 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025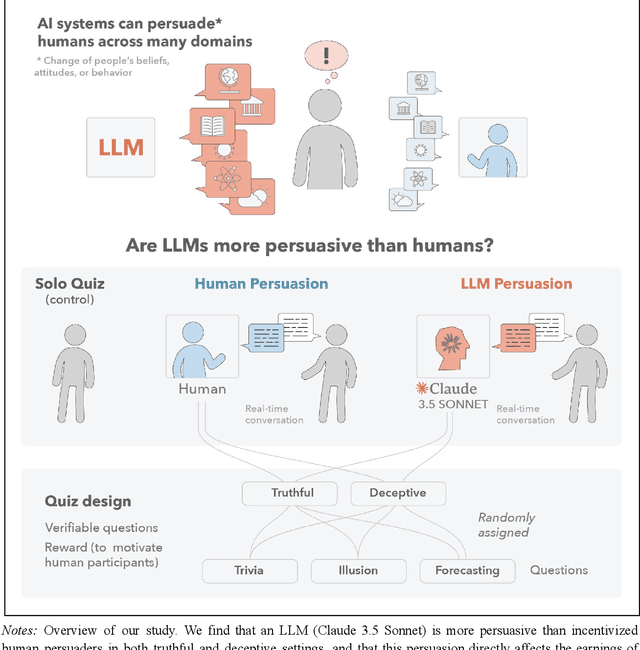
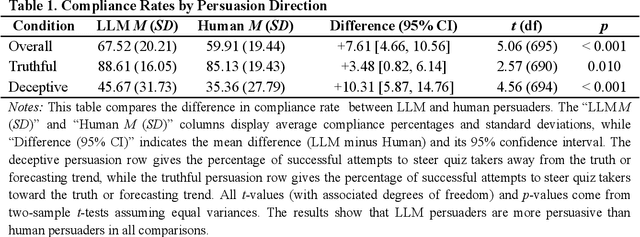
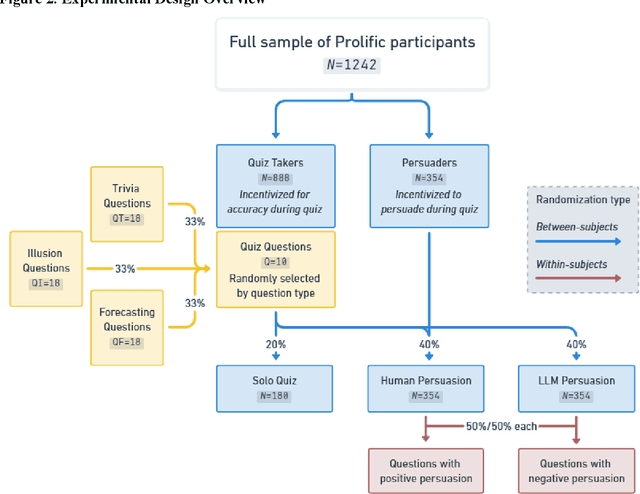
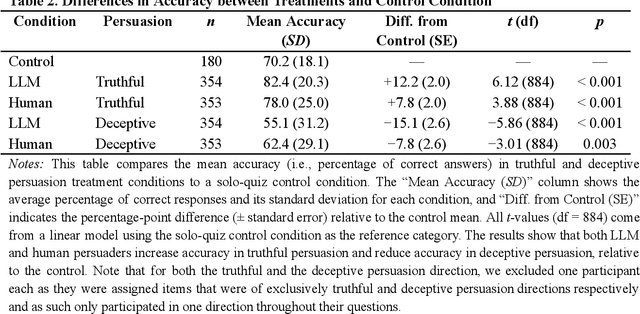
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Large Language Models Pass the Turing Test
Mar 31, 2025We evaluated 4 systems (ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5) in two randomised, controlled, and pre-registered Turing tests on independent populations. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a humanlike persona, GPT-4.5 was judged to be the human 73% of the time: significantly more often than interrogators selected the real human participant. LLaMa-3.1, with the same prompt, was judged to be the human 56% of the time -- not significantly more or less often than the humans they were being compared to -- while baseline models (ELIZA and GPT-4o) achieved win rates significantly below chance (23% and 21% respectively). The results constitute the first empirical evidence that any artificial system passes a standard three-party Turing test. The results have implications for debates about what kind of intelligence is exhibited by Large Language Models (LLMs), and the social and economic impacts these systems are likely to have.
Lies, Damned Lies, and Distributional Language Statistics: Persuasion and Deception with Large Language Models
Dec 22, 2024Large Language Models (LLMs) can generate content that is as persuasive as human-written text and appear capable of selectively producing deceptive outputs. These capabilities raise concerns about potential misuse and unintended consequences as these systems become more widely deployed. This review synthesizes recent empirical work examining LLMs' capacity and proclivity for persuasion and deception, analyzes theoretical risks that could arise from these capabilities, and evaluates proposed mitigations. While current persuasive effects are relatively small, various mechanisms could increase their impact, including fine-tuning, multimodality, and social factors. We outline key open questions for future research, including how persuasive AI systems might become, whether truth enjoys an inherent advantage over falsehoods, and how effective different mitigation strategies may be in practice.
GPT-4 is judged more human than humans in displaced and inverted Turing tests
Jul 11, 2024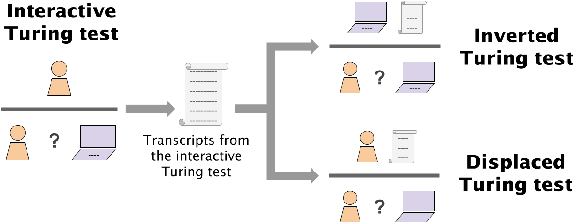
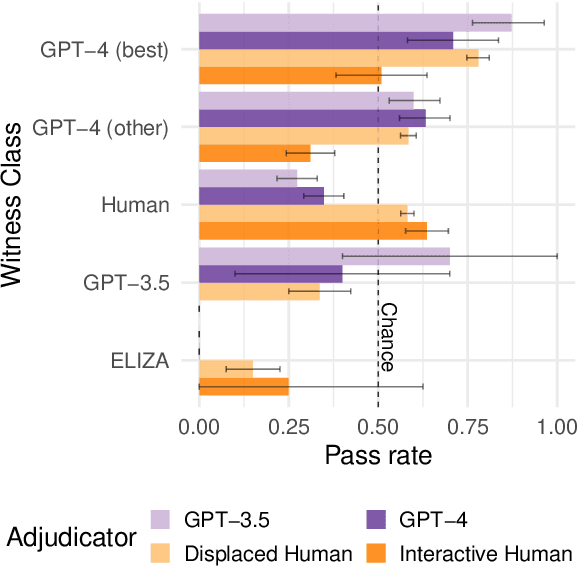
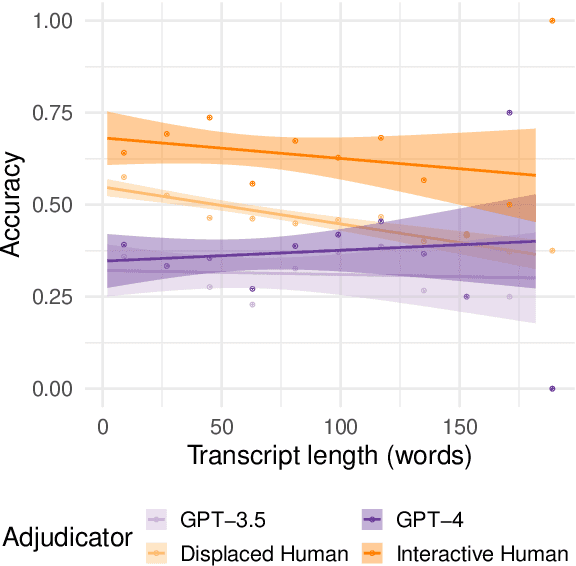
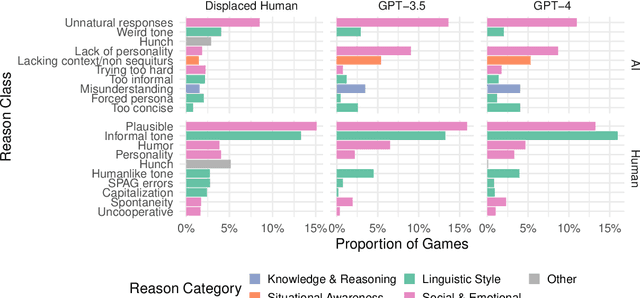
Everyday AI detection requires differentiating between people and AI in informal, online conversations. In many cases, people will not interact directly with AI systems but instead read conversations between AI systems and other people. We measured how well people and large language models can discriminate using two modified versions of the Turing test: inverted and displaced. GPT-3.5, GPT-4, and displaced human adjudicators judged whether an agent was human or AI on the basis of a Turing test transcript. We found that both AI and displaced human judges were less accurate than interactive interrogators, with below chance accuracy overall. Moreover, all three judged the best-performing GPT-4 witness to be human more often than human witnesses. This suggests that both humans and current LLMs struggle to distinguish between the two when they are not actively interrogating the person, underscoring an urgent need for more accurate tools to detect AI in conversations.
Dissecting the Ullman Variations with a SCALPEL: Why do LLMs fail at Trivial Alterations to the False Belief Task?
Jun 20, 2024

Recent empirical results have sparked a debate about whether or not Large Language Models (LLMs) are capable of Theory of Mind (ToM). While some have found LLMs to be successful on ToM evaluations such as the False Belief task (Kosinski, 2023), others have argued that LLMs solve these tasks by exploiting spurious correlations -- not representing beliefs -- since they fail on trivial alterations to these tasks (Ullman, 2023). In this paper, we introduce SCALPEL: a technique to generate targeted modifications for False Belief tasks to test different specific hypotheses about why LLMs fail. We find that modifications which make explicit common inferences -- such as that looking at a transparent object implies recognizing its contents -- preserve LLMs' performance. This suggests that LLMs' failures on modified ToM tasks could result from a lack of more general commonsense reasoning, rather than a failure to represent mental states. We argue that SCALPEL could be helpful for explaining LLM successes and failures in other cases.
People cannot distinguish GPT-4 from a human in a Turing test
May 09, 2024We evaluated 3 systems (ELIZA, GPT-3.5 and GPT-4) in a randomized, controlled, and preregistered Turing test. Human participants had a 5 minute conversation with either a human or an AI, and judged whether or not they thought their interlocutor was human. GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%). The results provide the first robust empirical demonstration that any artificial system passes an interactive 2-player Turing test. The results have implications for debates around machine intelligence and, more urgently, suggest that deception by current AI systems may go undetected. Analysis of participants' strategies and reasoning suggests that stylistic and socio-emotional factors play a larger role in passing the Turing test than traditional notions of intelligence.