 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the Analysis of Institutional Design in International Agreements
May 26, 2023This paper explores the automatic knowledge extraction of formal institutional design - norms, rules, and actors - from international agreements. The focus was to analyze the relationship between the visibility and centrality of actors in the formal institutional design in regulating critical aspects of cultural heritage relations. The developed tool utilizes techniques such as collecting legal documents, annotating them with Institutional Grammar, and using graph analysis to explore the formal institutional design. The system was tested against the 2003 UNESCO Convention for the Safeguarding of the Intangible Cultural Heritage.
Entity Graph Extraction from Legal Acts -- a Prototype for a Use Case in Policy Design Analysis
Sep 02, 2022
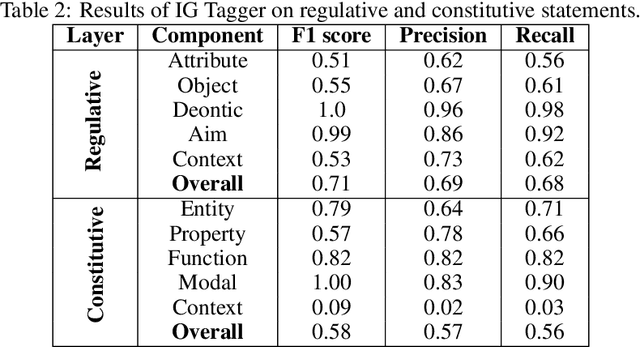
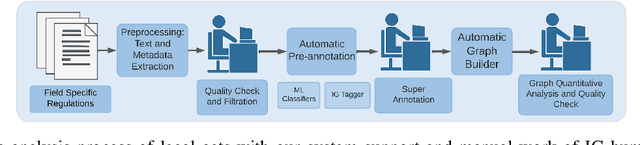
This paper presents research on a prototype developed to serve the quantitative study of public policy design. This sub-discipline of political science focuses on identifying actors, relations between them, and tools at their disposal in health, environmental, economic, and other policies. Our system aims to automate the process of gathering legal documents, annotating them with Institutional Grammar, and using hypergraphs to analyse inter-relations between crucial entities. Our system is tested against the UNESCO Convention for the Safeguarding of the Intangible Cultural Heritage from 2003, a legal document regulating essential aspects of international relations securing cultural heritage.
Does a Technique for Building Multimodal Representation Matter? -- Comparative Analysis
Jun 09, 2022
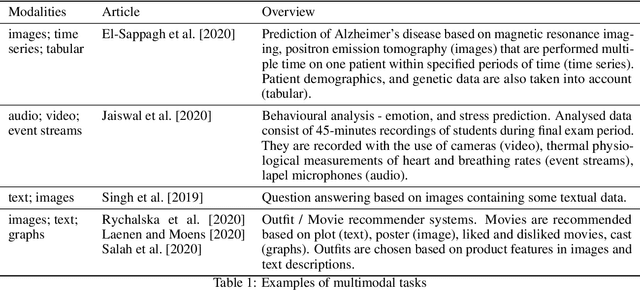
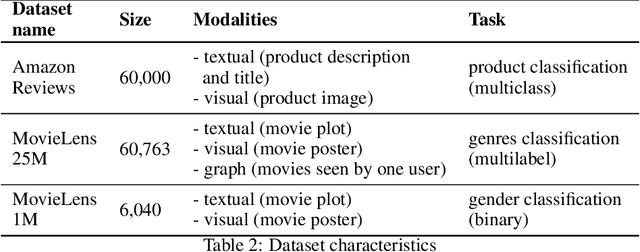
Creating a meaningful representation by fusing single modalities (e.g., text, images, or audio) is the core concept of multimodal learning. Although several techniques for building multimodal representations have been proven successful, they have not been compared yet. Therefore it has been ambiguous which technique can be expected to yield the best results in a given scenario and what factors should be considered while choosing such a technique. This paper explores the most common techniques for building multimodal data representations -- the late fusion, the early fusion, and the sketch, and compares them in classification tasks. Experiments are conducted on three datasets: Amazon Reviews, MovieLens25M, and MovieLens1M datasets. In general, our results confirm that multimodal representations are able to boost the performance of unimodal models from 0.919 to 0.969 of accuracy on Amazon Reviews and 0.907 to 0.918 of AUC on MovieLens25M. However, experiments on both MovieLens datasets indicate the importance of the meaningful input data to the given task. In this article, we show that the choice of the technique for building multimodal representation is crucial to obtain the highest possible model's performance, that comes with the proper modalities combination. Such choice relies on: the influence that each modality has on the analyzed machine learning (ML) problem; the type of the ML task; the memory constraints while training and predicting phase.
Spoiler in a Textstack: How Much Can Transformers Help?
Dec 24, 2021
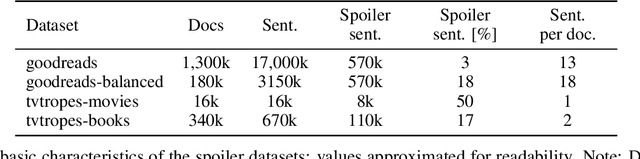
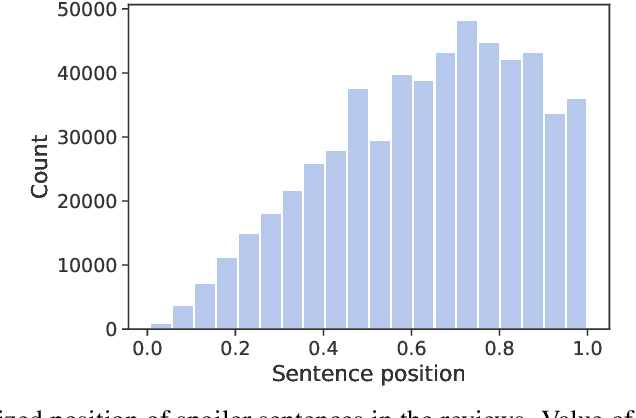
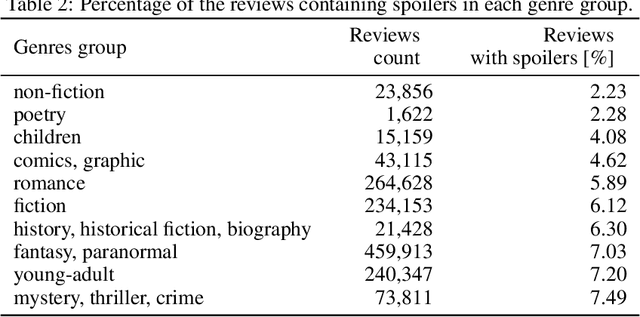
This paper presents our research regarding spoiler detection in reviews. In this use case, we describe the method of fine-tuning and organizing the available text-based model tasks with the latest deep learning achievements and techniques to interpret the models' results. Until now, spoiler research has been rarely described in the literature. We tested the transfer learning approach and different latest transformer architectures on two open datasets with annotated spoilers (ROC AUC above 81\% on TV Tropes Movies dataset, and Goodreads dataset above 88\%). We also collected data and assembled a new dataset with fine-grained annotations. To that end, we employed interpretability techniques and measures to assess the models' reliability and explain their results.