 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Existence and Behaviour of Secondary Attention Sinks
Dec 22, 2025Attention sinks are tokens, often the beginning-of-sequence (BOS) token, that receive disproportionately high attention despite limited semantic relevance. In this work, we identify a class of attention sinks, which we term secondary sinks, that differ fundamentally from the sinks studied in prior works, which we term primary sinks. While prior works have identified that tokens other than BOS can sometimes become sinks, they were found to exhibit properties analogous to the BOS token. Specifically, they emerge at the same layer, persist throughout the network and draw a large amount of attention mass. Whereas, we find the existence of secondary sinks that arise primarily in middle layers and can persist for a variable number of layers, and draw a smaller, but still significant, amount of attention mass. Through extensive experiments across 11 model families, we analyze where these secondary sinks appear, their properties, how they are formed, and their impact on the attention mechanism. Specifically, we show that: (1) these sinks are formed by specific middle-layer MLP modules; these MLPs map token representations to vectors that align with the direction of the primary sink of that layer. (2) The $\ell_2$-norm of these vectors determines the sink score of the secondary sink, and also the number of layers it lasts for, thereby leading to different impacts on the attention mechanisms accordingly. (3) The primary sink weakens in middle layers, coinciding with the emergence of secondary sinks. We observe that in larger-scale models, the location and lifetime of the sinks, together referred to as sink levels, appear in a more deterministic and frequent manner. Specifically, we identify three sink levels in QwQ-32B and six levels in Qwen3-14B.
K*-Means: A Parameter-free Clustering Algorithm
May 17, 2025Clustering is a widely used and powerful machine learning technique, but its effectiveness is often limited by the need to specify the number of clusters, k, or by relying on thresholds that implicitly determine k. We introduce k*-means, a novel clustering algorithm that eliminates the need to set k or any other parameters. Instead, it uses the minimum description length principle to automatically determine the optimal number of clusters, k*, by splitting and merging clusters while also optimising the standard k-means objective. We prove that k*-means is guaranteed to converge and demonstrate experimentally that it significantly outperforms existing methods in scenarios where k is unknown. We also show that it is accurate in estimating k, and that empirically its runtime is competitive with existing methods, and scales well with dataset size.
Modelling Child Learning and Parsing of Long-range Syntactic Dependencies
Mar 17, 2025


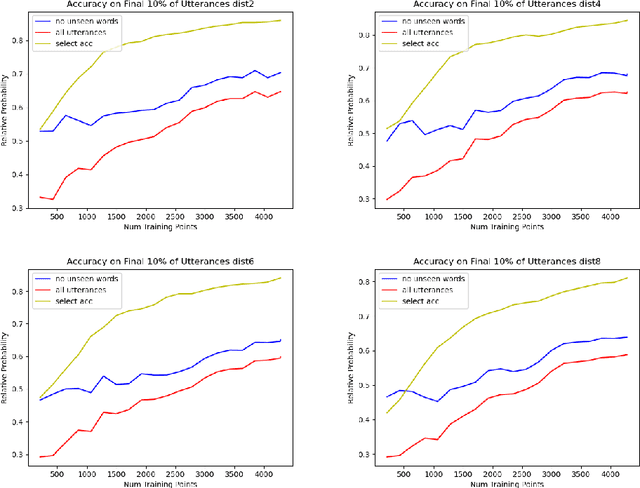
This work develops a probabilistic child language acquisition model to learn a range of linguistic phenonmena, most notably long-range syntactic dependencies of the sort found in object wh-questions, among other constructions. The model is trained on a corpus of real child-directed speech, where each utterance is paired with a logical form as a meaning representation. It then learns both word meanings and language-specific syntax simultaneously. After training, the model can deduce the correct parse tree and word meanings for a given utterance-meaning pair, and can infer the meaning if given only the utterance. The successful modelling of long-range dependencies is theoretically important because it exploits aspects of the model that are, in general, trans-context-free.
Robust detection of overlapping bioacoustic sound events
Mar 04, 2025We propose a method for accurately detecting bioacoustic sound events that is robust to overlapping events, a common issue in domains such as ethology, ecology and conservation. While standard methods employ a frame-based, multi-label approach, we introduce an onset-based detection method which we name Voxaboxen. It takes inspiration from object detection methods in computer vision, but simultaneously takes advantage of recent advances in self-supervised audio encoders. For each time window, Voxaboxen predicts whether it contains the start of a vocalization and how long the vocalization is. It also does the same in reverse, predicting whether each window contains the end of a vocalization, and how long ago it started. The two resulting sets of bounding boxes are then fused using a graph-matching algorithm. We also release a new dataset designed to measure performance on detecting overlapping vocalizations. This consists of recordings of zebra finches annotated with temporally-strong labels and showing frequent overlaps. We test Voxaboxen on seven existing data sets and on our new data set. We compare Voxaboxen to natural baselines and existing sound event detection methods and demonstrate SotA results. Further experiments show that improvements are robust to frequent vocalization overlap.
Parameter-free Video Segmentation for Vision and Language Understanding
Mar 03, 2025



The proliferation of creative video content has driven demand for adapting language models to handle video input and enable multimodal understanding. However, end-to-end models struggle to process long videos due to their size and complexity. An effective alternative is to divide them into smaller chunks to be processed separately, and this motivates a method for choosing where the chunk boundaries should be. In this paper, we propose an algorithm for segmenting videos into contiguous chunks, based on the minimum description length principle, coupled with a dynamic programming search. The algorithm is entirely parameter-free, given feature vectors, not requiring a set threshold or the number or size of chunks to be specified. We show empirically that the breakpoints it produces more accurately approximate scene boundaries in long videos, compared with existing methods for scene detection, even when such methods have access to the true number of scenes. We then showcase this algorithm in two tasks: long video summarization, and retrieval-augmented video question answering. In both cases, scene breaks produced by our algorithm lead to better downstream performance than existing methods for video segmentation.
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Feb 12, 2025
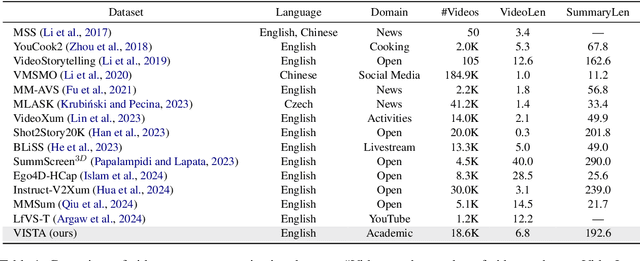

Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
Local Compositional Complexity: How to Detect a Human-readable Messsage
Jan 07, 2025
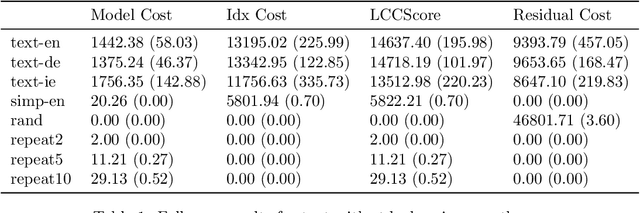

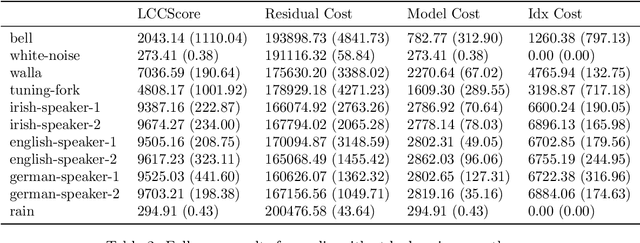
Data complexity is an important concept in the natural sciences and related areas, but lacks a rigorous and computable definition. In this paper, we focus on a particular sense of complexity that is high if the data is structured in a way that could serve to communicate a message. In this sense, human speech, written language, drawings, diagrams and photographs are high complexity, whereas data that is close to uniform throughout or populated by random values is low complexity. We describe a general framework for measuring data complexity based on dividing the shortest description of the data into a structured and an unstructured portion, and taking the size of the former as the complexity score. We outline an application of this framework in statistical mechanics that may allow a more objective characterisation of the macrostate and entropy of a physical system. Then, we derive a more precise and computable definition geared towards human communication, by proposing local compositionality as an appropriate specific structure. We demonstrate experimentally that this method can distinguish meaningful signals from noise or repetitive signals in auditory, visual and text domains, and could potentially help determine whether an extra-terrestrial signal contained a message.
Detection-Fusion for Knowledge Graph Extraction from Videos
Dec 30, 2024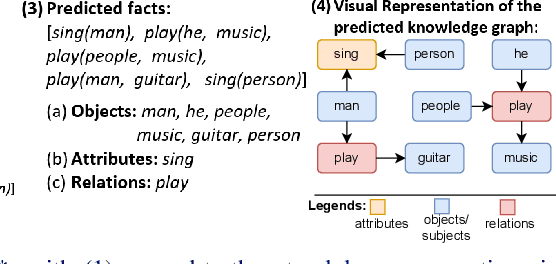
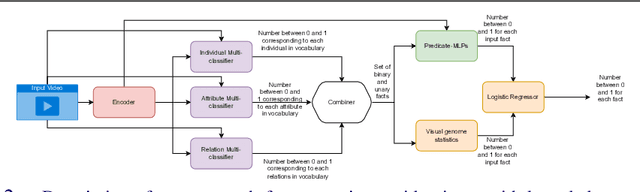

One of the challenging tasks in the field of video understanding is extracting semantic content from video inputs. Most existing systems use language models to describe videos in natural language sentences, but this has several major shortcomings. Such systems can rely too heavily on the language model component and base their output on statistical regularities in natural language text rather than on the visual contents of the video. Additionally, natural language annotations cannot be readily processed by a computer, are difficult to evaluate with performance metrics and cannot be easily translated into a different natural language. In this paper, we propose a method to annotate videos with knowledge graphs, and so avoid these problems. Specifically, we propose a deep-learning-based model for this task that first predicts pairs of individuals and then the relations between them. Additionally, we propose an extension of our model for the inclusion of background knowledge in the construction of knowledge graphs.
$α$-TCVAE: On the relationship between Disentanglement and Diversity
Nov 01, 2024While disentangled representations have shown promise in generative modeling and representation learning, their downstream usefulness remains debated. Recent studies re-defined disentanglement through a formal connection to symmetries, emphasizing the ability to reduce latent domains and consequently enhance generative capabilities. However, from an information theory viewpoint, assigning a complex attribute to a specific latent variable may be infeasible, limiting the applicability of disentangled representations to simple datasets. In this work, we introduce $\alpha$-TCVAE, a variational autoencoder optimized using a novel total correlation (TC) lower bound that maximizes disentanglement and latent variables informativeness. The proposed TC bound is grounded in information theory constructs, generalizes the $\beta$-VAE lower bound, and can be reduced to a convex combination of the known variational information bottleneck (VIB) and conditional entropy bottleneck (CEB) terms. Moreover, we present quantitative analyses that support the idea that disentangled representations lead to better generative capabilities and diversity. Additionally, we perform downstream task experiments from both representation and RL domains to assess our questions from a broader ML perspective. Our results demonstrate that $\alpha$-TCVAE consistently learns more disentangled representations than baselines and generates more diverse observations without sacrificing visual fidelity. Notably, $\alpha$-TCVAE exhibits marked improvements on MPI3D-Real, the most realistic disentangled dataset in our study, confirming its ability to represent complex datasets when maximizing the informativeness of individual variables. Finally, testing the proposed model off-the-shelf on a state-of-the-art model-based RL agent, Director, significantly shows $\alpha$-TCVAE downstream usefulness on the loconav Ant Maze task.
A Language-agnostic Model of Child Language Acquisition
Aug 22, 2024



This work reimplements a recent semantic bootstrapping child-language acquisition model, which was originally designed for English, and trains it to learn a new language: Hebrew. The model learns from pairs of utterances and logical forms as meaning representations, and acquires both syntax and word meanings simultaneously. The results show that the model mostly transfers to Hebrew, but that a number of factors, including the richer morphology in Hebrew, makes the learning slower and less robust. This suggests that a clear direction for future work is to enable the model to leverage the similarities between different word forms.