 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow cyborg propaganda reshapes collective action
Feb 13, 2026The distinction between genuine grassroots activism and automated influence operations is collapsing. While policy debates focus on bot farms, a distinct threat to democracy is emerging via partisan coordination apps and artificial intelligence-what we term 'cyborg propaganda.' This architecture combines large numbers of verified humans with adaptive algorithmic automation, enabling a closed-loop system. AI tools monitor online sentiment to optimize directives and generate personalized content for users to post online. Cyborg propaganda thereby exploits a critical legal shield: by relying on verified citizens to ratify and disseminate messages, these campaigns operate in a regulatory gray zone, evading liability frameworks designed for automated botnets. We explore the collective action paradox of this technology: does it democratize power by 'unionizing' influence (pooling the reach of dispersed citizens to overcome the algorithmic invisibility of isolated voices), or does it reduce citizens to 'cognitive proxies' of a central directive? We argue that cyborg propaganda fundamentally alters the digital public square, shifting political discourse from a democratic contest of individual ideas to a battle of algorithmic campaigns. We outline a research agenda to distinguish organic from coordinated information diffusion and propose governance frameworks to address the regulatory challenges of AI-assisted collective expression.
Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc
Jul 31, 2023
Generative AI, the most popular current approach to AI, consists of large language models (LLMs) that are trained to produce outputs that are plausible, but not necessarily correct. Although their abilities are often uncanny, they are lacking in aspects of reasoning, leading LLMs to be less than completely trustworthy. Furthermore, their results tend to be both unpredictable and uninterpretable. We lay out 16 desiderata for future AI, and discuss an alternative approach to AI which could theoretically address many of the limitations associated with current approaches: AI educated with curated pieces of explicit knowledge and rules of thumb, enabling an inference engine to automatically deduce the logical entailments of all that knowledge. Even long arguments produced this way can be both trustworthy and interpretable, since the full step-by-step line of reasoning is always available, and for each step the provenance of the knowledge used can be documented and audited. There is however a catch: if the logical language is expressive enough to fully represent the meaning of anything we can say in English, then the inference engine runs much too slowly. That's why symbolic AI systems typically settle for some fast but much less expressive logic, such as knowledge graphs. We describe how one AI system, Cyc, has developed ways to overcome that tradeoff and is able to reason in higher order logic in real time. We suggest that any trustworthy general AI will need to hybridize the approaches, the LLM approach and more formal approach, and lay out a path to realizing that dream.
A Sentence is Worth a Thousand Pictures: Can Large Language Models Understand Human Language?
Jul 26, 2023Artificial Intelligence applications show great potential for language-related tasks that rely on next-word prediction. The current generation of large language models have been linked to claims about human-like linguistic performance and their applications are hailed both as a key step towards Artificial General Intelligence and as major advance in understanding the cognitive, and even neural basis of human language. We analyze the contribution of large language models as theoretically informative representations of a target system vs. atheoretical powerful mechanistic tools, and we identify the key abilities that are still missing from the current state of development and exploitation of these models.
Testing AI performance on less frequent aspects of language reveals insensitivity to underlying meaning
Feb 27, 2023Advances in computational methods and big data availability have recently translated into breakthroughs in AI applications. With successes in bottom-up challenges partially overshadowing shortcomings, the 'human-like' performance of Large Language Models has raised the question of how linguistic performance is achieved by algorithms. Given systematic shortcomings in generalization across many AI systems, in this work we ask whether linguistic performance is indeed guided by language knowledge in Large Language Models. To this end, we prompt GPT-3 with a grammaticality judgement task and comprehension questions on less frequent constructions that are thus unlikely to form part of Large Language Models' training data. These included grammatical 'illusions', semantic anomalies, complex nested hierarchies and self-embeddings. GPT-3 failed for every prompt but one, often offering answers that show a critical lack of understanding even of high-frequency words used in these less frequent grammatical constructions. The present work sheds light on the boundaries of the alleged AI human-like linguistic competence and argues that, far from human-like, the next-word prediction abilities of LLMs may face issues of robustness, when pushed beyond training data.
DALL-E 2 Fails to Reliably Capture Common Syntactic Processes
Oct 25, 2022Machine intelligence is increasingly being linked to claims about sentience, language processing, and an ability to comprehend and transform natural language into a range of stimuli. We systematically analyze the ability of DALL-E 2 to capture 8 grammatical phenomena pertaining to compositionality that are widely discussed in linguistics and pervasive in human language: binding principles and coreference, passives, word order, coordination, comparatives, negation, ellipsis, and structural ambiguity. Whereas young children routinely master these phenomena, learning systematic mappings between syntax and semantics, DALL-E 2 is unable to reliably infer meanings that are consistent with the syntax. These results challenge recent claims concerning the capacity of such systems to understand of human language. We make available the full set of test materials as a benchmark for future testing.
A very preliminary analysis of DALL-E 2
May 02, 2022The DALL-E 2 system generates original synthetic images corresponding to an input text as caption. We report here on the outcome of fourteen tests of this system designed to assess its common sense, reasoning and ability to understand complex texts. All of our prompts were intentionally much more challenging than the typical ones that have been showcased in recent weeks. Nevertheless, for 5 out of the 14 prompts, at least one of the ten images fully satisfied our requests. On the other hand, on no prompt did all of the ten images satisfy our requests.
The Defeat of the Winograd Schema Challenge
Jan 16, 2022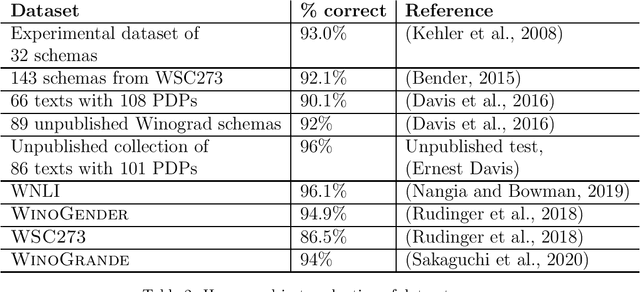

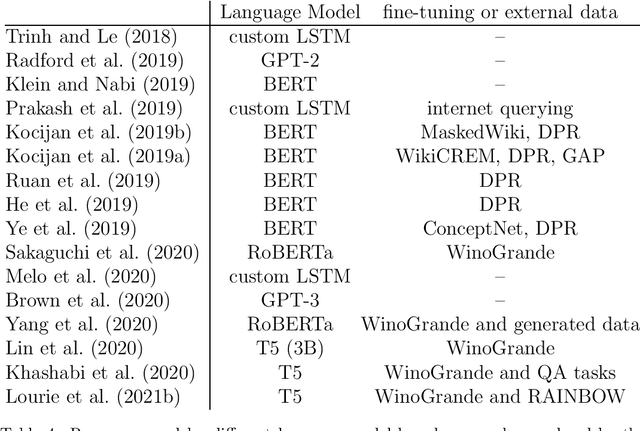
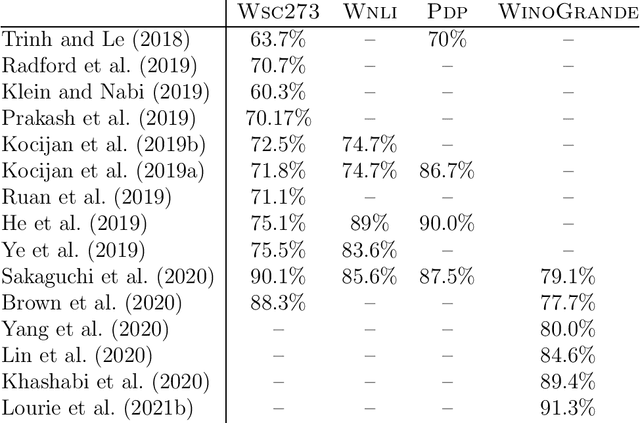
The Winograd Schema Challenge -- a set of twin sentences involving pronoun reference disambiguation that seem to require the use of commonsense knowledge -- was proposed by Hector Levesque in 2011. By 2019, a number of AI systems, based on large pre-trained transformer-based language models and fine-tuned on these kinds of problems, achieved better than 90% accuracy. In this paper, we review the history of the Winograd Schema Challenge and assess its significance.
A Review of Winograd Schema Challenge Datasets and Approaches
Apr 23, 2020The Winograd Schema Challenge is both a commonsense reasoning and natural language understanding challenge, introduced as an alternative to the Turing test. A Winograd schema is a pair of sentences differing in one or two words with a highly ambiguous pronoun, resolved differently in the two sentences, that appears to require commonsense knowledge to be resolved correctly. The examples were designed to be easily solvable by humans but difficult for machines, in principle requiring a deep understanding of the content of the text and the situation it describes. This paper reviews existing Winograd Schema Challenge benchmark datasets and approaches that have been published since its introduction.
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
Feb 19, 2020

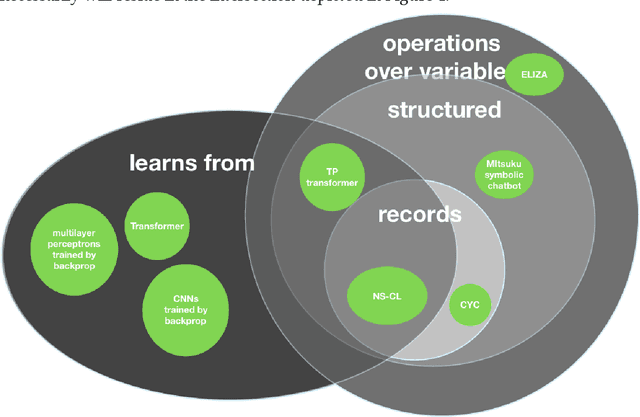
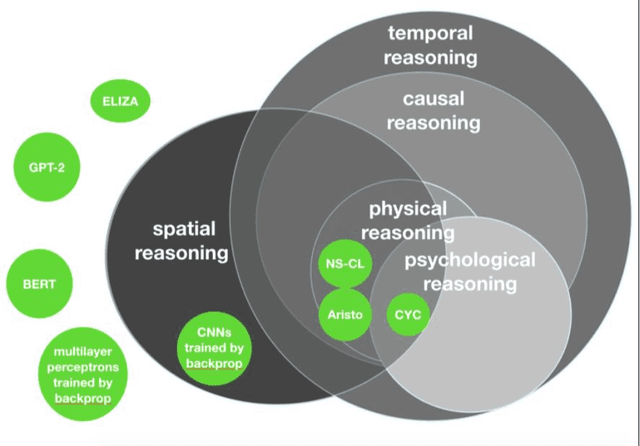
Recent research in artificial intelligence and machine learning has largely emphasized general-purpose learning and ever-larger training sets and more and more compute. In contrast, I propose a hybrid, knowledge-driven, reasoning-based approach, centered around cognitive models, that could provide the substrate for a richer, more robust AI than is currently possible.
Innateness, AlphaZero, and Artificial Intelligence
Jan 17, 2018The concept of innateness is rarely discussed in the context of artificial intelligence. When it is discussed, or hinted at, it is often the context of trying to reduce the amount of innate machinery in a given system. In this paper, I consider as a test case a recent series of papers by Silver et al (Silver et al., 2017a) on AlphaGo and its successors that have been presented as an argument that a "even in the most challenging of domains: it is possible to train to superhuman level, without human examples or guidance", "starting tabula rasa." I argue that these claims are overstated, for multiple reasons. I close by arguing that artificial intelligence needs greater attention to innateness, and I point to some proposals about what that innateness might look like.