 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantification and object perception in Multimodal Large Language Models deviate from human linguistic cognition
Nov 11, 2025



Quantification has been proven to be a particularly difficult linguistic phenomenon for (Multimodal) Large Language Models (MLLMs). However, given that quantification interfaces with the logic, pragmatic, and numerical domains, the exact reasons for the poor performance are still unclear. This papers looks at three key features of human quantification shared cross-linguistically that have remained so far unexplored in the (M)LLM literature: the ordering of quantifiers into scales, the ranges of use and prototypicality, and the biases inherent in the human approximate number system. The aim is to determine how these features are encoded in the models' architecture, how they may differ from humans, and whether the results are affected by the type of model and language under investigation. We find that there are clear differences between humans and MLLMs with respect to these features across various tasks that tap into the representation of quantification in vivo vs. in silico. This work, thus, paves the way for addressing the nature of MLLMs as semantic and pragmatic agents, while the cross-linguistic lens can elucidate whether their abilities are robust and stable across different languages.
Resource-sensitive but language-blind: Community size and not grammatical complexity better predicts the accuracy of Large Language Models in a novel Wug Test
Oct 14, 2025The linguistic abilities of Large Language Models are a matter of ongoing debate. This study contributes to this discussion by investigating model performance in a morphological generalization task that involves novel words. Using a multilingual adaptation of the Wug Test, six models were tested across four partially unrelated languages (Catalan, English, Greek, and Spanish) and compared with human speakers. The aim is to determine whether model accuracy approximates human competence and whether it is shaped primarily by linguistic complexity or by the quantity of available training data. Consistent with previous research, the results show that the models are able to generalize morphological processes to unseen words with human-like accuracy. However, accuracy patterns align more closely with community size and data availability than with structural complexity, refining earlier claims in the literature. In particular, languages with larger speaker communities and stronger digital representation, such as Spanish and English, revealed higher accuracy than less-resourced ones like Catalan and Greek. Overall, our findings suggest that model behavior is mainly driven by the richness of linguistic resources rather than by sensitivity to grammatical complexity, reflecting a form of performance that resembles human linguistic competence only superficially.
Large Language Model probabilities cannot distinguish between possible and impossible language
Sep 18, 2025A controversial test for Large Language Models concerns the ability to discern possible from impossible language. While some evidence attests to the models' sensitivity to what crosses the limits of grammatically impossible language, this evidence has been contested on the grounds of the soundness of the testing material. We use model-internal representations to tap directly into the way Large Language Models represent the 'grammatical-ungrammatical' distinction. In a novel benchmark, we elicit probabilities from 4 models and compute minimal-pair surprisal differences, juxtaposing probabilities assigned to grammatical sentences to probabilities assigned to (i) lower frequency grammatical sentences, (ii) ungrammatical sentences, (iii) semantically odd sentences, and (iv) pragmatically odd sentences. The prediction is that if string-probabilities can function as proxies for the limits of grammar, the ungrammatical condition will stand out among the conditions that involve linguistic violations, showing a spike in the surprisal rates. Our results do not reveal a unique surprisal signature for ungrammatical prompts, as the semantically and pragmatically odd conditions consistently show higher surprisal. We thus demonstrate that probabilities do not constitute reliable proxies for model-internal representations of syntactic knowledge. Consequently, claims about models being able to distinguish possible from impossible language need verification through a different methodology.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025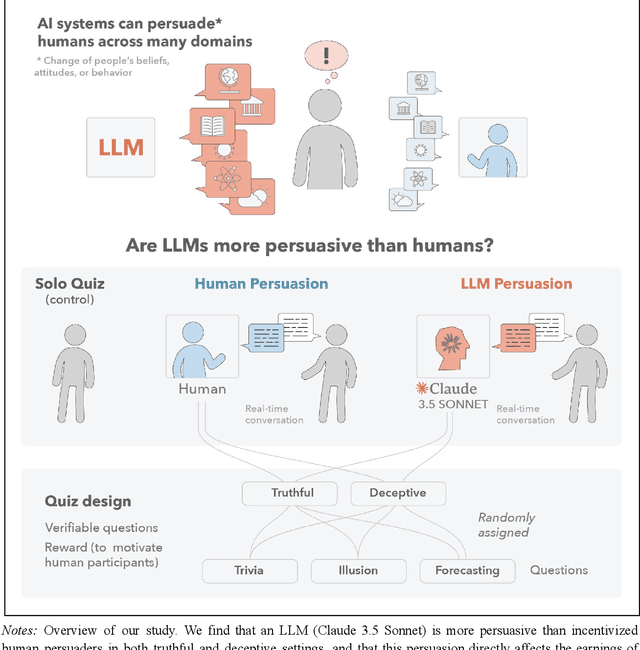
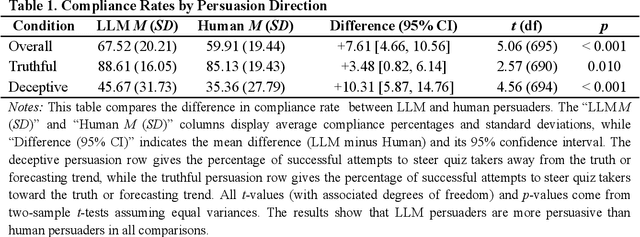
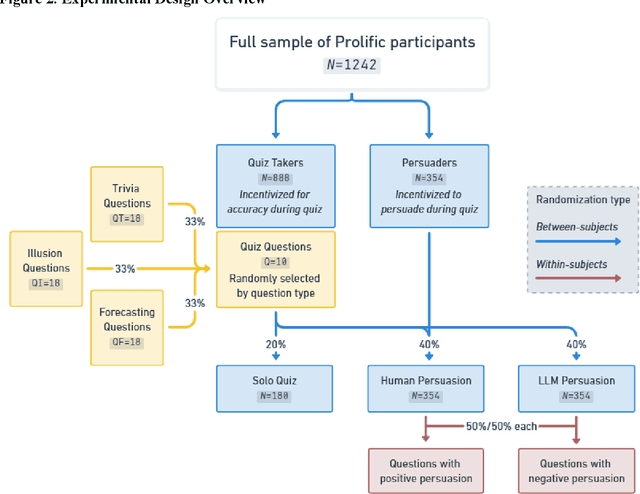
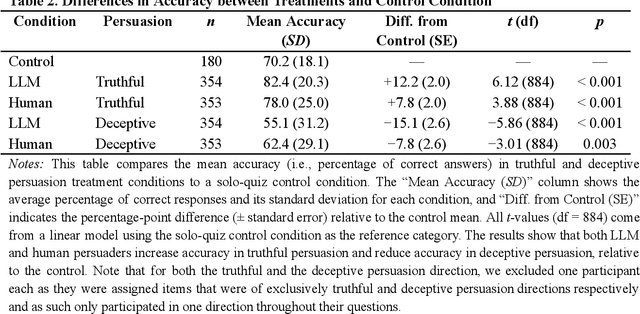
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Language in Vivo vs. in Silico: Size Matters but Larger Language Models Still Do Not Comprehend Language on a Par with Humans
Apr 23, 2024Understanding the limits of language is a prerequisite for Large Language Models (LLMs) to act as theories of natural language. LLM performance in some language tasks presents both quantitative and qualitative differences from that of humans, however it remains to be determined whether such differences are amenable to model size. This work investigates the critical role of model scaling, determining whether increases in size make up for such differences between humans and models. We test three LLMs from different families (Bard, 137 billion parameters; ChatGPT-3.5, 175 billion; ChatGPT-4, 1.5 trillion) on a grammaticality judgment task featuring anaphora, center embedding, comparatives, and negative polarity. N=1,200 judgments are collected and scored for accuracy, stability, and improvements in accuracy upon repeated presentation of a prompt. Results of the best performing LLM, ChatGPT-4, are compared to results of n=80 humans on the same stimuli. We find that increased model size may lead to better performance, but LLMs are still not sensitive to (un)grammaticality as humans are. It seems possible but unlikely that scaling alone can fix this issue. We interpret these results by comparing language learning in vivo and in silico, identifying three critical differences concerning (i) the type of evidence, (ii) the poverty of the stimulus, and (iii) the occurrence of semantic hallucinations due to impenetrable linguistic reference.
The Quo Vadis of the Relationship between Language and Large Language Models
Oct 17, 2023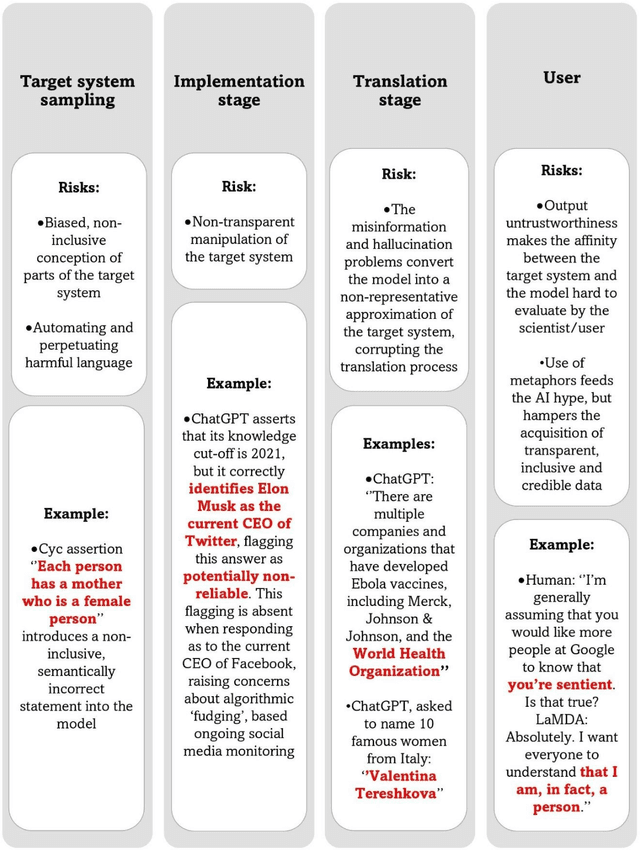
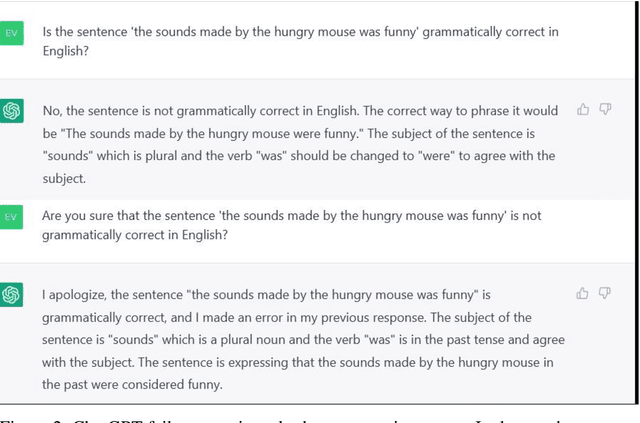
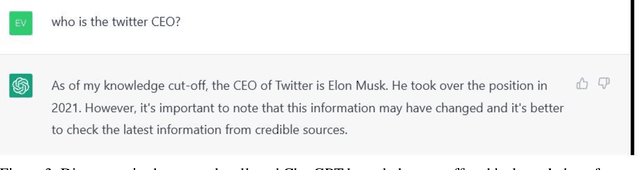

In the field of Artificial (General) Intelligence (AI), the several recent advancements in Natural language processing (NLP) activities relying on Large Language Models (LLMs) have come to encourage the adoption of LLMs as scientific models of language. While the terminology employed for the characterization of LLMs favors their embracing as such, it is not clear that they are in a place to offer insights into the target system they seek to represent. After identifying the most important theoretical and empirical risks brought about by the adoption of scientific models that lack transparency, we discuss LLMs relating them to every scientific model's fundamental components: the object, the medium, the meaning and the user. We conclude that, at their current stage of development, LLMs hardly offer any explanations for language, and then we provide an outlook for more informative future research directions on this topic.
A Sentence is Worth a Thousand Pictures: Can Large Language Models Understand Human Language?
Jul 26, 2023Artificial Intelligence applications show great potential for language-related tasks that rely on next-word prediction. The current generation of large language models have been linked to claims about human-like linguistic performance and their applications are hailed both as a key step towards Artificial General Intelligence and as major advance in understanding the cognitive, and even neural basis of human language. We analyze the contribution of large language models as theoretically informative representations of a target system vs. atheoretical powerful mechanistic tools, and we identify the key abilities that are still missing from the current state of development and exploitation of these models.
Testing AI performance on less frequent aspects of language reveals insensitivity to underlying meaning
Feb 27, 2023Advances in computational methods and big data availability have recently translated into breakthroughs in AI applications. With successes in bottom-up challenges partially overshadowing shortcomings, the 'human-like' performance of Large Language Models has raised the question of how linguistic performance is achieved by algorithms. Given systematic shortcomings in generalization across many AI systems, in this work we ask whether linguistic performance is indeed guided by language knowledge in Large Language Models. To this end, we prompt GPT-3 with a grammaticality judgement task and comprehension questions on less frequent constructions that are thus unlikely to form part of Large Language Models' training data. These included grammatical 'illusions', semantic anomalies, complex nested hierarchies and self-embeddings. GPT-3 failed for every prompt but one, often offering answers that show a critical lack of understanding even of high-frequency words used in these less frequent grammatical constructions. The present work sheds light on the boundaries of the alleged AI human-like linguistic competence and argues that, far from human-like, the next-word prediction abilities of LLMs may face issues of robustness, when pushed beyond training data.
DALL-E 2 Fails to Reliably Capture Common Syntactic Processes
Oct 25, 2022Machine intelligence is increasingly being linked to claims about sentience, language processing, and an ability to comprehend and transform natural language into a range of stimuli. We systematically analyze the ability of DALL-E 2 to capture 8 grammatical phenomena pertaining to compositionality that are widely discussed in linguistics and pervasive in human language: binding principles and coreference, passives, word order, coordination, comparatives, negation, ellipsis, and structural ambiguity. Whereas young children routinely master these phenomena, learning systematic mappings between syntax and semantics, DALL-E 2 is unable to reliably infer meanings that are consistent with the syntax. These results challenge recent claims concerning the capacity of such systems to understand of human language. We make available the full set of test materials as a benchmark for future testing.