 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage in Vivo vs. in Silico: Size Matters but Larger Language Models Still Do Not Comprehend Language on a Par with Humans
Apr 23, 2024Understanding the limits of language is a prerequisite for Large Language Models (LLMs) to act as theories of natural language. LLM performance in some language tasks presents both quantitative and qualitative differences from that of humans, however it remains to be determined whether such differences are amenable to model size. This work investigates the critical role of model scaling, determining whether increases in size make up for such differences between humans and models. We test three LLMs from different families (Bard, 137 billion parameters; ChatGPT-3.5, 175 billion; ChatGPT-4, 1.5 trillion) on a grammaticality judgment task featuring anaphora, center embedding, comparatives, and negative polarity. N=1,200 judgments are collected and scored for accuracy, stability, and improvements in accuracy upon repeated presentation of a prompt. Results of the best performing LLM, ChatGPT-4, are compared to results of n=80 humans on the same stimuli. We find that increased model size may lead to better performance, but LLMs are still not sensitive to (un)grammaticality as humans are. It seems possible but unlikely that scaling alone can fix this issue. We interpret these results by comparing language learning in vivo and in silico, identifying three critical differences concerning (i) the type of evidence, (ii) the poverty of the stimulus, and (iii) the occurrence of semantic hallucinations due to impenetrable linguistic reference.
The Quo Vadis of the Relationship between Language and Large Language Models
Oct 17, 2023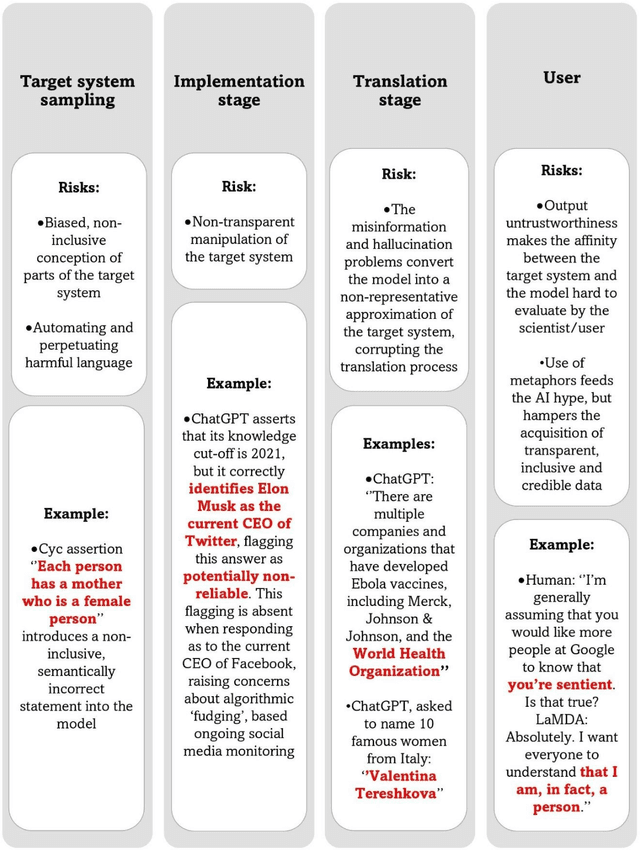

In the field of Artificial (General) Intelligence (AI), the several recent advancements in Natural language processing (NLP) activities relying on Large Language Models (LLMs) have come to encourage the adoption of LLMs as scientific models of language. While the terminology employed for the characterization of LLMs favors their embracing as such, it is not clear that they are in a place to offer insights into the target system they seek to represent. After identifying the most important theoretical and empirical risks brought about by the adoption of scientific models that lack transparency, we discuss LLMs relating them to every scientific model's fundamental components: the object, the medium, the meaning and the user. We conclude that, at their current stage of development, LLMs hardly offer any explanations for language, and then we provide an outlook for more informative future research directions on this topic.
Testing AI performance on less frequent aspects of language reveals insensitivity to underlying meaning
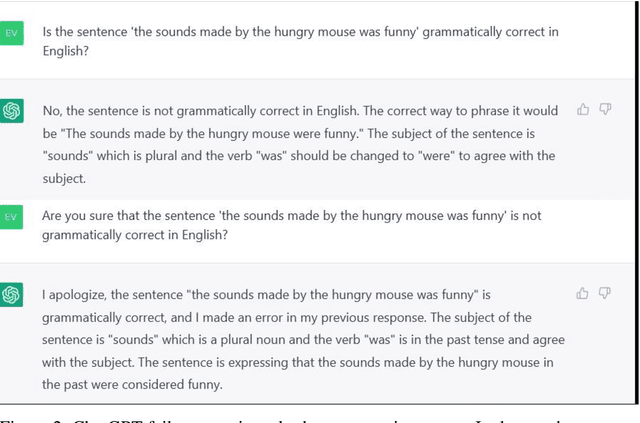
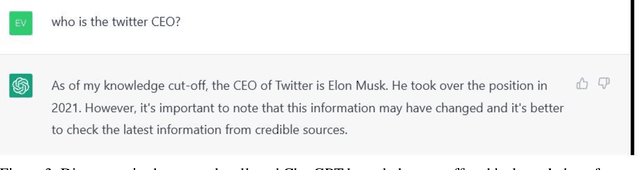
Feb 27, 2023Advances in computational methods and big data availability have recently translated into breakthroughs in AI applications. With successes in bottom-up challenges partially overshadowing shortcomings, the 'human-like' performance of Large Language Models has raised the question of how linguistic performance is achieved by algorithms. Given systematic shortcomings in generalization across many AI systems, in this work we ask whether linguistic performance is indeed guided by language knowledge in Large Language Models. To this end, we prompt GPT-3 with a grammaticality judgement task and comprehension questions on less frequent constructions that are thus unlikely to form part of Large Language Models' training data. These included grammatical 'illusions', semantic anomalies, complex nested hierarchies and self-embeddings. GPT-3 failed for every prompt but one, often offering answers that show a critical lack of understanding even of high-frequency words used in these less frequent grammatical constructions. The present work sheds light on the boundaries of the alleged AI human-like linguistic competence and argues that, far from human-like, the next-word prediction abilities of LLMs may face issues of robustness, when pushed beyond training data.