 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Hopfield Memory Networks
Mar 26, 2026Recent vision and multimodal foundation backbones, such as Transformer families and state-space models like Mamba, have achieved remarkable progress, enabling unified modeling across images, text, and beyond. Despite their empirical success, these architectures remain far from the computational principles of the human brain, often demanding enormous amounts of training data while offering limited interpretability. In this work, we propose the Vision Hopfield Memory Network (V-HMN), a brain-inspired foundation backbone that integrates hierarchical memory mechanisms with iterative refinement updates. Specifically, V-HMN incorporates local Hopfield modules that provide associative memory dynamics at the image patch level, global Hopfield modules that function as episodic memory for contextual modulation, and a predictive-coding-inspired refinement rule for iterative error correction. By organizing these memory-based modules hierarchically, V-HMN captures both local and global dynamics in a unified framework. Memory retrieval exposes the relationship between inputs and stored patterns, making decisions more interpretable, while the reuse of stored patterns improves data efficiency. This brain-inspired design therefore enhances interpretability and data efficiency beyond existing self-attention- or state-space-based approaches. We conducted extensive experiments on public computer vision benchmarks, and V-HMN achieved competitive results against widely adopted backbone architectures, while offering better interpretability, higher data efficiency, and stronger biological plausibility. These findings highlight the potential of V-HMN to serve as a next-generation vision foundation model, while also providing a generalizable blueprint for multimodal backbones in domains such as text and audio, thereby bridging brain-inspired computation with large-scale machine learning.
Visual Set Program Synthesizer
Mar 16, 2026A user pointing their phone at a supermarket shelf and asking "Which soda has the least sugar?" poses a difficult challenge for current visual Al assistants. Such queries require not only object recognition, but explicit set-based reasoning such as filtering, comparison, and aggregation. Standard endto-end MLLMs often fail at these tasks because they lack an explicit mechanism for compositional logic. We propose treating visual reasoning as Visual Program Synthesis, where the model first generates a symbolic program that is executed by a separate engine grounded in visual scenes. We also introduce Set-VQA, a new benchmark designed specifically for evaluating set-based visual reasoning. Experiments show that our approach significantly outperforms state-of-the-art baselines on complex reasoning tasks, producing more systematic and transparent behavior while substantially improving answer accuracy. These results demonstrate that program-driven reasoning provides a principled alternative to black-box visual-language inference.
* 10 pages, IEEE International Conference on Multimedia and Expo 2026
Prototype Transformer: Towards Language Model Architectures Interpretable by Design
Feb 12, 2026While state-of-the-art language models (LMs) surpass the vast majority of humans in certain domains, their reasoning remains largely opaque, undermining trust in their output. Furthermore, while autoregressive LMs can output explicit reasoning, their true reasoning process is opaque, which introduces risks like deception and hallucination. In this work, we introduce the Prototype Transformer (ProtoT) -- an autoregressive LM architecture based on prototypes (parameter vectors), posed as an alternative to the standard self-attention-based transformers. ProtoT works by means of two-way communication between the input sequence and the prototypes, and we show that this leads to the prototypes automatically capturing nameable concepts (e.g. "woman") during training. They provide the potential to interpret the model's reasoning and allow for targeted edits of its behavior. Furthermore, by design, the prototypes create communication channels that aggregate contextual information at different time scales, aiding interpretability. In terms of computation scalability, ProtoT scales linearly with sequence length vs the quadratic scalability of SOTA self-attention transformers. Compared to baselines, ProtoT scales well with model and data size, and performs well on text generation and downstream tasks (GLUE). ProtoT exhibits robustness to input perturbations on par or better than some baselines, but differs from them by providing interpretable pathways showing how robustness and sensitivity arises. Reaching close to the performance of state-of-the-art architectures, ProtoT paves the way to creating well-performing autoregressive LMs interpretable by design.
Faster Predictive Coding Networks via Better Initialization
Jan 28, 2026Research aimed at scaling up neuroscience inspired learning algorithms for neural networks is accelerating. Recently, a key research area has been the study of energy-based learning algorithms such as predictive coding, due to their versatility and mathematical grounding. However, the applicability of such methods is held back by the large computational requirements caused by their iterative nature. In this work, we address this problem by showing that the choice of initialization of the neurons in a predictive coding network matters significantly and can notably reduce the required training times. Consequently, we propose a new initialization technique for predictive coding networks that aims to preserve the iterative progress made on previous training samples. Our approach suggests a promising path toward reconciling the disparities between predictive coding and backpropagation in terms of computational efficiency and final performance. In fact, our experiments demonstrate substantial improvements in convergence speed and final test loss in both supervised and unsupervised settings.
A Survey on Tabular Data Generation: Utility, Alignment, Fidelity, Privacy, and Beyond
Mar 07, 2025Generative modelling has become the standard approach for synthesising tabular data. However, different use cases demand synthetic data to comply with different requirements to be useful in practice. In this survey, we review deep generative modelling approaches for tabular data from the perspective of four types of requirements: utility of the synthetic data, alignment of the synthetic data with domain-specific knowledge, statistical fidelity of the synthetic data distribution compared to the real data distribution, and privacy-preserving capabilities. We group the approaches along two levels of granularity: (i) based on the primary type of requirements they address and (ii) according to the underlying model they utilise. Additionally, we summarise the appropriate evaluation methods for each requirement and the specific characteristics of each model type. Finally, we discuss future directions for the field, along with opportunities to improve the current evaluation methods. Overall, this survey can be seen as a user guide to tabular data generation: helping readers navigate available models and evaluation methods to find those best suited to their needs.
Shh, don't say that! Domain Certification in LLMs
Feb 26, 2025Large language models (LLMs) are often deployed to perform constrained tasks, with narrow domains. For example, customer support bots can be built on top of LLMs, relying on their broad language understanding and capabilities to enhance performance. However, these LLMs are adversarially susceptible, potentially generating outputs outside the intended domain. To formalize, assess, and mitigate this risk, we introduce domain certification; a guarantee that accurately characterizes the out-of-domain behavior of language models. We then propose a simple yet effective approach, which we call VALID that provides adversarial bounds as a certificate. Finally, we evaluate our method across a diverse set of datasets, demonstrating that it yields meaningful certificates, which bound the probability of out-of-domain samples tightly with minimum penalty to refusal behavior.
* 10 pages, includes appendix Published in International Conference on Learning Representations (ICLR) 2025
Detection-Fusion for Knowledge Graph Extraction from Videos
Dec 30, 2024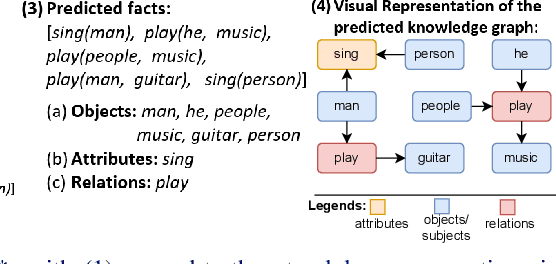
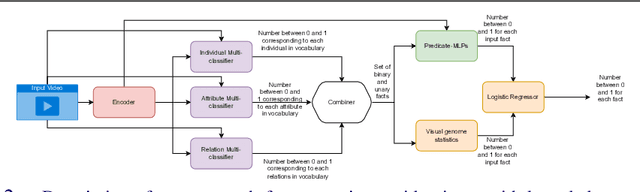

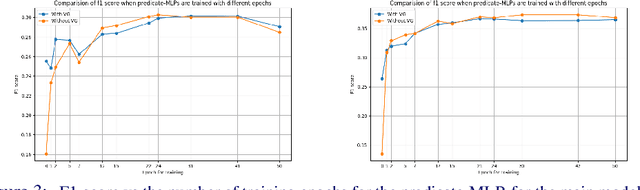
One of the challenging tasks in the field of video understanding is extracting semantic content from video inputs. Most existing systems use language models to describe videos in natural language sentences, but this has several major shortcomings. Such systems can rely too heavily on the language model component and base their output on statistical regularities in natural language text rather than on the visual contents of the video. Additionally, natural language annotations cannot be readily processed by a computer, are difficult to evaluate with performance metrics and cannot be easily translated into a different natural language. In this paper, we propose a method to annotate videos with knowledge graphs, and so avoid these problems. Specifically, we propose a deep-learning-based model for this task that first predicts pairs of individuals and then the relations between them. Additionally, we propose an extension of our model for the inclusion of background knowledge in the construction of knowledge graphs.
Data for Mathematical Copilots: Better Ways of Presenting Proofs for Machine Learning
Dec 19, 2024

The suite of datasets commonly used to train and evaluate the mathematical capabilities of AI-based mathematical copilots (primarily large language models) exhibit several shortcomings. These limitations include a restricted scope of mathematical complexity, typically not exceeding lower undergraduate-level mathematics, binary rating protocols and other issues, which makes comprehensive proof-based evaluation suites difficult. We systematically explore these limitations and contend that enhancing the capabilities of large language models, or any forthcoming advancements in AI-based mathematical assistants (copilots or "thought partners"), necessitates a paradigm shift in the design of mathematical datasets and the evaluation criteria of mathematical ability: It is necessary to move away from result-based datasets (theorem statement to theorem proof) and convert the rich facets of mathematical research practice to data LLMs can train on. Examples of these are mathematical workflows (sequences of atomic, potentially subfield-dependent tasks that are often performed when creating new mathematics), which are an important part of the proof-discovery process. Additionally, we advocate for mathematical dataset developers to consider the concept of "motivated proof", introduced by G. P\'olya in 1949, which can serve as a blueprint for datasets that offer a better proof learning signal, alleviating some of the mentioned limitations. Lastly, we introduce math datasheets for datasets, extending the general, dataset-agnostic variants of datasheets: We provide a questionnaire designed specifically for math datasets that we urge dataset creators to include with their datasets. This will make creators aware of potential limitations of their datasets while at the same time making it easy for readers to assess it from the point of view of training and evaluating mathematical copilots.
Fool Me Once? Contrasting Textual and Visual Explanations in a Clinical Decision-Support Setting
Oct 16, 2024



The growing capabilities of AI models are leading to their wider use, including in safety-critical domains. Explainable AI (XAI) aims to make these models safer to use by making their inference process more transparent. However, current explainability methods are seldom evaluated in the way they are intended to be used: by real-world end users. To address this, we conducted a large-scale user study with 85 healthcare practitioners in the context of human-AI collaborative chest X-ray analysis. We evaluated three types of explanations: visual explanations (saliency maps), natural language explanations, and a combination of both modalities. We specifically examined how different explanation types influence users depending on whether the AI advice and explanations are factually correct. We find that text-based explanations lead to significant over-reliance, which is alleviated by combining them with saliency maps. We also observe that the quality of explanations, that is, how much factually correct information they entail, and how much this aligns with AI correctness, significantly impacts the usefulness of the different explanation types.
Affinity-Graph-Guided Contractive Learning for Pretext-Free Medical Image Segmentation with Minimal Annotation
Oct 14, 2024



The combination of semi-supervised learning (SemiSL) and contrastive learning (CL) has been successful in medical image segmentation with limited annotations. However, these works often rely on pretext tasks that lack the specificity required for pixel-level segmentation, and still face overfitting issues due to insufficient supervision signals resulting from too few annotations. Therefore, this paper proposes an affinity-graph-guided semi-supervised contrastive learning framework (Semi-AGCL) by establishing additional affinity-graph-based supervision signals between the student and teacher network, to achieve medical image segmentation with minimal annotations without pretext. The framework first designs an average-patch-entropy-driven inter-patch sampling method, which can provide a robust initial feature space without relying on pretext tasks. Furthermore, the framework designs an affinity-graph-guided loss function, which can improve the quality of the learned representation and the model generalization ability by exploiting the inherent structure of the data, thus mitigating overfitting. Our experiments indicate that with merely 10% of the complete annotation set, our model approaches the accuracy of the fully annotated baseline, manifesting a marginal deviation of only 2.52%. Under the stringent conditions where only 5% of the annotations are employed, our model exhibits a significant enhancement in performance surpassing the second best baseline by 23.09% on the dice metric and achieving an improvement of 26.57% on the notably arduous CRAG and ACDC datasets.