 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
Searching for Legal Clauses by Analogy. Few-shot Semantic Retrieval Shared Task
Nov 10, 2019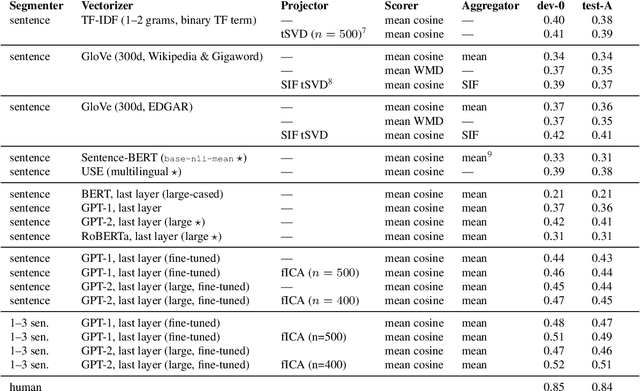
We introduce a novel shared task for semantic retrieval from legal texts, where one is expected to perform a so-called contract discovery -- extract specified legal clauses from documents given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and legal information extraction shared tasks. Its specification is followed with evaluation of multiple k-NN based solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pre-trained encoders fail to provide satisfactory results on the task proposed, whereas Language Model based solutions perform well, especially when unsupervised fine-tuning is applied. In addition to the ablation studies, the questions regarding relevant text fragments detection accuracy depending on number of examples available were addressed. In addition to dataset and reference results, legal-specialized LMs were made publicly available.