 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplicaAI at SemEval-2020 Task 11: On RoBERTa-CRF, Span CLS and Whether Self-Training Helps Them
May 16, 2020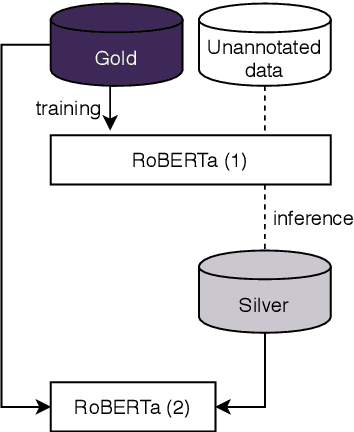
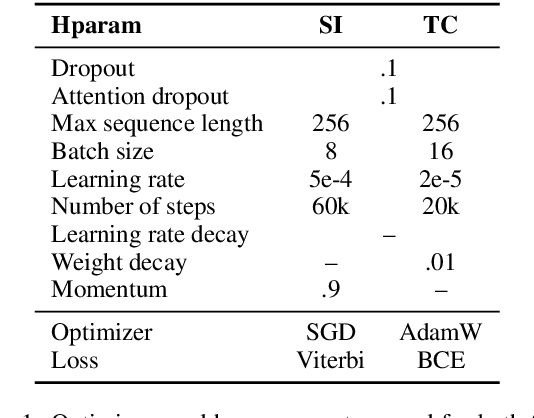

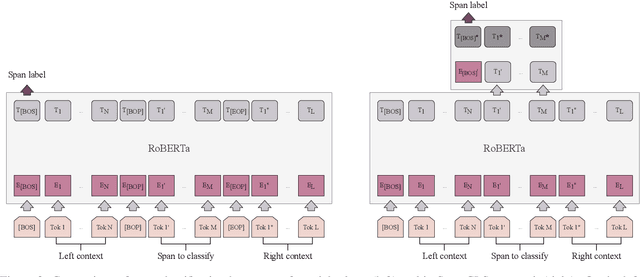
This paper presents the winning system for the propaganda Technique Classification (TC) task and the second-placed system for the propaganda Span Identification (SI) task. The purpose of TC task was to identify an applied propaganda technique given propaganda text fragment. The goal of SI task was to find specific text fragments which contain at least one propaganda technique. Both of the developed solutions used semi-supervised learning technique of self-training. Interestingly, although CRF is barely used with transformer-based language models, the SI task was approached with RoBERTa-CRF architecture. An ensemble of RoBERTa-based models was proposed for the TC task, with one of them making use of Span CLS layers we introduce in the present paper. In addition to describing the submitted systems, an impact of architectural decisions and training schemes is investigated along with remarks regarding training models of the same or better quality with lower computational budget. Finally, the results of error analysis are presented.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019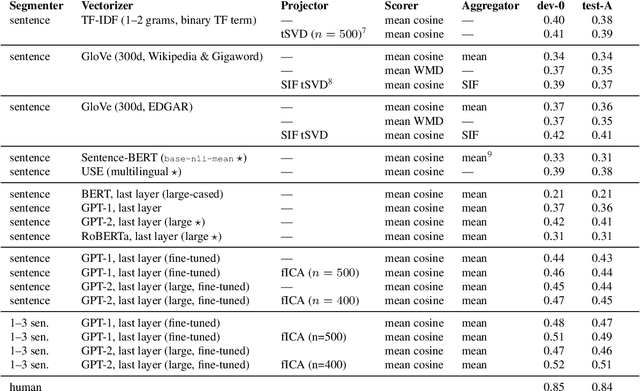
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.