 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes a Technique for Building Multimodal Representation Matter? -- Comparative Analysis
Jun 09, 2022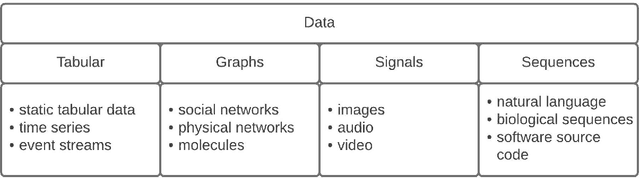
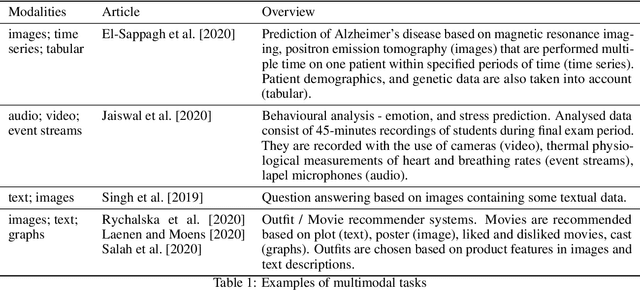
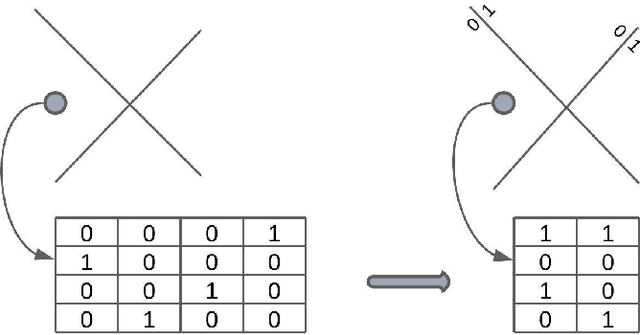
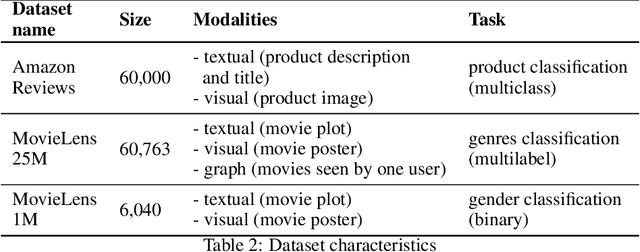
Creating a meaningful representation by fusing single modalities (e.g., text, images, or audio) is the core concept of multimodal learning. Although several techniques for building multimodal representations have been proven successful, they have not been compared yet. Therefore it has been ambiguous which technique can be expected to yield the best results in a given scenario and what factors should be considered while choosing such a technique. This paper explores the most common techniques for building multimodal data representations -- the late fusion, the early fusion, and the sketch, and compares them in classification tasks. Experiments are conducted on three datasets: Amazon Reviews, MovieLens25M, and MovieLens1M datasets. In general, our results confirm that multimodal representations are able to boost the performance of unimodal models from 0.919 to 0.969 of accuracy on Amazon Reviews and 0.907 to 0.918 of AUC on MovieLens25M. However, experiments on both MovieLens datasets indicate the importance of the meaningful input data to the given task. In this article, we show that the choice of the technique for building multimodal representation is crucial to obtain the highest possible model's performance, that comes with the proper modalities combination. Such choice relies on: the influence that each modality has on the analyzed machine learning (ML) problem; the type of the ML task; the memory constraints while training and predicting phase.
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022
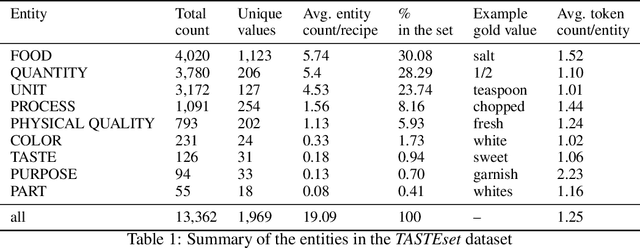
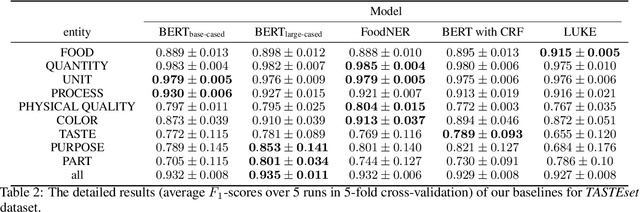
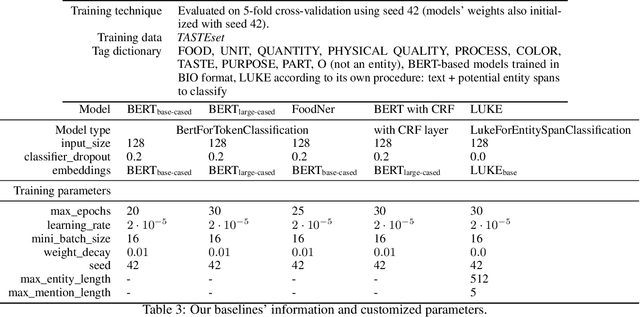
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.