 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic-TILT. Business Document Understanding at Sub-Billion Scale
Aug 08, 2024The vast portion of workloads employing LLMs involves answering questions grounded on PDF or scan content. We introduce the Arctic-TILT achieving accuracy on par with models 1000$\times$ its size on these use cases. It can be fine-tuned and deployed on a single 24GB GPU, lowering operational costs while processing Visually Rich Documents with up to 400k tokens. The model establishes state-of-the-art results on seven diverse Document Understanding benchmarks, as well as provides reliable confidence scores and quick inference, which are essential for processing files in large-scale or time-sensitive enterprise environments.
How to Learn a Useful Critic? Model-based Action-Gradient-Estimator Policy Optimization
Apr 29, 2020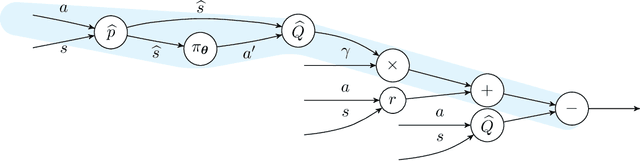
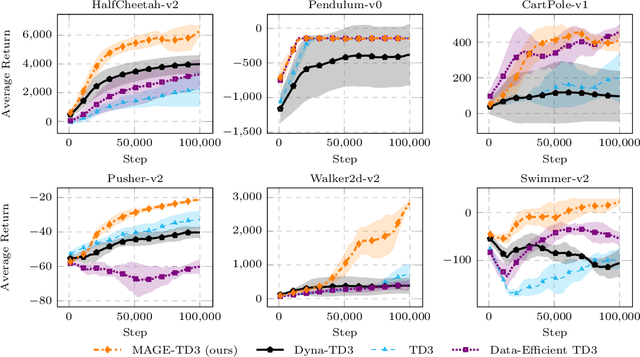
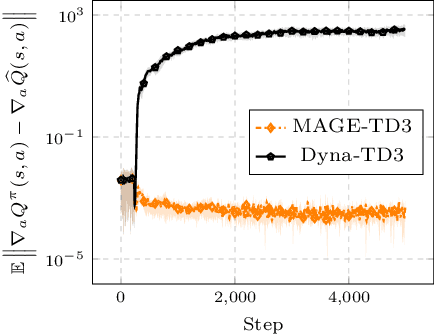
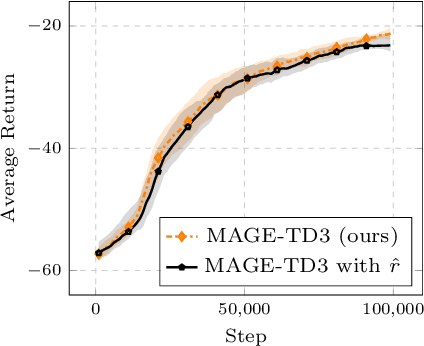
Deterministic-policy actor-critic algorithms for continuous control improve the actor by plugging its actions into the critic and ascending the action-value gradient, which is obtained by chaining the actor's Jacobian matrix with the gradient of the critic w.r.t. input actions. However, instead of gradients, the critic is, typically, only trained to accurately predict expected returns, which, on their own, are useless for policy optimization. In this paper, we propose MAGE, a model-based actor-critic algorithm, grounded in the theory of policy gradients, which explicitly learns the action-value gradient. MAGE backpropagates through the learned dynamics to compute gradient targets in temporal difference learning, leading to a critic tailored for policy improvement. On a set of MuJoCo continuous-control tasks, we demonstrate the efficiency of the algorithm with respect to model-free and model-based state-of-the-art baselines.
Training Agents using Upside-Down Reinforcement Learning
Dec 05, 2019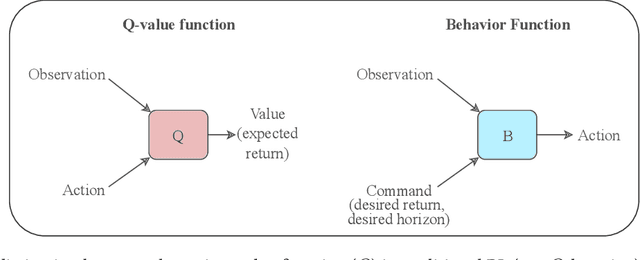



Traditional Reinforcement Learning (RL) algorithms either predict rewards with value functions or maximize them using policy search. We study an alternative: Upside-Down Reinforcement Learning (Upside-Down RL or UDRL), that solves RL problems primarily using supervised learning techniques. Many of its main principles are outlined in a companion report [34]. Here we present the first concrete implementation of UDRL and demonstrate its feasibility on certain episodic learning problems. Experimental results show that its performance can be surprisingly competitive with, and even exceed that of traditional baseline algorithms developed over decades of research.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
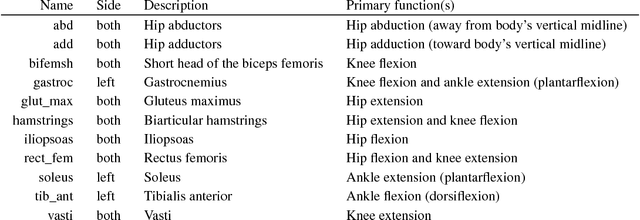
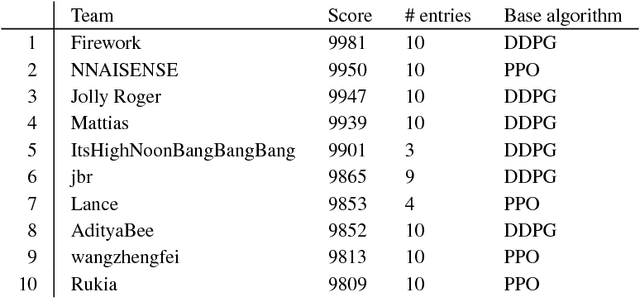

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Model-Based Active Exploration
Oct 29, 2018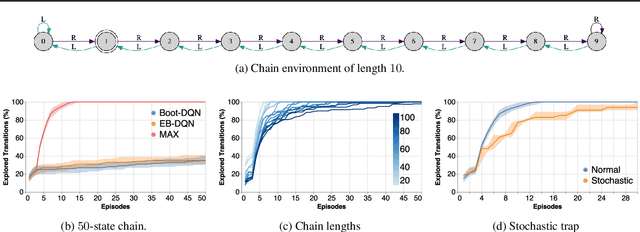
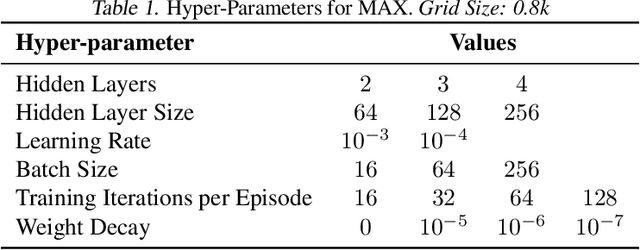
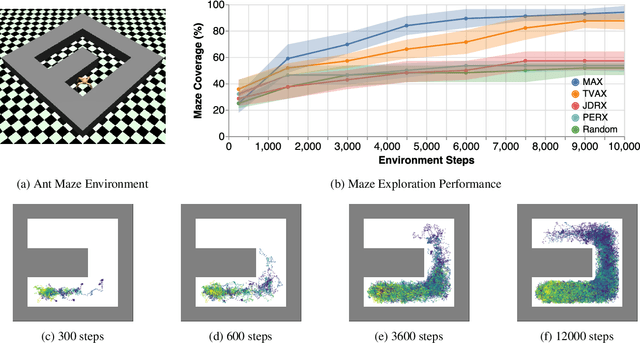

Efficient exploration is an unsolved problem in Reinforcement Learning. We introduce Model-Based Active eXploration (MAX), an algorithm that actively explores the environment. It minimizes data required to comprehensively model the environment by planning to observe novel events, instead of merely reacting to novelty encountered by chance. Non-stationarity induced by traditional exploration bonus techniques is avoided by constructing fresh exploration policies only at time of action. In semi-random toy environments where directed exploration is critical to make progress, our algorithm is at least an order of magnitude more efficient than strong baselines.
ViZDoom Competitions: Playing Doom from Pixels
Sep 10, 2018



This paper presents the first two editions of Visual Doom AI Competition, held in 2016 and 2017. The challenge was to create bots that compete in a multi-player deathmatch in a first-person shooter (FPS) game, Doom. The bots had to make their decisions based solely on visual information, i.e., a raw screen buffer. To play well, the bots needed to understand their surroundings, navigate, explore, and handle the opponents at the same time. These aspects, together with the competitive multi-agent aspect of the game, make the competition a unique platform for evaluating the state of the art reinforcement learning algorithms. The paper discusses the rules, solutions, results, and statistics that give insight into the agents' behaviors. Best-performing agents are described in more detail. The results of the competition lead to the conclusion that, although reinforcement learning can produce capable Doom bots, they still are not yet able to successfully compete against humans in this game. The paper also revisits the ViZDoom environment, which is a flexible, easy to use, and efficient 3D platform for research for vision-based reinforcement learning, based on a well-recognized first-person perspective game Doom.
Learning to Play Othello with Deep Neural Networks
Nov 17, 2017
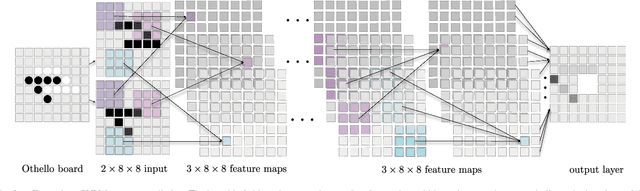
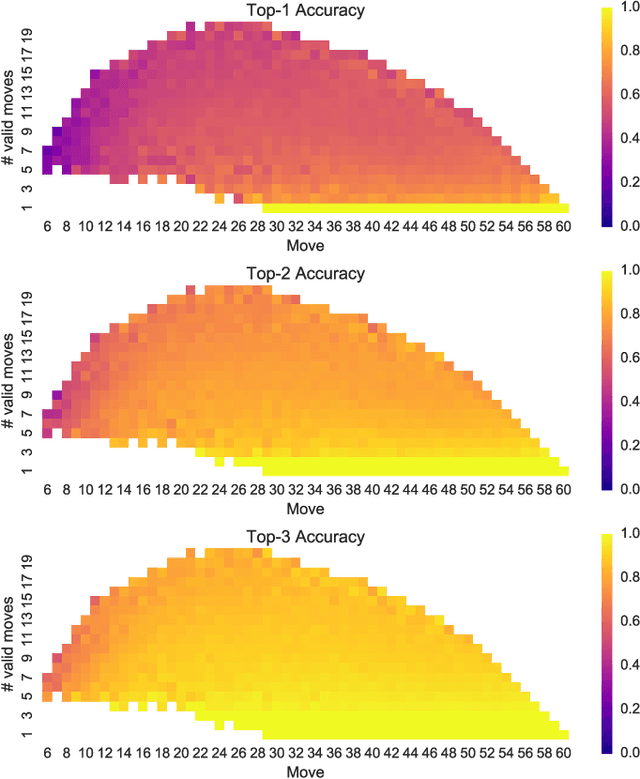
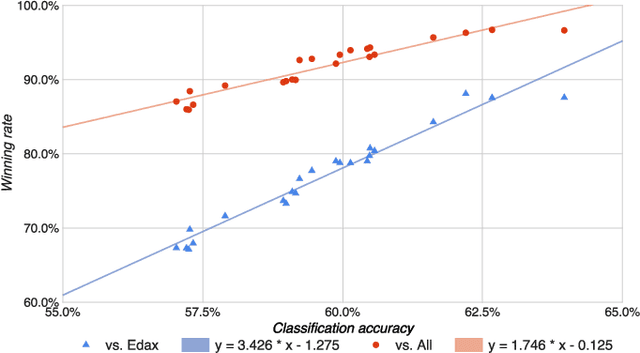
Achieving superhuman playing level by AlphaGo corroborated the capabilities of convolutional neural architectures (CNNs) for capturing complex spatial patterns. This result was to a great extent due to several analogies between Go board states and 2D images CNNs have been designed for, in particular translational invariance and a relatively large board. In this paper, we verify whether CNN-based move predictors prove effective for Othello, a game with significantly different characteristics, including a much smaller board size and complete lack of translational invariance. We compare several CNN architectures and board encodings, augment them with state-of-the-art extensions, train on an extensive database of experts' moves, and examine them with respect to move prediction accuracy and playing strength. The empirical evaluation confirms high capabilities of neural move predictors and suggests a strong correlation between prediction accuracy and playing strength. The best CNNs not only surpass all other 1-ply Othello players proposed to date but defeat (2-ply) Edax, the best open-source Othello player.
Mastering 2048 with Delayed Temporal Coherence Learning, Multi-Stage Weight Promotion, Redundant Encoding and Carousel Shaping
Dec 12, 2016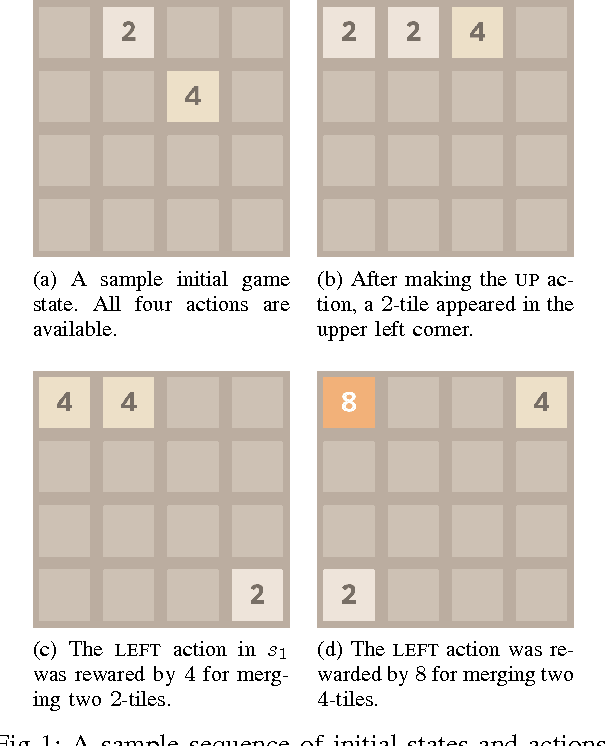
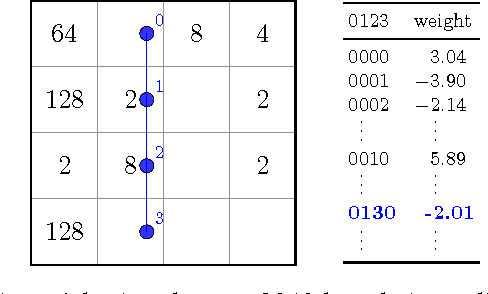
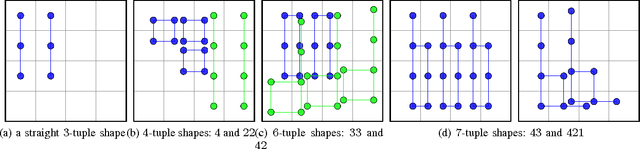
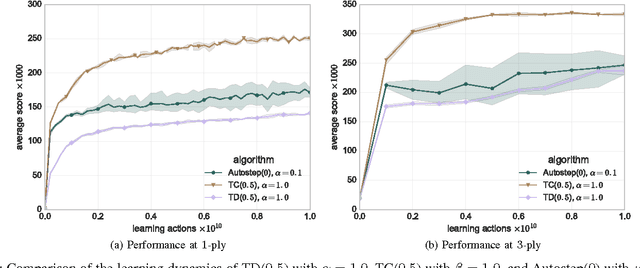
2048 is an engaging single-player, nondeterministic video puzzle game, which, thanks to the simple rules and hard-to-master gameplay, has gained massive popularity in recent years. As 2048 can be conveniently embedded into the discrete-state Markov decision processes framework, we treat it as a testbed for evaluating existing and new methods in reinforcement learning. With the aim to develop a strong 2048 playing program, we employ temporal difference learning with systematic n-tuple networks. We show that this basic method can be significantly improved with temporal coherence learning, multi-stage function approximator with weight promotion, carousel shaping, and redundant encoding. In addition, we demonstrate how to take advantage of the characteristics of the n-tuple network, to improve the algorithmic effectiveness of the learning process by i) delaying the (decayed) update and applying lock-free optimistic parallelism to effortlessly make advantage of multiple CPU cores. This way, we were able to develop the best known 2048 playing program to date, which confirms the effectiveness of the introduced methods for discrete-state Markov decision problems.
ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
Sep 20, 2016


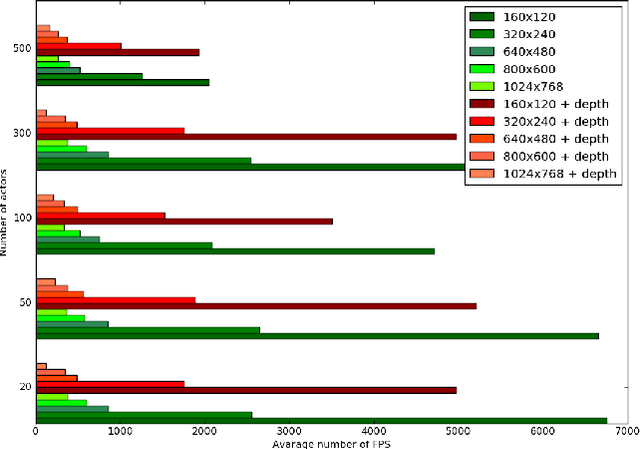
The recent advances in deep neural networks have led to effective vision-based reinforcement learning methods that have been employed to obtain human-level controllers in Atari 2600 games from pixel data. Atari 2600 games, however, do not resemble real-world tasks since they involve non-realistic 2D environments and the third-person perspective. Here, we propose a novel test-bed platform for reinforcement learning research from raw visual information which employs the first-person perspective in a semi-realistic 3D world. The software, called ViZDoom, is based on the classical first-person shooter video game, Doom. It allows developing bots that play the game using the screen buffer. ViZDoom is lightweight, fast, and highly customizable via a convenient mechanism of user scenarios. In the experimental part, we test the environment by trying to learn bots for two scenarios: a basic move-and-shoot task and a more complex maze-navigation problem. Using convolutional deep neural networks with Q-learning and experience replay, for both scenarios, we were able to train competent bots, which exhibit human-like behaviors. The results confirm the utility of ViZDoom as an AI research platform and imply that visual reinforcement learning in 3D realistic first-person perspective environments is feasible.
Systematic N-tuple Networks for Position Evaluation: Exceeding 90% in the Othello League
Jun 25, 2014

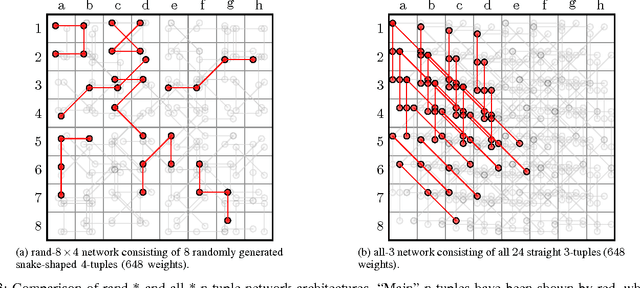
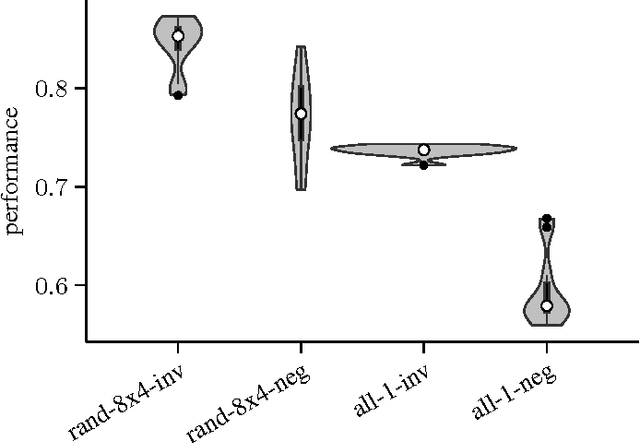
N-tuple networks have been successfully used as position evaluation functions for board games such as Othello or Connect Four. The effectiveness of such networks depends on their architecture, which is determined by the placement of constituent n-tuples, sequences of board locations, providing input to the network. The most popular method of placing n-tuples consists in randomly generating a small number of long, snake-shaped board location sequences. In comparison, we show that learning n-tuple networks is significantly more effective if they involve a large number of systematically placed, short, straight n-tuples. Moreover, we demonstrate that in order to obtain the best performance and the steepest learning curve for Othello it is enough to use n-tuples of size just 2, yielding a network consisting of only 288 weights. The best such network evolved in this study has been evaluated in the online Othello League, obtaining the performance of nearly 96% --- more than any other player to date.
* Added technical report number