 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection-Fusion for Knowledge Graph Extraction from Videos
Dec 30, 2024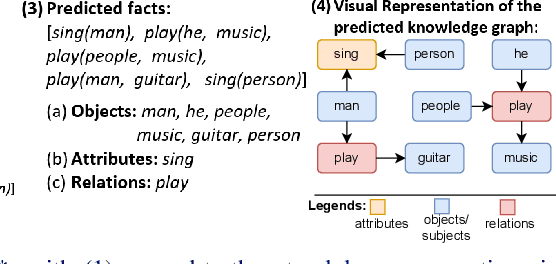
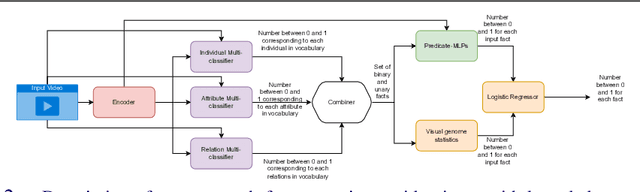

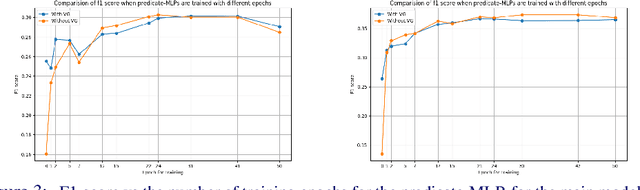
One of the challenging tasks in the field of video understanding is extracting semantic content from video inputs. Most existing systems use language models to describe videos in natural language sentences, but this has several major shortcomings. Such systems can rely too heavily on the language model component and base their output on statistical regularities in natural language text rather than on the visual contents of the video. Additionally, natural language annotations cannot be readily processed by a computer, are difficult to evaluate with performance metrics and cannot be easily translated into a different natural language. In this paper, we propose a method to annotate videos with knowledge graphs, and so avoid these problems. Specifically, we propose a deep-learning-based model for this task that first predicts pairs of individuals and then the relations between them. Additionally, we propose an extension of our model for the inclusion of background knowledge in the construction of knowledge graphs.
GraphRNN Revisited: An Ablation Study and Extensions for Directed Acyclic Graphs
Jul 26, 2023GraphRNN is a deep learning-based architecture proposed by You et al. for learning generative models for graphs. We replicate the results of You et al. using a reproduced implementation of the GraphRNN architecture and evaluate this against baseline models using new metrics. Through an ablation study, we find that the BFS traversal suggested by You et al. to collapse representations of isomorphic graphs contributes significantly to model performance. Additionally, we extend GraphRNN to generate directed acyclic graphs by replacing the BFS traversal with a topological sort. We demonstrate that this method improves significantly over a directed-multiclass variant of GraphRNN on a real-world dataset.