 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Open Must Language Models be to Enable Reliable Scientific Inference?
Mar 27, 2026How does the extent to which a model is open or closed impact the scientific inferences that can be drawn from research that involves it? In this paper, we analyze how restrictions on information about model construction and deployment threaten reliable inference. We argue that current closed models are generally ill-suited for scientific purposes, with some notable exceptions, and discuss ways in which the issues they present to reliable inference can be resolved or mitigated. We recommend that when models are used in research, potential threats to inference should be systematically identified along with the steps taken to mitigate them, and that specific justifications for model selection should be provided.
Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models
Apr 21, 2025In Transformer language models, activation vectors transform from current token embeddings to next token predictions as they pass through the model. To isolate a minimal form of this transformation, we identify language model subnetworks that make bigram predictions, naive next token predictions based only on the current token. We find that bigram subnetworks can be found in fully trained language models up to 1B parameters, and these subnetworks are critical for model performance even when they consist of less than 0.2% of model parameters. Bigram subnetworks are concentrated in the first Transformer MLP layer, and they overlap significantly with subnetworks trained to optimally prune a given model. Mechanistically, the bigram subnetworks often recreate a pattern from the full models where the first layer induces a sharp change that aligns activations with next token predictions rather than current token representations. Our results demonstrate that bigram subnetworks comprise a minimal subset of parameters that are both necessary and sufficient for basic next token predictions in language models, and they help drive the transformation from current to next token activations in the residual stream. These subnetworks can lay a foundation for studying language model circuits by building up from a minimal circuit rather than the traditional approach of ablating circuits from a full model.
On the Acquisition of Shared Grammatical Representations in Bilingual Language Models
Mar 05, 2025



While crosslingual transfer is crucial to contemporary language models' multilingual capabilities, how it occurs is not well understood. In this paper, we ask what happens to a monolingual language model when it begins to be trained on a second language. Specifically, we train small bilingual models for which we control the amount of data for each language and the order of language exposure. To find evidence of shared multilingual representations, we turn to structural priming, a method used to study grammatical representations in humans. We first replicate previous crosslingual structural priming results and find that after controlling for training data quantity and language exposure, there are asymmetrical effects across language pairs and directions. We argue that this asymmetry may shape hypotheses about human structural priming effects. We also find that structural priming effects are less robust for less similar language pairs, highlighting potential limitations of crosslingual transfer learning and shared representations for typologically diverse languages.
Scalable Influence and Fact Tracing for Large Language Model Pretraining
Oct 22, 2024Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names.
Goldfish: Monolingual Language Models for 350 Languages
Aug 19, 2024For many low-resource languages, the only available language models are large multilingual models trained on many languages simultaneously. However, using FLORES perplexity as a metric, we find that these models perform worse than bigrams for many languages (e.g. 24% of languages in XGLM 4.5B; 43% in BLOOM 7.1B). To facilitate research that focuses on low-resource languages, we pre-train and release Goldfish, a suite of monolingual autoregressive Transformer language models up to 125M parameters for 350 languages. The Goldfish reach lower FLORES perplexities than BLOOM, XGLM, and MaLA-500 on 98 of 204 FLORES languages, despite each Goldfish model being over 10x smaller. However, the Goldfish significantly underperform larger multilingual models on reasoning benchmarks, suggesting that for low-resource languages, multilinguality primarily improves general reasoning abilities rather than basic text generation. We release models trained on 5MB (350 languages), 10MB (288 languages), 100MB (166 languages), and 1GB (83 languages) of text data where available. The Goldfish models are available as baselines, fine-tuning sources, or augmentations to existing models in low-resource NLP research, and they are further useful for crosslinguistic studies requiring maximally comparable models across languages.
Different Tokenization Schemes Lead to Comparable Performance in Spanish Number Agreement
Mar 20, 2024
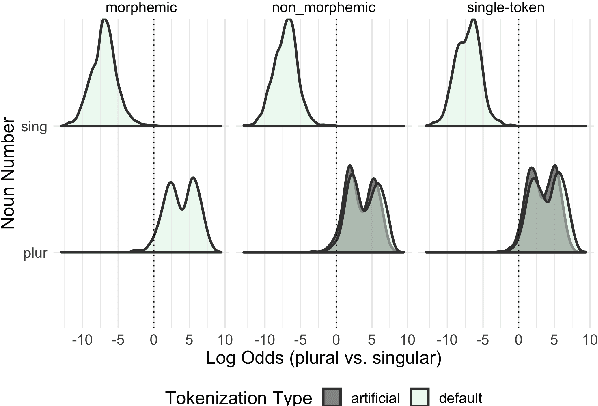
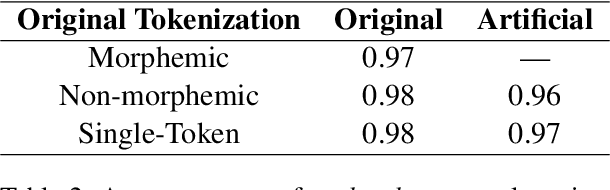
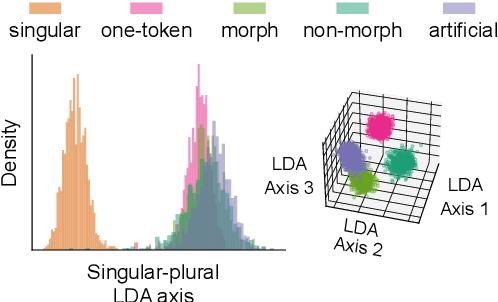
The relationship between language model tokenization and performance is an open area of research. Here, we investigate how different tokenization schemes impact number agreement in Spanish plurals. We find that morphologically-aligned tokenization performs similarly to other tokenization schemes, even when induced artificially for words that would not be tokenized that way during training. We then present exploratory analyses demonstrating that language model embeddings for different plural tokenizations have similar distributions along the embedding space axis that maximally distinguishes singular and plural nouns. Our results suggest that morphologically-aligned tokenization is a viable tokenization approach, and existing models already generalize some morphological patterns to new items. However, our results indicate that morphological tokenization is not strictly required for performance.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024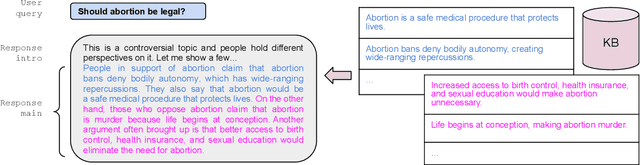



We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.
A Bit of a Problem: Measurement Disparities in Dataset Sizes Across Languages
Mar 01, 2024



How should text dataset sizes be compared across languages? Even for content-matched (parallel) corpora, UTF-8 encoded text can require a dramatically different number of bytes for different languages. In our work, we define the byte premium between two languages as the ratio of bytes used to encode content-matched text in those languages. We compute byte premiums for 1155 languages, and we use linear regressions to estimate byte premiums for other languages. We release a tool to obtain byte premiums for any two languages, enabling comparisons of dataset sizes across languages for more equitable multilingual model development and data practices.
Structural Priming Demonstrates Abstract Grammatical Representations in Multilingual Language Models
Nov 15, 2023



Abstract grammatical knowledge - of parts of speech and grammatical patterns - is key to the capacity for linguistic generalization in humans. But how abstract is grammatical knowledge in large language models? In the human literature, compelling evidence for grammatical abstraction comes from structural priming. A sentence that shares the same grammatical structure as a preceding sentence is processed and produced more readily. Because confounds exist when using stimuli in a single language, evidence of abstraction is even more compelling from crosslingual structural priming, where use of a syntactic structure in one language primes an analogous structure in another language. We measure crosslingual structural priming in large language models, comparing model behavior to human experimental results from eight crosslingual experiments covering six languages, and four monolingual structural priming experiments in three non-English languages. We find evidence for abstract monolingual and crosslingual grammatical representations in the models that function similarly to those found in humans. These results demonstrate that grammatical representations in multilingual language models are not only similar across languages, but they can causally influence text produced in different languages.
When Is Multilinguality a Curse? Language Modeling for 250 High- and Low-Resource Languages
Nov 15, 2023



Multilingual language models are widely used to extend NLP systems to low-resource languages. However, concrete evidence for the effects of multilinguality on language modeling performance in individual languages remains scarce. Here, we pre-train over 10,000 monolingual and multilingual language models for over 250 languages, including multiple language families that are under-studied in NLP. We assess how language modeling performance in each language varies as a function of (1) monolingual dataset size, (2) added multilingual dataset size, (3) linguistic similarity of the added languages, and (4) model size (up to 45M parameters). We find that in moderation, adding multilingual data improves low-resource language modeling performance, similar to increasing low-resource dataset sizes by up to 33%. Improvements depend on the syntactic similarity of the added multilingual data, with marginal additional effects of vocabulary overlap. However, high-resource languages consistently perform worse in multilingual pre-training scenarios. As dataset sizes increase, adding multilingual data begins to hurt performance for both low-resource and high-resource languages, likely due to limited model capacity (the "curse of multilinguality"). These results suggest that massively multilingual pre-training may not be optimal for any languages involved, but that more targeted models can significantly improve performance.