 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME-MT Dataset: Formality Awareness Made Easy for Machine Translation Purposes
May 20, 2024



People use language for various purposes. Apart from sharing information, individuals may use it to express emotions or to show respect for another person. In this paper, we focus on the formality level of machine-generated translations and present FAME-MT -- a dataset consisting of 11.2 million translations between 15 European source languages and 8 European target languages classified to formal and informal classes according to target sentence formality. This dataset can be used to fine-tune machine translation models to ensure a given formality level for each European target language considered. We describe the dataset creation procedure, the analysis of the dataset's quality showing that FAME-MT is a reliable source of language register information, and we present a publicly available proof-of-concept machine translation model that uses the dataset to steer the formality level of the translation. Currently, it is the largest dataset of formality annotations, with examples expressed in 112 European language pairs. The dataset is published online: https://github.com/laniqo-public/fame-mt/ .
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022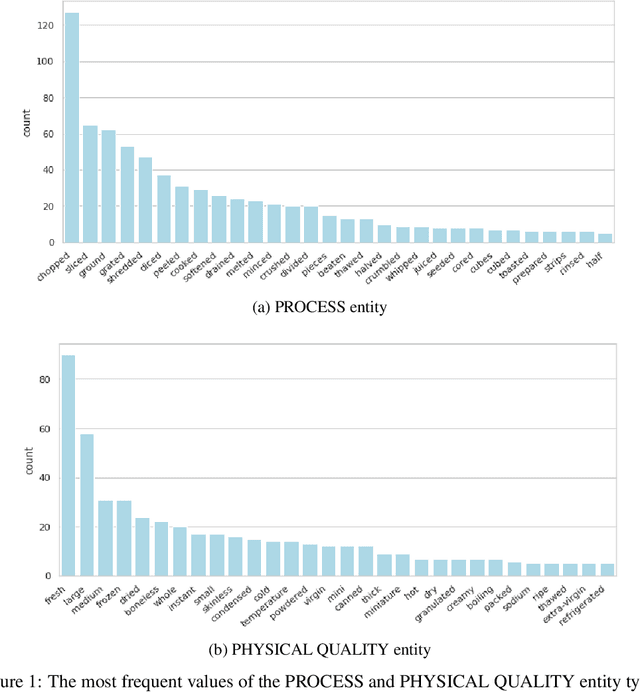
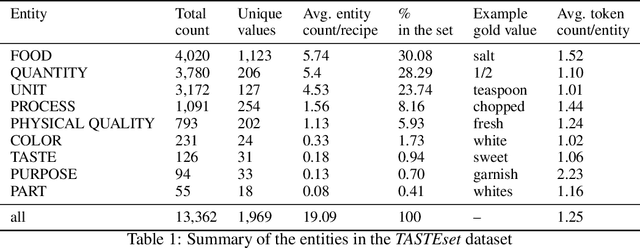
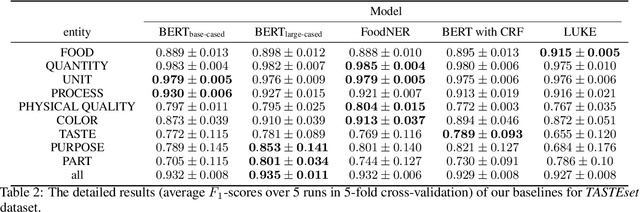
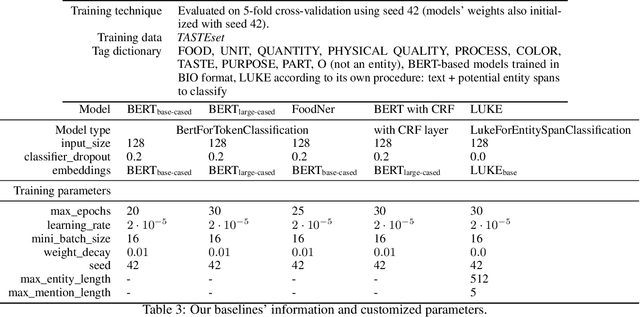
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.
BigCQ: A large-scale synthetic dataset of competency question patterns formalized into SPARQL-OWL query templates
May 20, 2021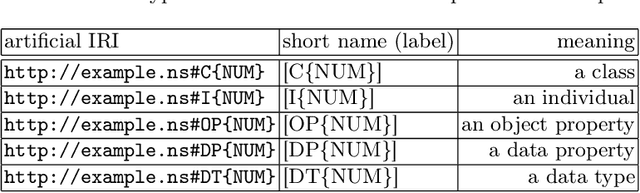
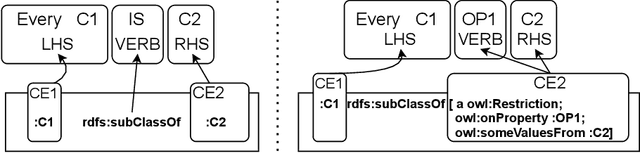

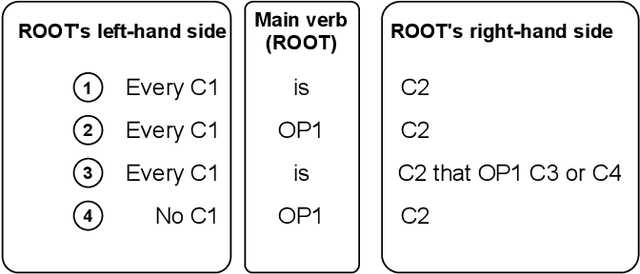
Competency Questions (CQs) are used in many ontology engineering methodologies to collect requirements and track the completeness and correctness of an ontology being constructed. Although they are frequently suggested by ontology engineering methodologies, the publicly available datasets of CQs and their formalizations in ontology query languages are very scarce. Since first efforts to automate processes utilizing CQs are being made, it is of high importance to provide large and diverse datasets to fuel these solutions. In this paper, we present BigCQ, the biggest dataset of CQ templates with their formalizations into SPARQL-OWL query templates. BigCQ is created automatically from a dataset of frequently used axiom shapes. These pairs of CQ templates and query templates can be then materialized as actual CQs and SPARQL-OWL queries if filled with resource labels and IRIs from a given ontology. We describe the dataset in detail, provide a description of the process leading to the creation of the dataset and analyze how well the dataset covers real-world examples. We also publish the dataset as well as scripts transforming axiom shapes into pairs of CQ patterns and SPARQL-OWL templates, to make engineers able to adapt the process to their particular needs.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019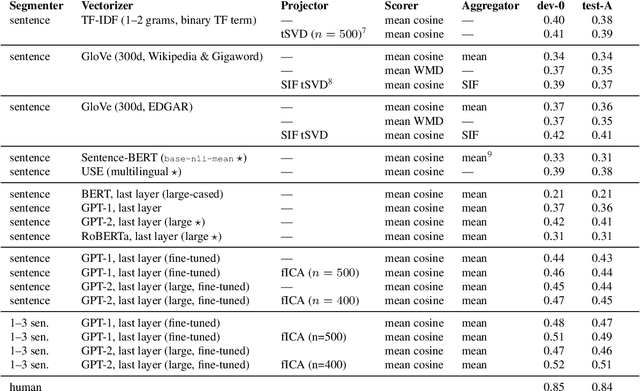
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.