 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation-Efficient Vision-Language Model Adaptation to the Polish Language Using the LLaVA Framework
Feb 17, 2026Most vision-language models (VLMs) are trained on English-centric data, limiting their performance in other languages and cultural contexts. This restricts their usability for non-English-speaking users and hinders the development of multimodal systems that reflect diverse linguistic and cultural realities. In this work, we reproduce and adapt the LLaVA-Next methodology to create a set of Polish VLMs. We rely on a fully automated pipeline for translating and filtering existing multimodal datasets, and complement this with synthetic Polish data for OCR and culturally specific tasks. Despite relying almost entirely on automatic translation and minimal manual intervention to the training data, our approach yields strong results: we observe a +9.5% improvement over LLaVA-1.6-Vicuna-13B on a Polish-adapted MMBench, along with higher-quality captions in generative evaluations, as measured by human annotators in terms of linguistic correctness. These findings highlight that large-scale automated translation, combined with lightweight filtering, can effectively bootstrap high-quality multimodal models for low-resource languages. Some challenges remain, particularly in cultural coverage and evaluation. To facilitate further research, we make our models and evaluation dataset publicly available.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025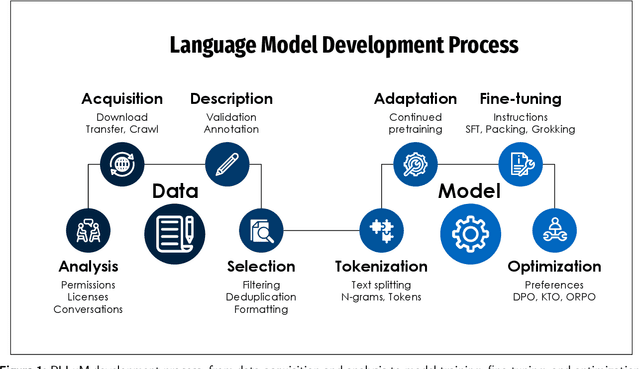
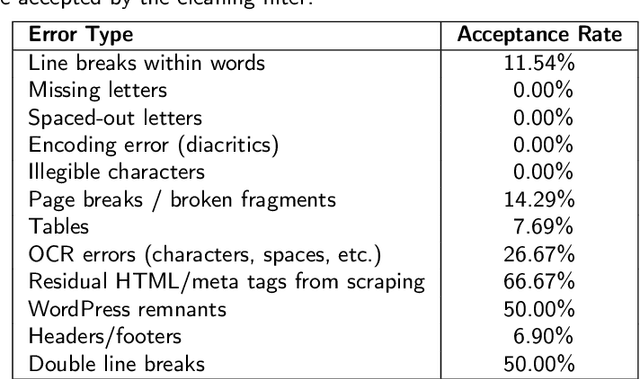
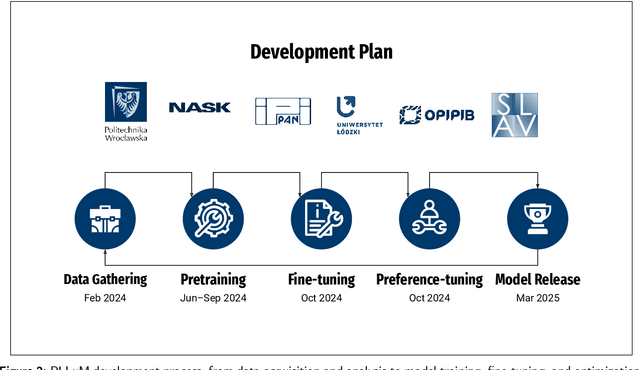

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Rethinking the Evaluation of Alignment Methods: Insights into Diversity, Generalisation, and Safety
Sep 16, 2025Large language models (LLMs) require careful alignment to balance competing objectives - factuality, safety, conciseness, proactivity, and diversity. Existing studies focus on individual techniques or specific dimensions, lacking a holistic assessment of the inherent trade-offs. We propose a unified evaluation framework that compares LLM alignment methods (PPO, DPO, ORPO, KTO) across these five axes, using both in-distribution and out-of-distribution datasets. Leveraging a specialized LLM-as-Judge prompt, validated through human studies, we reveal that DPO and KTO excel in factual accuracy, PPO and DPO lead in safety, and PPO best balances conciseness with proactivity. Our findings provide insights into trade-offs of common alignment methods, guiding the development of more balanced and reliable LLMs.
Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models
Jun 09, 2025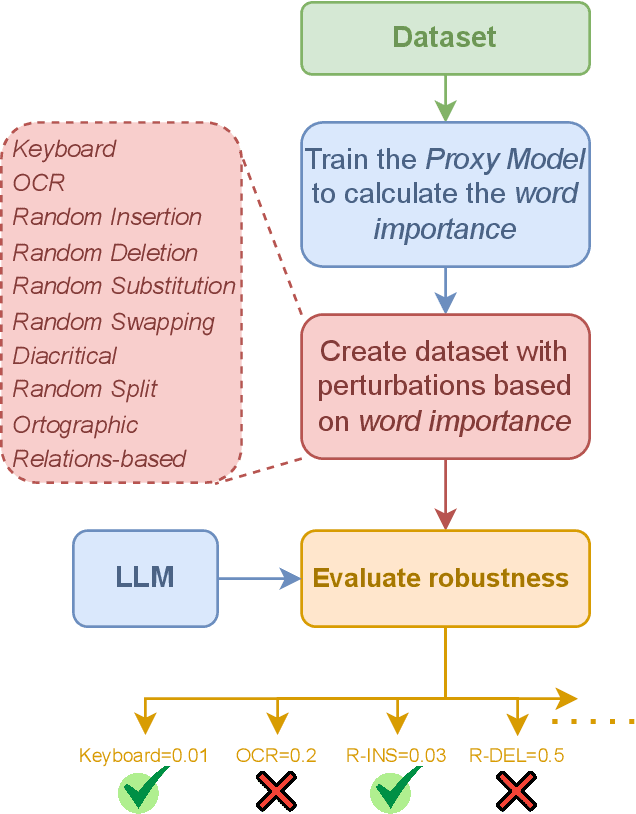
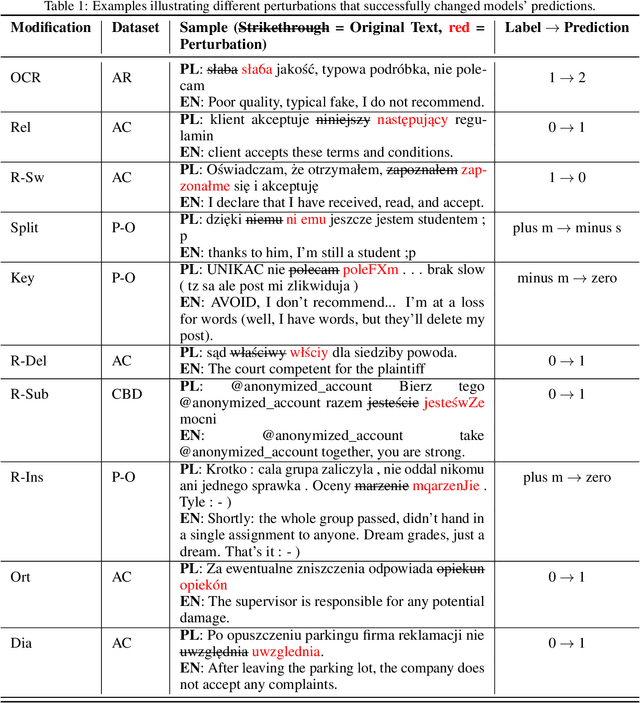
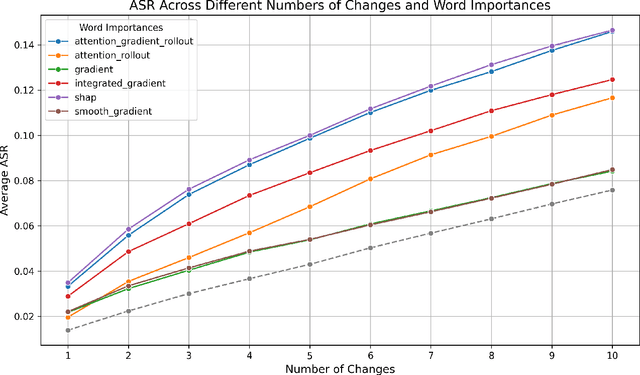
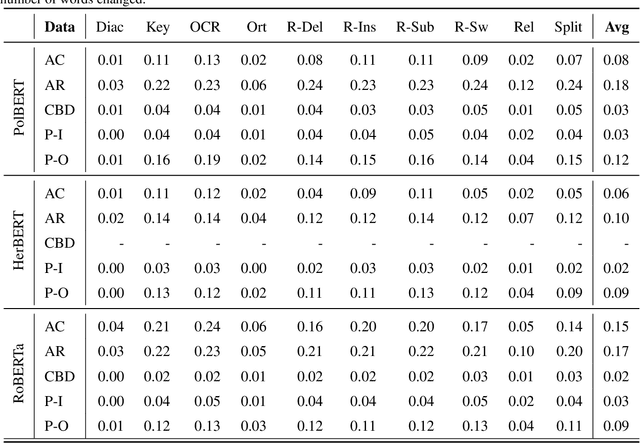
Large language models (LLMs) have demonstrated impressive capabilities across various natural language processing (NLP) tasks in recent years. However, their susceptibility to jailbreaks and perturbations necessitates additional evaluations. Many LLMs are multilingual, but safety-related training data contains mainly high-resource languages like English. This can leave them vulnerable to perturbations in low-resource languages such as Polish. We show how surprisingly strong attacks can be cheaply created by altering just a few characters and using a small proxy model for word importance calculation. We find that these character and word-level attacks drastically alter the predictions of different LLMs, suggesting a potential vulnerability that can be used to circumvent their internal safety mechanisms. We validate our attack construction methodology on Polish, a low-resource language, and find potential vulnerabilities of LLMs in this language. Additionally, we show how it can be extended to other languages. We release the created datasets and code for further research.
SoccerNet 2024 Challenges Results
Sep 16, 2024

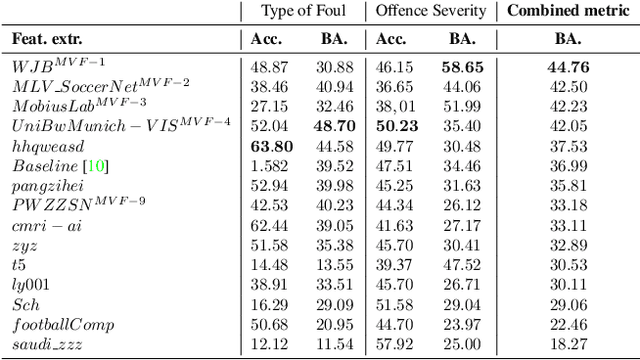
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Improving Object Detection Quality in Football Through Super-Resolution Techniques
Jan 31, 2024This study explores the potential of super-resolution techniques in enhancing object detection accuracy in football. Given the sport's fast-paced nature and the critical importance of precise object (e.g. ball, player) tracking for both analysis and broadcasting, super-resolution could offer significant improvements. We investigate how advanced image processing through super-resolution impacts the accuracy and reliability of object detection algorithms in processing football match footage. Our methodology involved applying state-of-the-art super-resolution techniques to a diverse set of football match videos from SoccerNet, followed by object detection using Faster R-CNN. The performance of these algorithms, both with and without super-resolution enhancement, was rigorously evaluated in terms of detection accuracy. The results indicate a marked improvement in object detection accuracy when super-resolution preprocessing is applied. The improvement of object detection through the integration of super-resolution techniques yields significant benefits, especially for low-resolution scenarios, with a notable 12\% increase in mean Average Precision (mAP) at an IoU (Intersection over Union) range of 0.50:0.95 for 320x240 size images when increasing the resolution fourfold using RLFN. As the dimensions increase, the magnitude of improvement becomes more subdued; however, a discernible improvement in the quality of detection is consistently evident. Additionally, we discuss the implications of these findings for real-time sports analytics, player tracking, and the overall viewing experience. The study contributes to the growing field of sports technology by demonstrating the practical benefits and limitations of integrating super-resolution techniques in football analytics and broadcasting.
Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives
Sep 21, 2023



Action scene understanding in soccer is a challenging task due to the complex and dynamic nature of the game, as well as the interactions between players. This article provides a comprehensive overview of this task divided into action recognition, spotting, and spatio-temporal action localization, with a particular emphasis on the modalities used and multimodal methods. We explore the publicly available data sources and metrics used to evaluate models' performance. The article reviews recent state-of-the-art methods that leverage deep learning techniques and traditional methods. We focus on multimodal methods, which integrate information from multiple sources, such as video and audio data, and also those that represent one source in various ways. The advantages and limitations of methods are discussed, along with their potential for improving the accuracy and robustness of models. Finally, the article highlights some of the open research questions and future directions in the field of soccer action recognition, including the potential for multimodal methods to advance this field. Overall, this survey provides a valuable resource for researchers interested in the field of action scene understanding in soccer.
Automating the Analysis of Institutional Design in International Agreements
May 26, 2023This paper explores the automatic knowledge extraction of formal institutional design - norms, rules, and actors - from international agreements. The focus was to analyze the relationship between the visibility and centrality of actors in the formal institutional design in regulating critical aspects of cultural heritage relations. The developed tool utilizes techniques such as collecting legal documents, annotating them with Institutional Grammar, and using graph analysis to explore the formal institutional design. The system was tested against the 2003 UNESCO Convention for the Safeguarding of the Intangible Cultural Heritage.
Distance Metric Learning Loss Functions in Few-Shot Scenarios of Supervised Language Models Fine-Tuning
Nov 28, 2022This paper presents an analysis regarding an influence of the Distance Metric Learning (DML) loss functions on the supervised fine-tuning of the language models for classification tasks. We experimented with known datasets from SentEval Transfer Tasks. Our experiments show that applying the DML loss function can increase performance on downstream classification tasks of RoBERTa-large models in few-shot scenarios. Models fine-tuned with the use of SoftTriple loss can achieve better results than models with a standard categorical cross-entropy loss function by about 2.89 percentage points from 0.04 to 13.48 percentage points depending on the training dataset. Additionally, we accomplished a comprehensive analysis with explainability techniques to assess the models' reliability and explain their results.
Revisiting Distance Metric Learning for Few-Shot Natural Language Classification
Nov 28, 2022Distance Metric Learning (DML) has attracted much attention in image processing in recent years. This paper analyzes its impact on supervised fine-tuning language models for Natural Language Processing (NLP) classification tasks under few-shot learning settings. We investigated several DML loss functions in training RoBERTa language models on known SentEval Transfer Tasks datasets. We also analyzed the possibility of using proxy-based DML losses during model inference. Our systematic experiments have shown that under few-shot learning settings, particularly proxy-based DML losses can positively affect the fine-tuning and inference of a supervised language model. Models tuned with a combination of CCE (categorical cross-entropy loss) and ProxyAnchor Loss have, on average, the best performance and outperform models with only CCE by about 3.27 percentage points -- up to 10.38 percentage points depending on the training dataset.