely benefit from efficient tokenization. However, they still mostly utilize the classical BPE algorithm, a simple and reliable method. This has been shown to cause such issues as under-trained tokens and sub-optimal compression that may affect the downstream performance. We introduce Picky BPE, a modified BPE algorithm that carries out vocabulary refinement during tokenizer training. Our method improves vocabulary efficiency, eliminates under-trained tokens, and does not compromise text compression. Our experiments show that our method does not reduce the downstream performance, and in several cases improves it.