 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCpdf: Building a High Quality Corpus for Visually Rich Documents from Web Crawl Data
Apr 28, 2023In recent years, the field of document understanding has progressed a lot. A significant part of this progress has been possible thanks to the use of language models pretrained on large amounts of documents. However, pretraining corpora used in the domain of document understanding are single domain, monolingual, or nonpublic. Our goal in this paper is to propose an efficient pipeline for creating a big-scale, diverse, multilingual corpus of PDF files from all over the Internet using Common Crawl, as PDF files are the most canonical types of documents as considered in document understanding. We analysed extensively all of the steps of the pipeline and proposed a solution which is a trade-off between data quality and processing time. We also share a CCpdf corpus in a form or an index of PDF files along with a script for downloading them, which produces a collection useful for language model pretraining. The dataset and tools published with this paper offer researchers the opportunity to develop even better multilingual language models.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019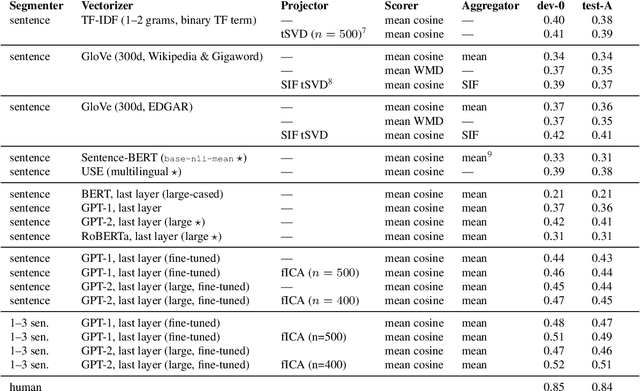
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.