 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Misinformation Detection: Performance-Efficiency Trade-offs
Apr 09, 2026The rapid spread of online misinformation has led to increasingly complex detection models, including large language models and hybrid architectures. However, their computational cost and deployment limitations raise concerns about practical applicability. In this work, we benchmark graph neural networks (GNNs) against non-graph-based machine learning methods under controlled and comparable conditions. We evaluate lightweight GNN architectures (GCN, GraphSAGE, GAT, ChebNet) against Logistic Regression, Support Vector Machines, and Multilayer Perceptrons across seven public datasets in English, Indonesian, and Polish. All models use identical TF-IDF features to isolate the impact of relational structure. Performance is measured using F1 score, with inference time reported to assess efficiency. GNNs consistently outperform non-graph baselines across all datasets. For example, GraphSAGE achieves 96.8% F1 on Kaggle and 91.9% on WELFake, compared to 73.2% and 66.8% for MLP, respectively. On COVID-19, GraphSAGE reaches 90.5% F1 vs. 74.9%, while ChebNet attains 79.1% vs. 66.4% on FakeNewsNet. These gains are achieved with comparable or lower inference times. Overall, the results show that classic GNNs remain effective and efficient, challenging the need for increasingly complex architectures in misinformation detection.
Clickbait detection: quick inference with maximum impact
Apr 09, 2026We propose a lightweight hybrid approach to clickbait detection that combines OpenAI semantic embeddings with six compact heuristic features capturing stylistic and informational cues. To improve efficiency, embeddings are reduced using PCA and evaluated with XGBoost, GraphSAGE, and GCN classifiers. While the simplified feature design yields slightly lower F1-scores, graph-based models achieve competitive performance with substantially reduced inference time. High ROC--AUC values further indicate strong discrimination capability, supporting reliable detection of clickbait headlines under varying decision thresholds.
LLM Essay Scoring Under Holistic and Analytic Rubrics: Prompt Effects and Bias
Mar 31, 2026Despite growing interest in using Large Language Models (LLMs) for educational assessment, it remains unclear how closely they align with human scoring. We present a systematic evaluation of instruction-tuned LLMs across three open essay-scoring datasets (ASAP 2.0, ELLIPSE, and DREsS) that cover both holistic and analytic scoring. We analyze agreement with human consensus scores, directional bias, and the stability of bias estimates. Our results show that strong open-weight models achieve moderate to high agreement with humans on holistic scoring (Quadratic Weighted Kappa about 0.6), but this does not transfer uniformly to analytic scoring. In particular, we observe large and stable negative directional bias on Lower-Order Concern (LOC) traits, such as Grammar and Conventions, meaning that models often score these traits more harshly than human raters. We also find that concise keyword-based prompts generally outperform longer rubric-style prompts in multi-trait analytic scoring. To quantify the amount of data needed to detect these systematic deviations, we compute the minimum sample size at which a 95% bootstrap confidence interval for the mean bias excludes zero. This analysis shows that LOC bias is often detectable with very small validation sets, whereas Higher-Order Concern (HOC) traits typically require much larger samples. These findings support a bias-correction-first deployment strategy: instead of relying on raw zero-shot scores, systematic score offsets can be estimated and corrected using small human-labeled bias-estimation sets, without requiring large-scale fine-tuning.
On the Effectiveness of LLM-Specific Fine-Tuning for Detecting AI-Generated Text
Jan 27, 2026The rapid progress of large language models has enabled the generation of text that closely resembles human writing, creating challenges for authenticity verification in education, publishing, and digital security. Detecting AI-generated text has therefore become a crucial technical and ethical issue. This paper presents a comprehensive study of AI-generated text detection based on large-scale corpora and novel training strategies. We introduce a 1-billion-token corpus of human-authored texts spanning multiple genres and a 1.9-billion-token corpus of AI-generated texts produced by prompting a variety of LLMs across diverse domains. Using these resources, we develop and evaluate numerous detection models and propose two novel training paradigms: Per LLM and Per LLM family fine-tuning. Across a 100-million-token benchmark covering 21 large language models, our best fine-tuned detector achieves up to $99.6\%$ token-level accuracy, substantially outperforming existing open-source baselines.
Evaluating LLM-Generated Q&A Test: a Student-Centered Study
May 10, 2025This research prepares an automatic pipeline for generating reliable question-answer (Q&A) tests using AI chatbots. We automatically generated a GPT-4o-mini-based Q&A test for a Natural Language Processing course and evaluated its psychometric and perceived-quality metrics with students and experts. A mixed-format IRT analysis showed that the generated items exhibit strong discrimination and appropriate difficulty, while student and expert star ratings reflect high overall quality. A uniform DIF check identified two items for review. These findings demonstrate that LLM-generated assessments can match human-authored tests in psychometric performance and user satisfaction, illustrating a scalable approach to AI-assisted assessment development.
Applying Text Mining to Analyze Human Question Asking in Creativity Research
Jan 03, 2025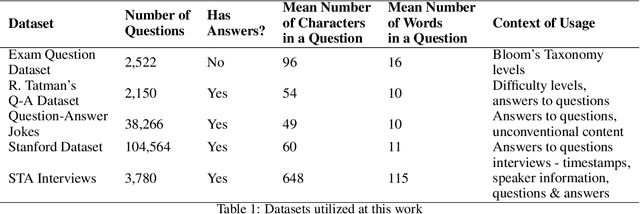
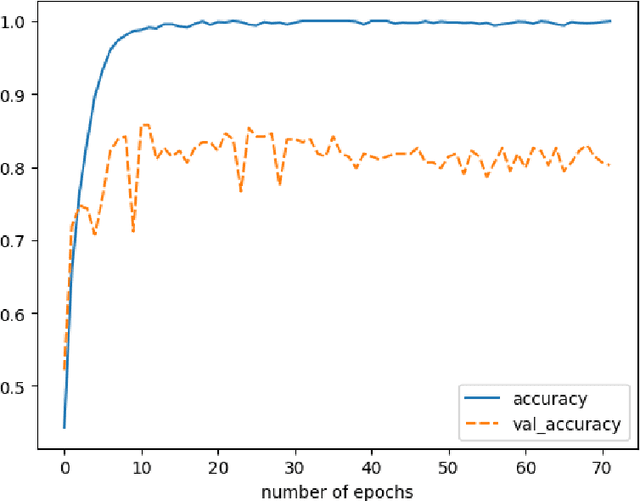


Creativity relates to the ability to generate novel and effective ideas in the areas of interest. How are such creative ideas generated? One possible mechanism that supports creative ideation and is gaining increased empirical attention is by asking questions. Question asking is a likely cognitive mechanism that allows defining problems, facilitating creative problem solving. However, much is unknown about the exact role of questions in creativity. This work presents an attempt to apply text mining methods to measure the cognitive potential of questions, taking into account, among others, (a) question type, (b) question complexity, and (c) the content of the answer. This contribution summarizes the history of question mining as a part of creativity research, along with the natural language processing methods deemed useful or helpful in the study. In addition, a novel approach is proposed, implemented, and applied to five datasets. The experimental results obtained are comprehensively analyzed, suggesting that natural language processing has a role to play in creative research.
Consumer Transactions Simulation through Generative Adversarial Networks
Aug 07, 2024In the rapidly evolving domain of large-scale retail data systems, envisioning and simulating future consumer transactions has become a crucial area of interest. It offers significant potential to fortify demand forecasting and fine-tune inventory management. This paper presents an innovative application of Generative Adversarial Networks (GANs) to generate synthetic retail transaction data, specifically focusing on a novel system architecture that combines consumer behavior modeling with stock-keeping unit (SKU) availability constraints to address real-world assortment optimization challenges. We diverge from conventional methodologies by integrating SKU data into our GAN architecture and using more sophisticated embedding methods (e.g., hyper-graphs). This design choice enables our system to generate not only simulated consumer purchase behaviors but also reflects the dynamic interplay between consumer behavior and SKU availability -- an aspect often overlooked, among others, because of data scarcity in legacy retail simulation models. Our GAN model generates transactions under stock constraints, pioneering a resourceful experimental system with practical implications for real-world retail operation and strategy. Preliminary results demonstrate enhanced realism in simulated transactions measured by comparing generated items with real ones using methods employed earlier in related studies. This underscores the potential for more accurate predictive modeling.
Fake News Detection: It's All in the Data!
Jul 02, 2024This comprehensive survey serves as an indispensable resource for researchers embarking on the journey of fake news detection. By highlighting the pivotal role of dataset quality and diversity, it underscores the significance of these elements in the effectiveness and robustness of detection models. The survey meticulously outlines the key features of datasets, various labeling systems employed, and prevalent biases that can impact model performance. Additionally, it addresses critical ethical issues and best practices, offering a thorough overview of the current state of available datasets. Our contribution to this field is further enriched by the provision of GitHub repository, which consolidates publicly accessible datasets into a single, user-friendly portal. This repository is designed to facilitate and stimulate further research and development efforts aimed at combating the pervasive issue of fake news.
Intelligent Interface: Enhancing Lecture Engagement with Didactic Activity Summaries
Jun 20, 2024Recently, multiple applications of machine learning have been introduced. They include various possibilities arising when image analysis methods are applied to, broadly understood, video streams. In this context, a novel tool, developed for academic educators to enhance the teaching process by automating, summarizing, and offering prompt feedback on conducting lectures, has been developed. The implemented prototype utilizes machine learning-based techniques to recognise selected didactic and behavioural teachers' features within lecture video recordings. Specifically, users (teachers) can upload their lecture videos, which are preprocessed and analysed using machine learning models. Next, users can view summaries of recognized didactic features through interactive charts and tables. Additionally, stored ML-based prediction results support comparisons between lectures based on their didactic content. In the developed application text-based models trained on lecture transcriptions, with enhancements to the transcription quality, by adopting an automatic speech recognition solution are applied. Furthermore, the system offers flexibility for (future) integration of new/additional machine-learning models and software modules for image and video analysis.
Mining United Nations General Assembly Debates
Jun 19, 2024


This project explores the application of Natural Language Processing (NLP) techniques to analyse United Nations General Assembly (UNGA) speeches. Using NLP allows for the efficient processing and analysis of large volumes of textual data, enabling the extraction of semantic patterns, sentiment analysis, and topic modelling. Our goal is to deliver a comprehensive dataset and a tool (interface with descriptive statistics and automatically extracted topics) from which political scientists can derive insights into international relations and have the opportunity to have a nuanced understanding of global diplomatic discourse.