 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-domain performance analysis with scores tailored to user preferences
Dec 09, 2025The performance of algorithms, methods, and models tends to depend heavily on the distribution of cases on which they are applied, this distribution being specific to the applicative domain. After performing an evaluation in several domains, it is highly informative to compute a (weighted) mean performance and, as shown in this paper, to scrutinize what happens during this averaging. To achieve this goal, we adopt a probabilistic framework and consider a performance as a probability measure (e.g., a normalized confusion matrix for a classification task). It appears that the corresponding weighted mean is known to be the summarization, and that only some remarkable scores assign to the summarized performance a value equal to a weighted arithmetic mean of the values assigned to the domain-specific performances. These scores include the family of ranking scores, a continuum parameterized by user preferences, and that the weights to consider in the arithmetic mean depend on the user preferences. Based on this, we rigorously define four domains, named easiest, most difficult, preponderant, and bottleneck domains, as functions of user preferences. After establishing the theory in a general setting, regardless of the task, we develop new visual tools for two-class classification.
A Methodology to Evaluate Strategies Predicting Rankings on Unseen Domains
May 21, 2025


Frequently, multiple entities (methods, algorithms, procedures, solutions, etc.) can be developed for a common task and applied across various domains that differ in the distribution of scenarios encountered. For example, in computer vision, the input data provided to image analysis methods depend on the type of sensor used, its location, and the scene content. However, a crucial difficulty remains: can we predict which entities will perform best in a new domain based on assessments on known domains, without having to carry out new and costly evaluations? This paper presents an original methodology to address this question, in a leave-one-domain-out fashion, for various application-specific preferences. We illustrate its use with 30 strategies to predict the rankings of 40 entities (unsupervised background subtraction methods) on 53 domains (videos).
Foundations of the Theory of Performance-Based Ranking
Dec 05, 2024
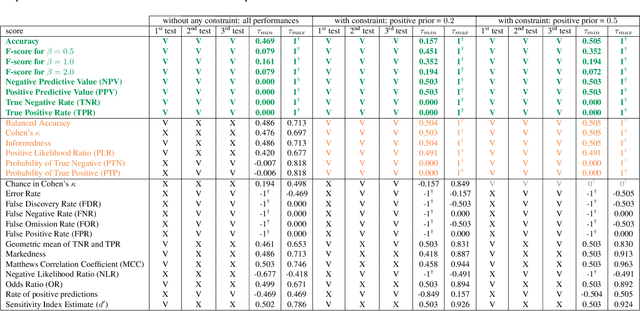
Ranking entities such as algorithms, devices, methods, or models based on their performances, while accounting for application-specific preferences, is a challenge. To address this challenge, we establish the foundations of a universal theory for performance-based ranking. First, we introduce a rigorous framework built on top of both the probability and order theories. Our new framework encompasses the elements necessary to (1) manipulate performances as mathematical objects, (2) express which performances are worse than or equivalent to others, (3) model tasks through a variable called satisfaction, (4) consider properties of the evaluation, (5) define scores, and (6) specify application-specific preferences through a variable called importance. On top of this framework, we propose the first axiomatic definition of performance orderings and performance-based rankings. Then, we introduce a universal parametric family of scores, called ranking scores, that can be used to establish rankings satisfying our axioms, while considering application-specific preferences. Finally, we show, in the case of two-class classification, that the family of ranking scores encompasses well-known performance scores, including the accuracy, the true positive rate (recall, sensitivity), the true negative rate (specificity), the positive predictive value (precision), and F1. However, we also show that some other scores commonly used to compare classifiers are unsuitable to derive performance orderings satisfying the axioms. Therefore, this paper provides the computer vision and machine learning communities with a rigorous framework for evaluating and ranking entities.
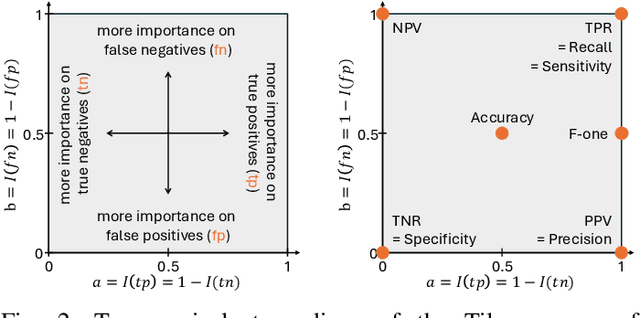
The Tile: A 2D Map of Ranking Scores for Two-Class Classification
Dec 05, 2024



In the computer vision and machine learning communities, as well as in many other research domains, rigorous evaluation of any new method, including classifiers, is essential. One key component of the evaluation process is the ability to compare and rank methods. However, ranking classifiers and accurately comparing their performances, especially when taking application-specific preferences into account, remains challenging. For instance, commonly used evaluation tools like Receiver Operating Characteristic (ROC) and Precision/Recall (PR) spaces display performances based on two scores. Hence, they are inherently limited in their ability to compare classifiers across a broader range of scores and lack the capability to establish a clear ranking among classifiers. In this paper, we present a novel versatile tool, named the Tile, that organizes an infinity of ranking scores in a single 2D map for two-class classifiers, including common evaluation scores such as the accuracy, the true positive rate, the positive predictive value, Jaccard's coefficient, and all F-beta scores. Furthermore, we study the properties of the underlying ranking scores, such as the influence of the priors or the correspondences with the ROC space, and depict how to characterize any other score by comparing them to the Tile. Overall, we demonstrate that the Tile is a powerful tool that effectively captures all the rankings in a single visualization and allows interpreting them.
SoccerNet 2024 Challenges Results
Sep 16, 2024

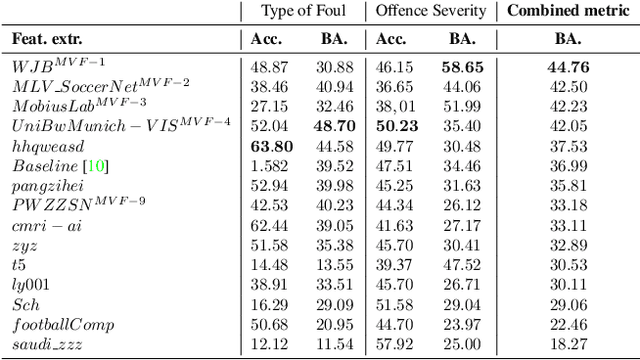
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Ordinal Pooling
Sep 03, 2021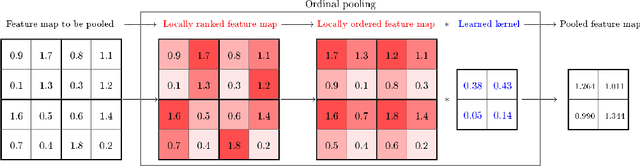


In the framework of convolutional neural networks, downsampling is often performed with an average-pooling, where all the activations are treated equally, or with a max-pooling operation that only retains an element with maximum activation while discarding the others. Both of these operations are restrictive and have previously been shown to be sub-optimal. To address this issue, a novel pooling scheme, named\emph{ ordinal pooling}, is introduced in this work. Ordinal pooling rearranges all the elements of a pooling region in a sequence and assigns a different weight to each element based upon its order in the sequence. These weights are used to compute the pooling operation as a weighted sum of the rearranged elements of the pooling region. They are learned via a standard gradient-based training, allowing to learn a behavior anywhere in the spectrum of average-pooling to max-pooling in a differentiable manner. Our experiments suggest that it is advantageous for the networks to perform different types of pooling operations within a pooling layer and that a hybrid behavior between average- and max-pooling is often beneficial. More importantly, they also demonstrate that ordinal pooling leads to consistent improvements in the accuracy over average- or max-pooling operations while speeding up the training and alleviating the issue of the choice of the pooling operations and activation functions to be used in the networks. In particular, ordinal pooling mainly helps on lightweight or quantized deep learning architectures, as typically considered e.g. for embedded applications.
* This is the authors' preprint version of a paper published at BMVC 2019. Please cite it as follows: A. Deli\`ege, M. Istasse, A. Kumar, C. De Vleeschouwer and M. Van Droogenbroeck, "Ordinal Pooling", in British Machine Vision Conference, 2019
Ghost Loss to Question the Reliability of Training Data
Sep 03, 2021


Supervised image classification problems rely on training data assumed to have been correctly annotated; this assumption underpins most works in the field of deep learning. In consequence, during its training, a network is forced to match the label provided by the annotator and is not given the flexibility to choose an alternative to inconsistencies that it might be able to detect. Therefore, erroneously labeled training images may end up ``correctly'' classified in classes which they do not actually belong to. This may reduce the performances of the network and thus incite to build more complex networks without even checking the quality of the training data. In this work, we question the reliability of the annotated datasets. For that purpose, we introduce the notion of ghost loss, which can be seen as a regular loss that is zeroed out for some predicted values in a deterministic way and that allows the network to choose an alternative to the given label without being penalized. After a proof of concept experiment, we use the ghost loss principle to detect confusing images and erroneously labeled images in well-known training datasets (MNIST, Fashion-MNIST, SVHN, CIFAR10) and we provide a new tool, called sanity matrix, for summarizing these confusions.
* This is the authors' preprint version of a paper published in IEEE Access in 2020. Please cite it as follows: A. Deli\`ege, A. Cioppa and M. Van Droogenbroeck, "Ghost Loss to Question the Reliability of Training Data", in IEEE Access, vol. 8, pp. 44774-44782, 2020, doi: 10.1109/ACCESS.2020.2978283
Camera Calibration and Player Localization in SoccerNet-v2 and Investigation of their Representations for Action Spotting
Apr 19, 2021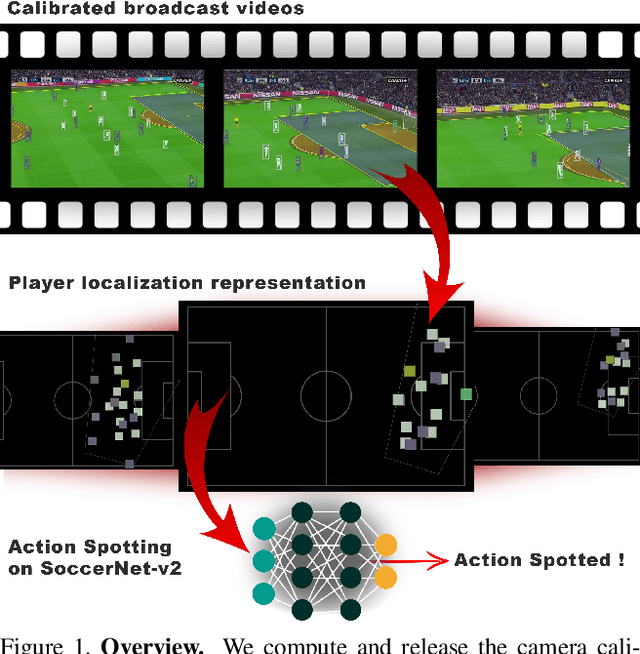

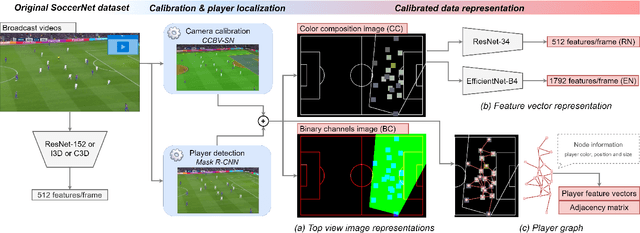
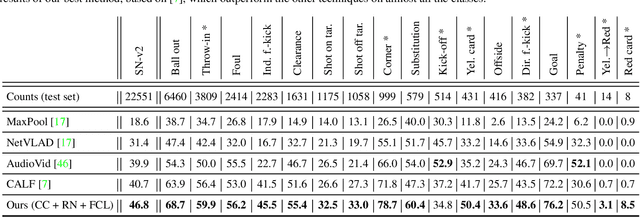
Soccer broadcast video understanding has been drawing a lot of attention in recent years within data scientists and industrial companies. This is mainly due to the lucrative potential unlocked by effective deep learning techniques developed in the field of computer vision. In this work, we focus on the topic of camera calibration and on its current limitations for the scientific community. More precisely, we tackle the absence of a large-scale calibration dataset and of a public calibration network trained on such a dataset. Specifically, we distill a powerful commercial calibration tool in a recent neural network architecture on the large-scale SoccerNet dataset, composed of untrimmed broadcast videos of 500 soccer games. We further release our distilled network, and leverage it to provide 3 ways of representing the calibration results along with player localization. Finally, we exploit those representations within the current best architecture for the action spotting task of SoccerNet-v2, and achieve new state-of-the-art performances.