 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Statistics and False Belief Reasoning: Evidence from 41 Open-Weight LMs
Feb 17, 2026Research on mental state reasoning in language models (LMs) has the potential to inform theories of human social cognition--such as the theory that mental state reasoning emerges in part from language exposure--and our understanding of LMs themselves. Yet much published work on LMs relies on a relatively small sample of closed-source LMs, limiting our ability to rigorously test psychological theories and evaluate LM capacities. Here, we replicate and extend published work on the false belief task by assessing LM mental state reasoning behavior across 41 open-weight models (from distinct model families). We find sensitivity to implied knowledge states in 34% of the LMs tested; however, consistent with prior work, none fully ``explain away'' the effect in humans. Larger LMs show increased sensitivity and also exhibit higher psychometric predictive power. Finally, we use LM behavior to generate and test a novel hypothesis about human cognition: both humans and LMs show a bias towards attributing false beliefs when knowledge states are cued using a non-factive verb (``John thinks...'') than when cued indirectly (``John looks in the...''). Unlike the primary effect of knowledge states, where human sensitivity exceeds that of LMs, the magnitude of the human knowledge cue effect falls squarely within the distribution of LM effect sizes-suggesting that distributional statistics of language can in principle account for the latter but not the former in humans. These results demonstrate the value of using larger samples of open-weight LMs to test theories of human cognition and evaluate LM capacities.
Capacity Constraints and the Multilingual Penalty for Lexical Disambiguation
Feb 04, 2026Multilingual language models (LMs) sometimes under-perform their monolingual counterparts, possibly due to capacity limitations. We quantify this ``multilingual penalty'' for lexical disambiguation--a task requiring precise semantic representations and contextualization mechanisms--using controlled datasets of human relatedness judgments for ambiguous words in both English and Spanish. Comparing monolingual and multilingual LMs from the same families, we find consistently reduced performance in multilingual LMs. We then explore three potential capacity constraints: representational (reduced embedding isotropy), attentional (reduced attention to disambiguating cues), and vocabulary-related (increased multi-token segmentation). Multilingual LMs show some evidence of all three limitations; moreover, these factors statistically account for the variance formerly attributed to a model's multilingual status. These findings suggest both that multilingual LMs do suffer from multiple capacity constraints, and that these constraints correlate with reduced disambiguation performance.
Measuring and Modifying the Readability of English Texts with GPT-4
Oct 17, 2024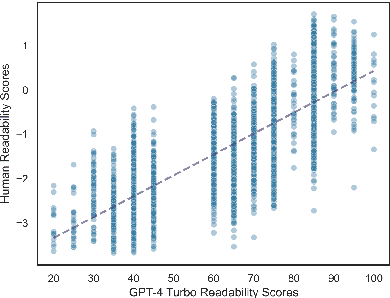
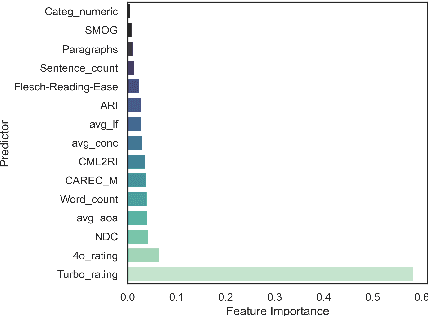
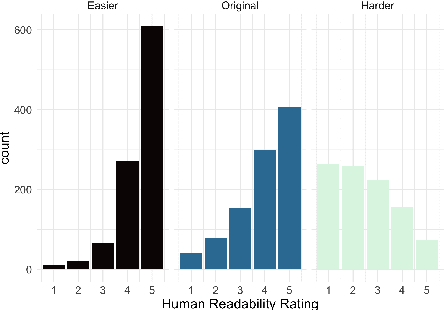
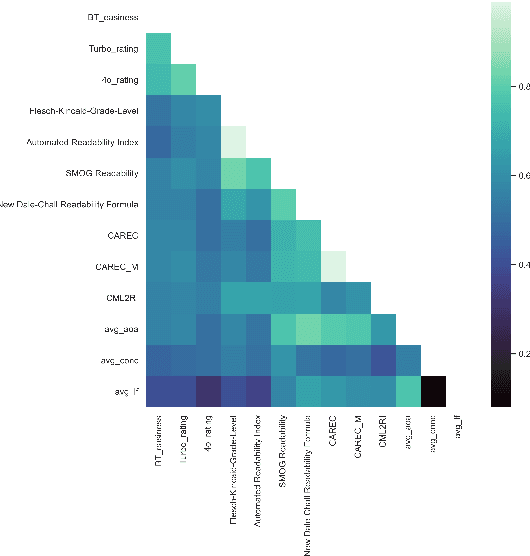
The success of Large Language Models (LLMs) in other domains has raised the question of whether LLMs can reliably assess and manipulate the readability of text. We approach this question empirically. First, using a published corpus of 4,724 English text excerpts, we find that readability estimates produced ``zero-shot'' from GPT-4 Turbo and GPT-4o mini exhibit relatively high correlation with human judgments (r = 0.76 and r = 0.74, respectively), out-performing estimates derived from traditional readability formulas and various psycholinguistic indices. Then, in a pre-registered human experiment (N = 59), we ask whether Turbo can reliably make text easier or harder to read. We find evidence to support this hypothesis, though considerable variance in human judgments remains unexplained. We conclude by discussing the limitations of this approach, including limited scope, as well as the validity of the ``readability'' construct and its dependence on context, audience, and goal.
Bidirectional Transformer Representations of (Spanish) Ambiguous Words in Context: A New Lexical Resource and Empirical Analysis
Jun 20, 2024Lexical ambiguity -- where a single wordform takes on distinct, context-dependent meanings -- serves as a useful tool to compare across different large language models' (LLMs') ability to form distinct, contextualized representations of the same stimulus. Few studies have systematically compared LLMs' contextualized word embeddings for languages beyond English. Here, we evaluate multiple bidirectional transformers' (BERTs') semantic representations of Spanish ambiguous nouns in context. We develop a novel dataset of minimal-pair sentences evoking the same or different sense for a target ambiguous noun. In a pre-registered study, we collect contextualized human relatedness judgments for each sentence pair. We find that various BERT-based LLMs' contextualized semantic representations capture some variance in human judgments but fall short of the human benchmark, and for Spanish -- unlike English -- model scale is uncorrelated with performance. We also identify stereotyped trajectories of target noun disambiguation as a proportion of traversal through a given LLM family's architecture, which we partially replicate in English. We contribute (1) a dataset of controlled, Spanish sentence stimuli with human relatedness norms, and (2) to our evolving understanding of the impact that LLM specification (architectures, training protocols) exerts on contextualized embeddings.
Different Tokenization Schemes Lead to Comparable Performance in Spanish Number Agreement
Mar 20, 2024
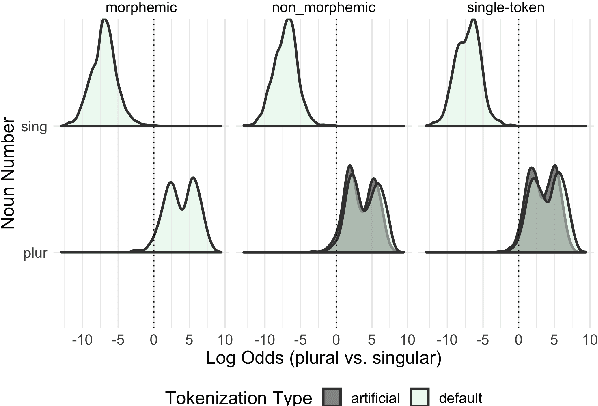
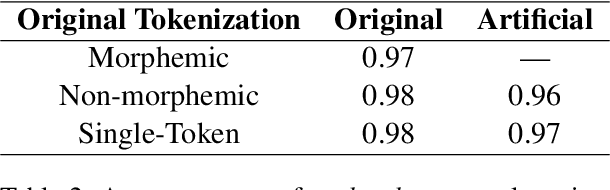
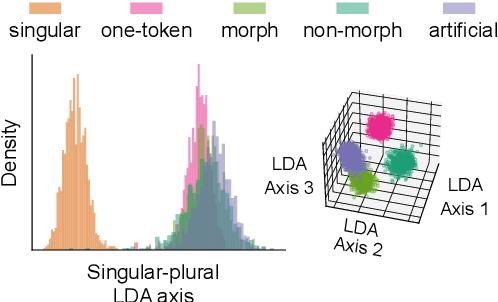
The relationship between language model tokenization and performance is an open area of research. Here, we investigate how different tokenization schemes impact number agreement in Spanish plurals. We find that morphologically-aligned tokenization performs similarly to other tokenization schemes, even when induced artificially for words that would not be tokenized that way during training. We then present exploratory analyses demonstrating that language model embeddings for different plural tokenizations have similar distributions along the embedding space axis that maximally distinguishes singular and plural nouns. Our results suggest that morphologically-aligned tokenization is a viable tokenization approach, and existing models already generalize some morphological patterns to new items. However, our results indicate that morphological tokenization is not strictly required for performance.