 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Open Must Language Models be to Enable Reliable Scientific Inference?
Mar 27, 2026How does the extent to which a model is open or closed impact the scientific inferences that can be drawn from research that involves it? In this paper, we analyze how restrictions on information about model construction and deployment threaten reliable inference. We argue that current closed models are generally ill-suited for scientific purposes, with some notable exceptions, and discuss ways in which the issues they present to reliable inference can be resolved or mitigated. We recommend that when models are used in research, potential threats to inference should be systematically identified along with the steps taken to mitigate them, and that specific justifications for model selection should be provided.
EVOKE: Emotion Vocabulary Of Korean and English
Feb 11, 2026This paper introduces EVOKE, a parallel dataset of emotion vocabulary in English and Korean. The dataset offers comprehensive coverage of emotion words in each language, in addition to many-to-many translations between words in the two languages and identification of language-specific emotion words. The dataset contains 1,427 Korean words and 1,399 English words, and we systematically annotate 819 Korean and 924 English adjectives and verbs. We also annotate multiple meanings of each word and their relationships, identifying polysemous emotion words and emotion-related metaphors. The dataset is, to our knowledge, the most comprehensive, systematic, and theory-agnostic dataset of emotion words in both Korean and English to date. It can serve as a practical tool for emotion science, psycholinguistics, computational linguistics, and natural language processing, allowing researchers to adopt different views on the resource reflecting their needs and theoretical perspectives. The dataset is publicly available at https://github.com/yoonwonj/EVOKE.
LLMs and people both learn to form conventions -- just not with each other
Feb 09, 2026Humans align to one another in conversation -- adopting shared conventions that ease communication. We test whether LLMs form the same kinds of conventions in a multimodal communication game. Both humans and LLMs display evidence of convention-formation (increasing the accuracy and consistency of their turns while decreasing their length) when communicating in same-type dyads (humans with humans, AI with AI). However, heterogenous human-AI pairs fail -- suggesting differences in communicative tendencies. In Experiment 2, we ask whether LLMs can be induced to behave more like human conversants, by prompting them to produce superficially humanlike behavior. While the length of their messages matches that of human pairs, accuracy and lexical overlap in human-LLM pairs continues to lag behind that of both human-human and AI-AI pairs. These results suggest that conversational alignment requires more than just the ability to mimic previous interactions, but also shared interpretative biases toward the meanings that are conveyed.
Not quite Sherlock Holmes: Language model predictions do not reliably differentiate impossible from improbable events
Jun 07, 2025

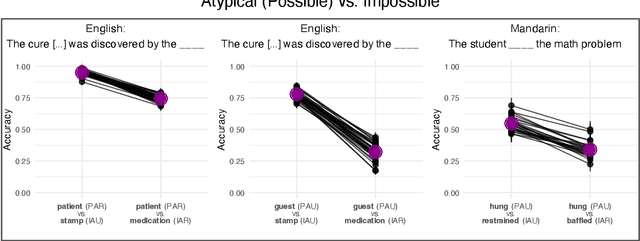

Can language models reliably predict that possible events are more likely than merely improbable ones? By teasing apart possibility, typicality, and contextual relatedness, we show that despite the results of previous work, language models' ability to do this is far from robust. In fact, under certain conditions, all models tested - including Llama 3, Gemma 2, and Mistral NeMo - perform at worse-than-chance level, assigning higher probabilities to impossible sentences such as 'the car was given a parking ticket by the brake' than to merely unlikely sentences such as 'the car was given a parking ticket by the explorer'.
Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models
Apr 21, 2025In Transformer language models, activation vectors transform from current token embeddings to next token predictions as they pass through the model. To isolate a minimal form of this transformation, we identify language model subnetworks that make bigram predictions, naive next token predictions based only on the current token. We find that bigram subnetworks can be found in fully trained language models up to 1B parameters, and these subnetworks are critical for model performance even when they consist of less than 0.2% of model parameters. Bigram subnetworks are concentrated in the first Transformer MLP layer, and they overlap significantly with subnetworks trained to optimally prune a given model. Mechanistically, the bigram subnetworks often recreate a pattern from the full models where the first layer induces a sharp change that aligns activations with next token predictions rather than current token representations. Our results demonstrate that bigram subnetworks comprise a minimal subset of parameters that are both necessary and sufficient for basic next token predictions in language models, and they help drive the transformation from current to next token activations in the residual stream. These subnetworks can lay a foundation for studying language model circuits by building up from a minimal circuit rather than the traditional approach of ablating circuits from a full model.
Do Large Language Models Exhibit Spontaneous Rational Deception?
Mar 31, 2025Large Language Models (LLMs) are effective at deceiving, when prompted to do so. But under what conditions do they deceive spontaneously? Models that demonstrate better performance on reasoning tasks are also better at prompted deception. Do they also increasingly deceive spontaneously in situations where it could be considered rational to do so? This study evaluates spontaneous deception produced by LLMs in a preregistered experimental protocol using tools from signaling theory. A range of proprietary closed-source and open-source LLMs are evaluated using modified 2x2 games (in the style of Prisoner's Dilemma) augmented with a phase in which they can freely communicate to the other agent using unconstrained language. This setup creates an opportunity to deceive, in conditions that vary in how useful deception might be to an agent's rational self-interest. The results indicate that 1) all tested LLMs spontaneously misrepresent their actions in at least some conditions, 2) they are generally more likely to do so in situations in which deception would benefit them, and 3) models exhibiting better reasoning capacity overall tend to deceive at higher rates. Taken together, these results suggest a tradeoff between LLM reasoning capability and honesty. They also provide evidence of reasoning-like behavior in LLMs from a novel experimental configuration. Finally, they reveal certain contextual factors that affect whether LLMs will deceive or not. We discuss consequences for autonomous, human-facing systems driven by LLMs both now and as their reasoning capabilities continue to improve.
Large Language Models Pass the Turing Test
Mar 31, 2025We evaluated 4 systems (ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5) in two randomised, controlled, and pre-registered Turing tests on independent populations. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a humanlike persona, GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant. LLaMa-3.1, with the same prompt, was judged to be the human 56% of the time -- not significantly more or less often than the humans they were being compared to -- while baseline models (ELIZA and GPT-4o) achieved win rates significantly below chance (23% and 21% respectively). The results constitute the first empirical evidence that any artificial system passes a standard three-party Turing test. The results have implications for debates about what kind of intelligence is exhibited by Large Language Models (LLMs), and the social and economic impacts these systems are likely to have.
On the Acquisition of Shared Grammatical Representations in Bilingual Language Models
Mar 05, 2025



While crosslingual transfer is crucial to contemporary language models' multilingual capabilities, how it occurs is not well understood. In this paper, we ask what happens to a monolingual language model when it begins to be trained on a second language. Specifically, we train small bilingual models for which we control the amount of data for each language and the order of language exposure. To find evidence of shared multilingual representations, we turn to structural priming, a method used to study grammatical representations in humans. We first replicate previous crosslingual structural priming results and find that after controlling for training data quantity and language exposure, there are asymmetrical effects across language pairs and directions. We argue that this asymmetry may shape hypotheses about human structural priming effects. We also find that structural priming effects are less robust for less similar language pairs, highlighting potential limitations of crosslingual transfer learning and shared representations for typologically diverse languages.
Lies, Damned Lies, and Distributional Language Statistics: Persuasion and Deception with Large Language Models
Dec 22, 2024Large Language Models (LLMs) can generate content that is as persuasive as human-written text and appear capable of selectively producing deceptive outputs. These capabilities raise concerns about potential misuse and unintended consequences as these systems become more widely deployed. This review synthesizes recent empirical work examining LLMs' capacity and proclivity for persuasion and deception, analyzes theoretical risks that could arise from these capabilities, and evaluates proposed mitigations. While current persuasive effects are relatively small, various mechanisms could increase their impact, including fine-tuning, multimodality, and social factors. We outline key open questions for future research, including how persuasive AI systems might become, whether truth enjoys an inherent advantage over falsehoods, and how effective different mitigation strategies may be in practice.
Why do language models perform worse for morphologically complex languages?
Nov 21, 2024Language models perform differently across languages. It has been previously suggested that morphological typology may explain some of this variability (Cotterell et al., 2018). We replicate previous analyses and find additional new evidence for a performance gap between agglutinative and fusional languages, where fusional languages, such as English, tend to have better language modeling performance than morphologically more complex languages like Turkish. We then propose and test three possible causes for this performance gap: morphological alignment of tokenizers, tokenization quality, and disparities in dataset sizes and measurement. To test the morphological alignment hypothesis, we present MorphScore, a tokenizer evaluation metric, and supporting datasets for 22 languages. We find some evidence that tokenization quality explains the performance gap, but none for the role of morphological alignment. Instead we find that the performance gap is most reduced when training datasets are of equivalent size across language types, but only when scaled according to the so-called "byte-premium" -- the different encoding efficiencies of different languages and orthographies. These results suggest that no language is harder or easier for a language model to learn on the basis of its morphological typology. Differences in performance can be attributed to disparities in dataset size. These results bear on ongoing efforts to improve performance for low-performing and under-resourced languages.