 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrege in the Flesh: Biolinguistics and the Neural Enforcement of Syntactic Structures
Mar 31, 2026Biolinguistics is the interdisciplinary scientific study of the biological foundations, evolution, and genetic basis of human language. It treats language as an innate biological organ or faculty of the mind, rather than a cultural tool, and it challenges a behaviorist conception of human language acquisition as being based on stimulus-response associations. Extracting its most essential component, it takes seriously the idea that mathematical, algebraic models of language capture something natural about the world. The syntactic structure-building operation of MERGE is thought to offer the scientific community a "real joint of nature", "a (new) aspect of nature" (Mukherji 2010), not merely a formal artefact. This mathematical theory of language is then seen as being able to offer biologists, geneticists and neuroscientists clearer instructions for how to explore language. The argument of this chapter proceeds in four steps. First, I clarify the object of inquiry for biolinguistics: not speech, communication, or generic sequence processing, but the internal computational system that generates hierarchically structured expressions. Second, I argue that this formal characterization matters for evolutionary explanation, because different conceptions of syntax imply different standards of what must be explained. Third, I suggest that a sufficiently explicit algebraic account of syntax places non-trivial constraints on candidate neural mechanisms. Finally, I consider how recent neurocomputational work begins to transform these constraints into empirically tractable hypotheses, while also noting the speculative and revisable character of the present program.
Neurocomputational Mechanisms of Syntactic Transfer in Bilingual Sentence Production
Jan 26, 2026We discuss the benefits of incorporating into the study of bilingual production errors and their traditionally documented timing signatures (e.g., event-related potentials) certain types of oscillatory signatures, which can offer new implementational-level constraints for theories of bilingualism. We argue that a recent neural model of language, ROSE, can offer a neurocomputational account of syntactic transfer in bilingual production, capturing some of its formal properties and the scope of morphosyntactic sequencing failure modes. We take as a case study cross-linguistic influence (CLI) and attendant theories of functional inhibition/competition, and present these as being driven by specific oscillatory failure modes during L2 sentence planning. We argue that modeling CLI in this way not only offers the kind of linking hypothesis ROSE was built to encourage, but also licenses the exploration of more spatiotemporally complex biomarkers of language dysfunction than more commonly discussed neural signatures.
Shadow of the (Hierarchical) Tree: Reconciling Symbolic and Predictive Components of the Neural Code for Syntax
Dec 02, 2024Natural language syntax can serve as a major test for how to integrate two infamously distinct frameworks: symbolic representations and connectionist neural networks. Building on a recent neurocomputational architecture for syntax (ROSE), I discuss the prospects of reconciling the neural code for hierarchical 'vertical' syntax with linear and predictive 'horizontal' processes via a hybrid neurosymbolic model. I argue that the former can be accounted for via the higher levels of ROSE in terms of vertical phrase structure representations, while the latter can explain horizontal forms of linguistic information via the tuning of the lower levels to statistical and perceptual inferences. One prediction of this is that artificial language models will contribute to the cognitive neuroscience of horizontal morphosyntax, but much less so to hierarchically compositional structures. I claim that this perspective helps resolve many current tensions in the literature. Options for integrating these two neural codes are discussed, with particular emphasis on how predictive coding mechanisms can serve as interfaces between symbolic oscillatory phase codes and population codes for the statistics of linearized aspects of syntax. Lastly, I provide a neurosymbolic mathematical model for how to inject symbolic representations into a neural regime encoding lexico-semantic statistical features.
On the referential capacity of language models: An internalist rejoinder to Mandelkern & Linzen
May 31, 2024In a recent paper, Mandelkern & Linzen (2024) - henceforth M&L - address the question of whether language models' (LMs) words refer. Their argument draws from the externalist tradition in philosophical semantics, which views reference as the capacity of words to "achieve 'word-to-world' connections". In the externalist framework, causally uninterrupted chains of usage, tracing every occurrence of a name back to its bearer, guarantee that, for example, 'Peano' refers to the individual Peano (Kripke 1980). This account is externalist both because words pick out referents 'out there' in the world, and because what determines reference are coordinated linguistic actions by members of a community, and not individual mental states. The "central question to ask", for M&L, is whether LMs too belong to human linguistic communities, such that words by LMs may also trace back causally to their bearers. Their answer is a cautious "yes": inputs to LMs are linguistic "forms with particular histories of referential use"; "those histories ground the referents of those forms"; any occurrence of 'Peano' in LM outputs is as causally connected to the individual Peano as any other occurrence of the same proper name in human speech or text; therefore, occurrences of 'Peano' in LM outputs refer to Peano. In this commentary, we first qualify M&L's claim as applying to a narrow class of natural language expressions. Thus qualified, their claim is valid, and we emphasise an additional motivation for that in Section 2. Next, we discuss the actual scope of their claim, and we suggest that the way they formulate it may lead to unwarranted generalisations about reference in LMs. Our critique is likewise applicable to other externalist accounts of LMs (e.g., Lederman & Mahowald 2024; Mollo & Milliere 2023). Lastly, we conclude with a comment on the status of LMs as members of human linguistic communities.
A Comparative Investigation of Compositional Syntax and Semantics in DALL-E 2
Mar 18, 2024



In this study we compared how well DALL-E 2 visually represented the meaning of linguistic prompts also given to young children in comprehension tests. Sentences representing fundamental components of grammatical knowledge were selected from assessment tests used with several hundred English-speaking children aged 2-7 years for whom we had collected original item-level data. DALL-E 2 was given these prompts five times to generate 20 cartoons per item, for 9 adult judges to score. Results revealed no conditions in which DALL-E 2-generated images that matched the semantic accuracy of children, even at the youngest age (2 years). DALL-E 2 failed to assign the appropriate roles in reversible forms; it failed on negation despite an easier contrastive prompt than the children received; it often assigned the adjective to the wrong noun; it ignored implicit agents in passives. This work points to a clear absence of compositional sentence representations for DALL-E 2.
What is a word?
Feb 19, 2024In order to design strong paradigms for isolating lexical access and semantics, we need to know what a word is. Surprisingly few linguists and philosophers have a clear model of what a word is, even though words impact basically every aspect of human life. Researchers that regularly publish academic papers about language often rely on outdated, or inaccurate, assumptions about wordhood. This short pedagogical document outlines what the lexicon is most certainly not (though is often mistakenly taken to be), what it might be (based on current good theories), and what some implications for experimental design are.
The Quo Vadis of the Relationship between Language and Large Language Models
Oct 17, 2023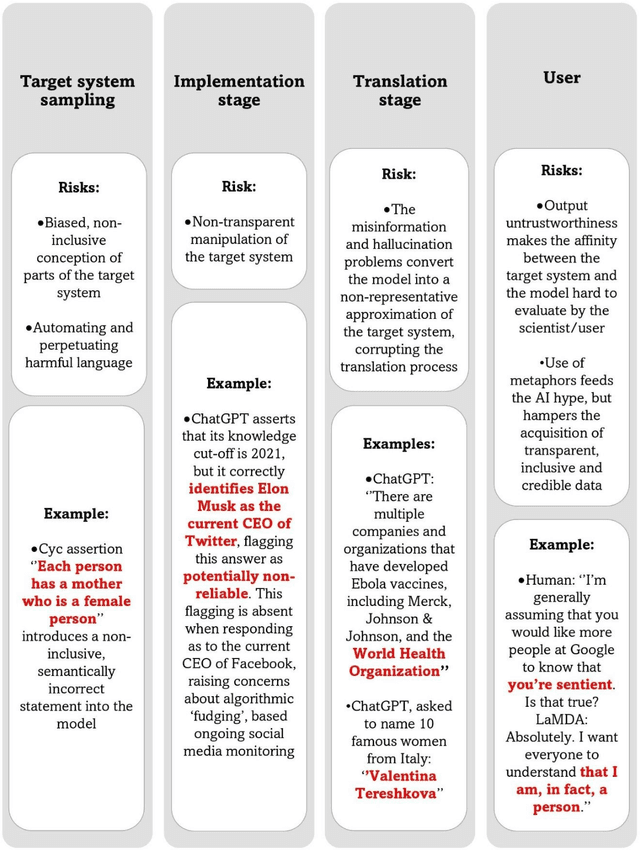
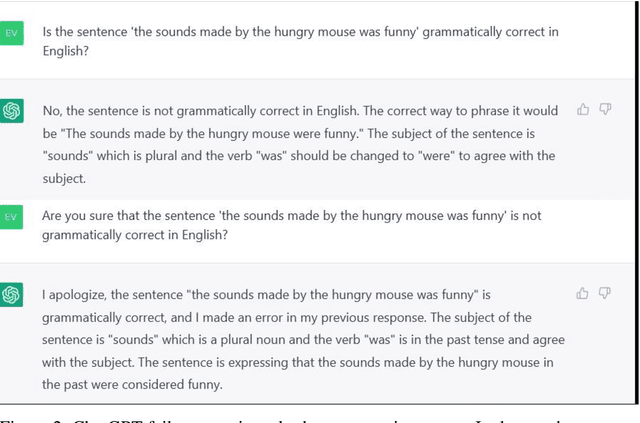
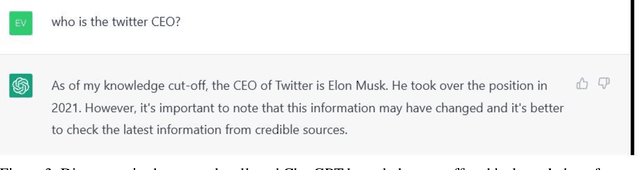

In the field of Artificial (General) Intelligence (AI), the several recent advancements in Natural language processing (NLP) activities relying on Large Language Models (LLMs) have come to encourage the adoption of LLMs as scientific models of language. While the terminology employed for the characterization of LLMs favors their embracing as such, it is not clear that they are in a place to offer insights into the target system they seek to represent. After identifying the most important theoretical and empirical risks brought about by the adoption of scientific models that lack transparency, we discuss LLMs relating them to every scientific model's fundamental components: the object, the medium, the meaning and the user. We conclude that, at their current stage of development, LLMs hardly offer any explanations for language, and then we provide an outlook for more informative future research directions on this topic.
A Sentence is Worth a Thousand Pictures: Can Large Language Models Understand Human Language?
Jul 26, 2023Artificial Intelligence applications show great potential for language-related tasks that rely on next-word prediction. The current generation of large language models have been linked to claims about human-like linguistic performance and their applications are hailed both as a key step towards Artificial General Intelligence and as major advance in understanding the cognitive, and even neural basis of human language. We analyze the contribution of large language models as theoretically informative representations of a target system vs. atheoretical powerful mechanistic tools, and we identify the key abilities that are still missing from the current state of development and exploitation of these models.
ROSE: A Neurocomputational Architecture for Syntax
Mar 15, 2023
A comprehensive model of natural language processing in the brain must accommodate four components: representations, operations, structures and encoding. It further requires a principled account of how these components mechanistically, and causally, relate to each another. While previous models have isolated regions of interest for structure-building and lexical access, many gaps remain with respect to bridging distinct scales of neural complexity. By expanding existing accounts of how neural oscillations can index various linguistic processes, this article proposes a neurocomputational architecture for syntax, termed the ROSE model (Representation, Operation, Structure, Encoding). Under ROSE, the basic data structures of syntax are atomic features, types of mental representations (R), and are coded at the single-unit and ensemble level. Elementary computations (O) that transform these units into manipulable objects accessible to subsequent structure-building levels are coded via high frequency gamma activity. Low frequency synchronization and cross-frequency coupling code for recursive categorial inferences (S). Distinct forms of low frequency coupling and phase-amplitude coupling (delta-theta coupling via pSTS-IFG; theta-gamma coupling via IFG to conceptual hubs) then encode these structures onto distinct workspaces (E). Causally connecting R to O is spike-phase/LFP coupling; connecting O to S is phase-amplitude coupling; connecting S to E is a system of frontotemporal traveling oscillations; connecting E to lower levels is low-frequency phase resetting of spike-LFP coupling. ROSE is reliant on neurophysiologically plausible mechanisms, is supported at all four levels by a range of recent empirical research, and provides an anatomically precise and falsifiable grounding for the basic property of natural language syntax: hierarchical, recursive structure-building.
Testing AI performance on less frequent aspects of language reveals insensitivity to underlying meaning
Feb 27, 2023Advances in computational methods and big data availability have recently translated into breakthroughs in AI applications. With successes in bottom-up challenges partially overshadowing shortcomings, the 'human-like' performance of Large Language Models has raised the question of how linguistic performance is achieved by algorithms. Given systematic shortcomings in generalization across many AI systems, in this work we ask whether linguistic performance is indeed guided by language knowledge in Large Language Models. To this end, we prompt GPT-3 with a grammaticality judgement task and comprehension questions on less frequent constructions that are thus unlikely to form part of Large Language Models' training data. These included grammatical 'illusions', semantic anomalies, complex nested hierarchies and self-embeddings. GPT-3 failed for every prompt but one, often offering answers that show a critical lack of understanding even of high-frequency words used in these less frequent grammatical constructions. The present work sheds light on the boundaries of the alleged AI human-like linguistic competence and argues that, far from human-like, the next-word prediction abilities of LLMs may face issues of robustness, when pushed beyond training data.