 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle-Guided Diffusion Models for Partial Differential Equations
Jan 30, 2026We introduce a guided stochastic sampling method that augments sampling from diffusion models with physics-based guidance derived from partial differential equation (PDE) residuals and observational constraints, ensuring generated samples remain physically admissible. We embed this sampling procedure within a new Sequential Monte Carlo (SMC) framework, yielding a scalable generative PDE solver. Across multiple benchmark PDE systems as well as multiphysics and interacting PDE systems, our method produces solution fields with lower numerical error than existing state-of-the-art generative methods.
Diffusion differentiable resampling
Dec 11, 2025This paper is concerned with differentiable resampling in the context of sequential Monte Carlo (e.g., particle filtering). We propose a new informative resampling method that is instantly pathwise differentiable, based on an ensemble score diffusion model. We prove that our diffusion resampling method provides a consistent estimate to the resampling distribution, and we show by experiments that it outperforms the state-of-the-art differentiable resampling methods when used for stochastic filtering and parameter estimation.
PiCSAR: Probabilistic Confidence Selection And Ranking
Aug 29, 2025Best-of-n sampling improves the accuracy of large language models (LLMs) and large reasoning models (LRMs) by generating multiple candidate solutions and selecting the one with the highest reward. The key challenge for reasoning tasks is designing a scoring function that can identify correct reasoning chains without access to ground-truth answers. We propose Probabilistic Confidence Selection And Ranking (PiCSAR): a simple, training-free method that scores each candidate generation using the joint log-likelihood of the reasoning and final answer. The joint log-likelihood of the reasoning and final answer naturally decomposes into reasoning confidence and answer confidence. PiCSAR achieves substantial gains across diverse benchmarks (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least 2x fewer samples in 16 out of 20 comparisons. Our analysis reveals that correct reasoning chains exhibit significantly higher reasoning and answer confidence, justifying the effectiveness of PiCSAR.
CROP: Circuit Retrieval and Optimization with Parameter Guidance using LLMs
Jul 02, 2025Modern very large-scale integration (VLSI) design requires the implementation of integrated circuits using electronic design automation (EDA) tools. Due to the complexity of EDA algorithms, the vast parameter space poses a huge challenge to chip design optimization, as the combination of even moderate numbers of parameters creates an enormous solution space to explore. Manual parameter selection remains industrial practice despite being excessively laborious and limited by expert experience. To address this issue, we present CROP, the first large language model (LLM)-powered automatic VLSI design flow tuning framework. Our approach includes: (1) a scalable methodology for transforming RTL source code into dense vector representations, (2) an embedding-based retrieval system for matching designs with semantically similar circuits, and (3) a retrieval-augmented generation (RAG)-enhanced LLM-guided parameter search system that constrains the search process with prior knowledge from similar designs. Experiment results demonstrate CROP's ability to achieve superior quality-of-results (QoR) with fewer iterations than existing approaches on industrial designs, including a 9.9% reduction in power consumption.
Iterative Multilingual Spectral Attribute Erasure
Jun 12, 2025Multilingual representations embed words with similar meanings to share a common semantic space across languages, creating opportunities to transfer debiasing effects between languages. However, existing methods for debiasing are unable to exploit this opportunity because they operate on individual languages. We present Iterative Multilingual Spectral Attribute Erasure (IMSAE), which identifies and mitigates joint bias subspaces across multiple languages through iterative SVD-based truncation. Evaluating IMSAE across eight languages and five demographic dimensions, we demonstrate its effectiveness in both standard and zero-shot settings, where target language data is unavailable, but linguistically similar languages can be used for debiasing. Our comprehensive experiments across diverse language models (BERT, LLaMA, Mistral) show that IMSAE outperforms traditional monolingual and cross-lingual approaches while maintaining model utility.
PersonaLens: A Benchmark for Personalization Evaluation in Conversational AI Assistants
Jun 11, 2025Large language models (LLMs) have advanced conversational AI assistants. However, systematically evaluating how well these assistants apply personalization--adapting to individual user preferences while completing tasks--remains challenging. Existing personalization benchmarks focus on chit-chat, non-conversational tasks, or narrow domains, failing to capture the complexities of personalized task-oriented assistance. To address this, we introduce PersonaLens, a comprehensive benchmark for evaluating personalization in task-oriented AI assistants. Our benchmark features diverse user profiles equipped with rich preferences and interaction histories, along with two specialized LLM-based agents: a user agent that engages in realistic task-oriented dialogues with AI assistants, and a judge agent that employs the LLM-as-a-Judge paradigm to assess personalization, response quality, and task success. Through extensive experiments with current LLM assistants across diverse tasks, we reveal significant variability in their personalization capabilities, providing crucial insights for advancing conversational AI systems.
Humble your Overconfident Networks: Unlearning Overfitting via Sequential Monte Carlo Tempered Deep Ensembles
May 16, 2025Sequential Monte Carlo (SMC) methods offer a principled approach to Bayesian uncertainty quantification but are traditionally limited by the need for full-batch gradient evaluations. We introduce a scalable variant by incorporating Stochastic Gradient Hamiltonian Monte Carlo (SGHMC) proposals into SMC, enabling efficient mini-batch based sampling. Our resulting SMCSGHMC algorithm outperforms standard stochastic gradient descent (SGD) and deep ensembles across image classification, out-of-distribution (OOD) detection, and transfer learning tasks. We further show that SMCSGHMC mitigates overfitting and improves calibration, providing a flexible, scalable pathway for converting pretrained neural networks into well-calibrated Bayesian models.
Utilising Gradient-Based Proposals Within Sequential Monte Carlo Samplers for Training of Partial Bayesian Neural Networks
May 01, 2025Partial Bayesian neural networks (pBNNs) have been shown to perform competitively with fully Bayesian neural networks while only having a subset of the parameters be stochastic. Using sequential Monte Carlo (SMC) samplers as the inference method for pBNNs gives a non-parametric probabilistic estimation of the stochastic parameters, and has shown improved performance over parametric methods. In this paper we introduce a new SMC-based training method for pBNNs by utilising a guided proposal and incorporating gradient-based Markov kernels, which gives us better scalability on high dimensional problems. We show that our new method outperforms the state-of-the-art in terms of predictive performance and optimal loss. We also show that pBNNs scale well with larger batch sizes, resulting in significantly reduced training times and often better performance.
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Feb 12, 2025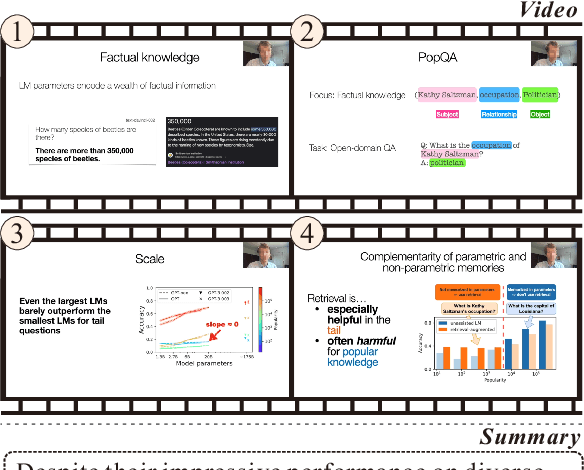
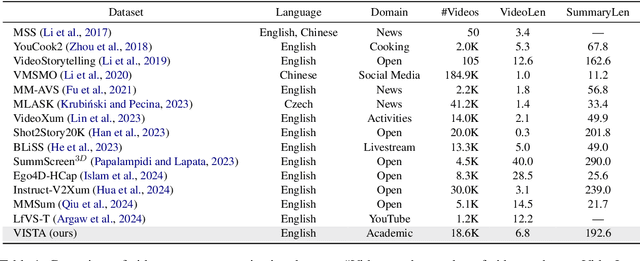

Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
Solving Linear-Gaussian Bayesian Inverse Problems with Decoupled Diffusion Sequential Monte Carlo
Feb 10, 2025A recent line of research has exploited pre-trained generative diffusion models as priors for solving Bayesian inverse problems. We contribute to this research direction by designing a sequential Monte Carlo method for linear-Gaussian inverse problems which builds on ``decoupled diffusion", where the generative process is designed such that larger updates to the sample are possible. The method is asymptotically exact and we demonstrate the effectiveness of our Decoupled Diffusion Sequential Monte Carlo (DDSMC) algorithm on both synthetic data and image reconstruction tasks. Further, we demonstrate how the approach can be extended to discrete data.