 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisTime: Distribution-based Time Representation for Video Large Language Models
May 30, 2025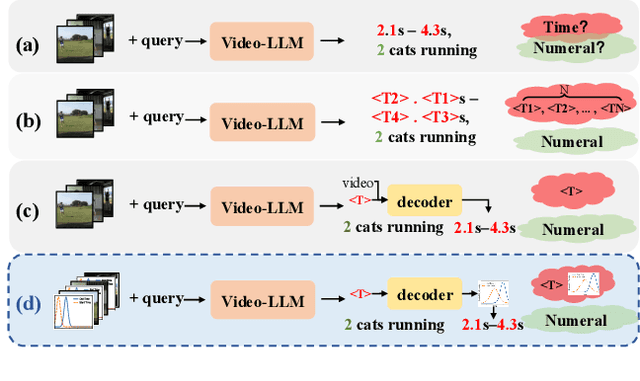
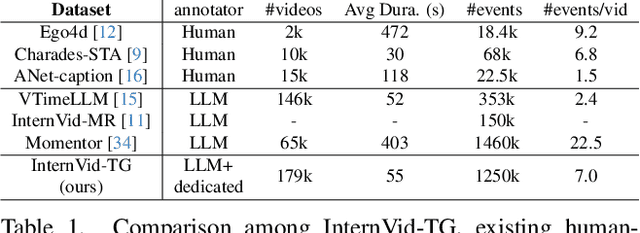
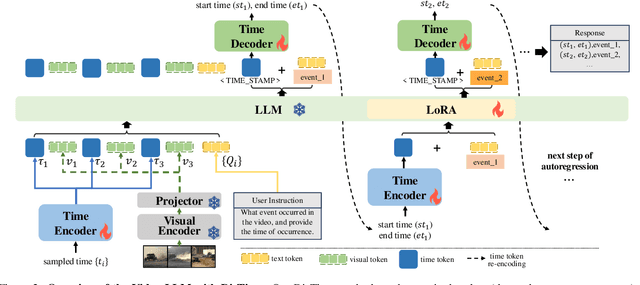
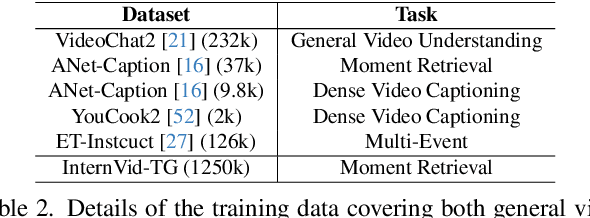
Despite advances in general video understanding, Video Large Language Models (Video-LLMs) face challenges in precise temporal localization due to discrete time representations and limited temporally aware datasets. Existing methods for temporal expression either conflate time with text-based numerical values, add a series of dedicated temporal tokens, or regress time using specialized temporal grounding heads. To address these issues, we introduce DisTime, a lightweight framework designed to enhance temporal comprehension in Video-LLMs. DisTime employs a learnable token to create a continuous temporal embedding space and incorporates a Distribution-based Time Decoder that generates temporal probability distributions, effectively mitigating boundary ambiguities and maintaining temporal continuity. Additionally, the Distribution-based Time Encoder re-encodes timestamps to provide time markers for Video-LLMs. To overcome temporal granularity limitations in existing datasets, we propose an automated annotation paradigm that combines the captioning capabilities of Video-LLMs with the localization expertise of dedicated temporal models. This leads to the creation of InternVid-TG, a substantial dataset with 1.25M temporally grounded events across 179k videos, surpassing ActivityNet-Caption by 55 times. Extensive experiments demonstrate that DisTime achieves state-of-the-art performance across benchmarks in three time-sensitive tasks while maintaining competitive performance in Video QA tasks. Code and data are released at https://github.com/josephzpng/DisTime.
InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
Dec 18, 2024Boosted by Multi-modal Large Language Models (MLLMs), text-guided universal segmentation models for the image and video domains have made rapid progress recently. However, these methods are often developed separately for specific domains, overlooking the similarities in task settings and solutions across these two areas. In this paper, we define the union of referring segmentation and reasoning segmentation at both the image and video levels as Instructed Visual Segmentation (IVS). Correspondingly, we propose InstructSeg, an end-to-end segmentation pipeline equipped with MLLMs for IVS. Specifically, we employ an object-aware video perceiver to extract temporal and object information from reference frames, facilitating comprehensive video understanding. Additionally, we introduce vision-guided multi-granularity text fusion to better integrate global and detailed text information with fine-grained visual guidance. By leveraging multi-task and end-to-end training, InstructSeg demonstrates superior performance across diverse image and video segmentation tasks, surpassing both segmentation specialists and MLLM-based methods with a single model. Our code is available at https://github.com/congvvc/InstructSeg.
LinVT: Empower Your Image-level Large Language Model to Understand Videos
Dec 06, 2024Large Language Models (LLMs) have been widely used in various tasks, motivating us to develop an LLM-based assistant for videos. Instead of training from scratch, we propose a module to transform arbitrary well-trained image-based LLMs into video-LLMs (after being trained on video data). To better adapt image-LLMs for processing videos, we introduce two design principles: linear transformation to preserve the original visual-language alignment and representative information condensation from redundant video content. Guided by these principles, we propose a plug-and-play Linear Video Tokenizer(LinVT), which enables existing image-LLMs to understand videos. We benchmark LinVT with six recent visual LLMs: Aquila, Blip-3, InternVL2, Mipha, Molmo and Qwen2-VL, showcasing the high compatibility of LinVT. LinVT-based LLMs achieve state-of-the-art performance across various video benchmarks, illustrating the effectiveness of LinVT in multi-modal video understanding.
UniMD: Towards Unifying Moment Retrieval and Temporal Action Detection
Apr 07, 2024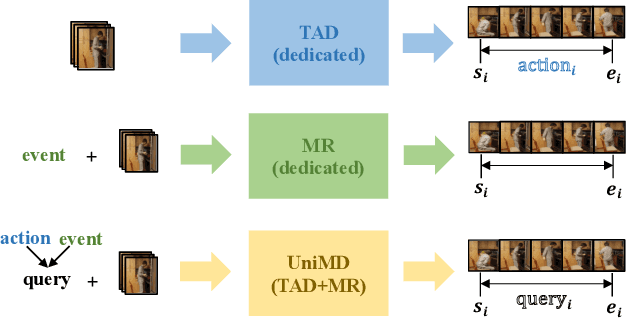
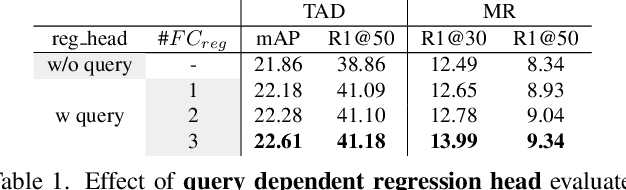
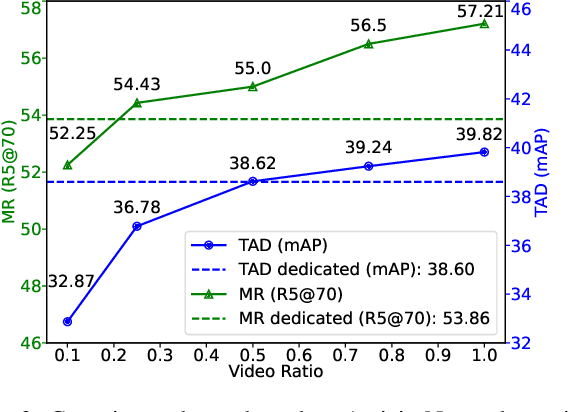
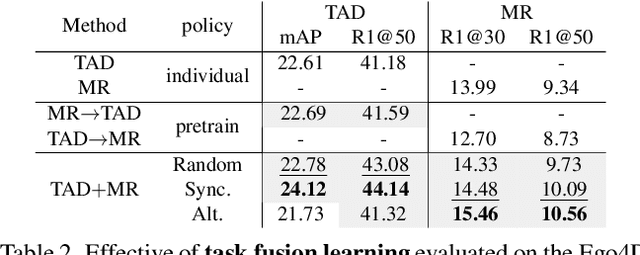
Temporal Action Detection (TAD) focuses on detecting pre-defined actions, while Moment Retrieval (MR) aims to identify the events described by open-ended natural language within untrimmed videos. Despite that they focus on different events, we observe they have a significant connection. For instance, most descriptions in MR involve multiple actions from TAD. In this paper, we aim to investigate the potential synergy between TAD and MR. Firstly, we propose a unified architecture, termed Unified Moment Detection (UniMD), for both TAD and MR. It transforms the inputs of the two tasks, namely actions for TAD or events for MR, into a common embedding space, and utilizes two novel query-dependent decoders to generate a uniform output of classification score and temporal segments. Secondly, we explore the efficacy of two task fusion learning approaches, pre-training and co-training, in order to enhance the mutual benefits between TAD and MR. Extensive experiments demonstrate that the proposed task fusion learning scheme enables the two tasks to help each other and outperform the separately trained counterparts. Impressively, UniMD achieves state-of-the-art results on three paired datasets Ego4D, Charades-STA, and ActivityNet. Our code will be released at https://github.com/yingsen1/UniMD.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.