 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Language Model with Large-Scale Persona Data Engineering
Dec 12, 2024

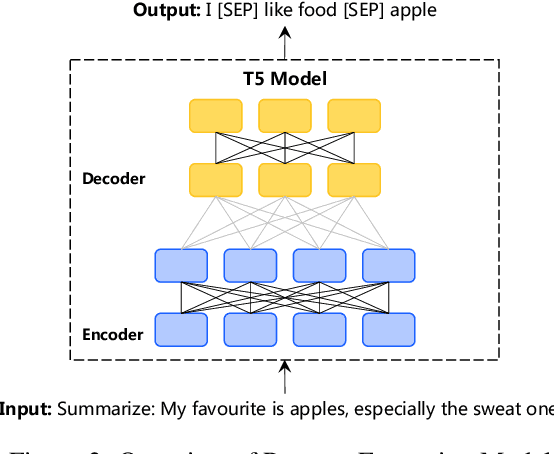
Maintaining persona consistency is paramount in the application of open-domain dialogue systems, as exemplified by models like ChatGPT. Despite significant advancements, the limited scale and diversity of current persona dialogue datasets remain challenges to achieving robust persona-consistent dialogue models. In this study, drawing inspiration from the success of large-scale pre-training, we introduce PPDS, an open-domain persona dialogue system that employs extensive generative pre-training on a persona dialogue dataset to enhance persona consistency. Specifically, we present a persona extraction model designed to autonomously and precisely generate vast persona dialogue datasets. Additionally, we unveil a pioneering persona augmentation technique to address the invalid persona bias inherent in the constructed dataset. Both quantitative and human evaluations consistently highlight the superior response quality and persona consistency of our proposed model, underscoring its effectiveness.
Acoustic Model Optimization over Multiple Data Sources: Merging and Valuation
Oct 21, 2024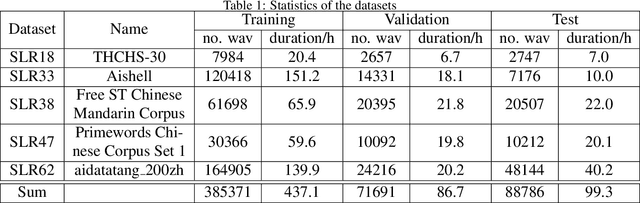
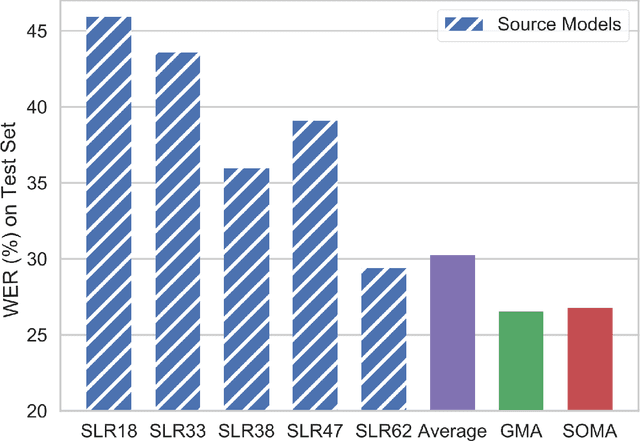
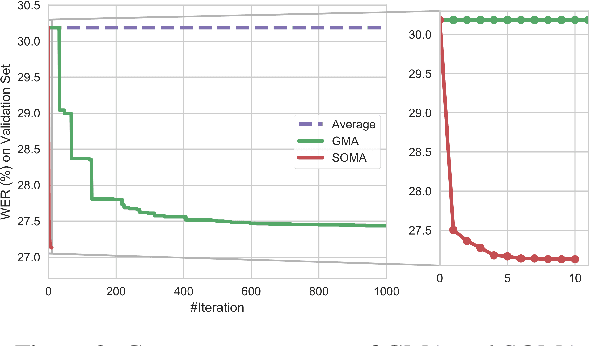
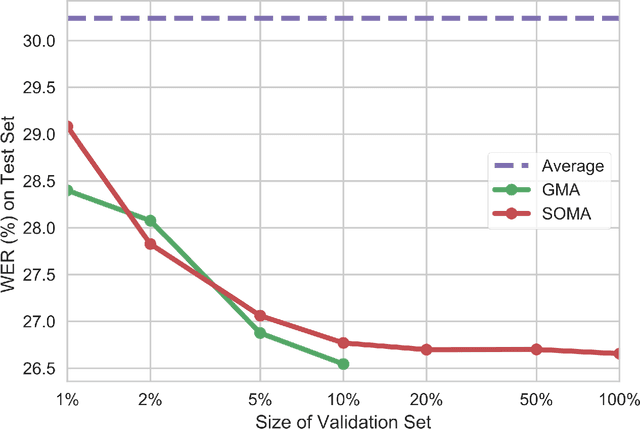
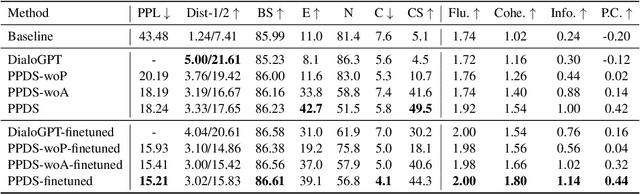
Due to the rising awareness of privacy protection and the voluminous scale of speech data, it is becoming infeasible for Automatic Speech Recognition (ASR) system developers to train the acoustic model with complete data as before. For example, the data may be owned by different curators, and it is not allowed to share with others. In this paper, we propose a novel paradigm to solve salient problems plaguing the ASR field. In the first stage, multiple acoustic models are trained based upon different subsets of the complete speech data, while in the second phase, two novel algorithms are utilized to generate a high-quality acoustic model based upon those trained on data subsets. We first propose the Genetic Merge Algorithm (GMA), which is a highly specialized algorithm for optimizing acoustic models but suffers from low efficiency. We further propose the SGD-Based Optimizational Merge Algorithm (SOMA), which effectively alleviates the efficiency bottleneck of GMA and maintains superior model accuracy. Extensive experiments on public data show that the proposed methods can significantly outperform the state-of-the-art. Furthermore, we introduce Shapley Value to estimate the contribution score of the trained models, which is useful for evaluating the effectiveness of the data and providing fair incentives to their curators.
DAL: Dual Adversarial Learning for Dialogue Generation
Jun 23, 2019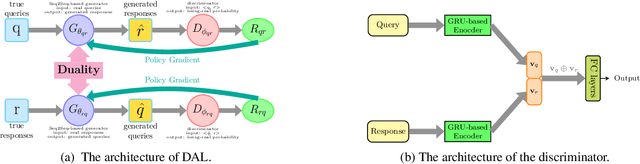
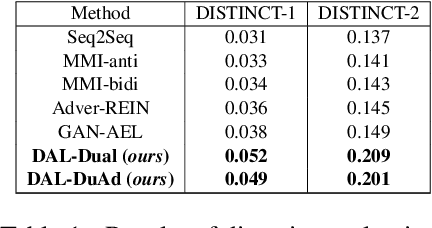
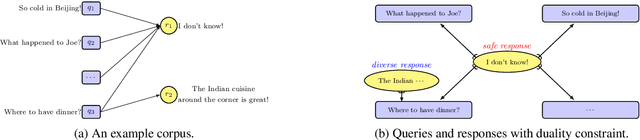
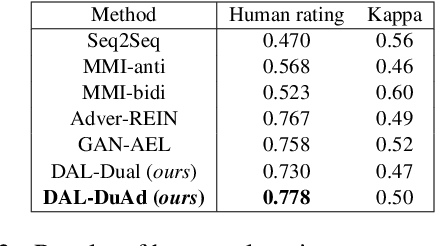
In open-domain dialogue systems, generative approaches have attracted much attention for response generation. However, existing methods are heavily plagued by generating safe responses and unnatural responses. To alleviate these two problems, we propose a novel framework named Dual Adversarial Learning (DAL) for high-quality response generation. DAL is the first work to innovatively utilizes the duality between query generation and response generation to avoid safe responses and increase the diversity of the generated responses. Additionally, DAL uses adversarial learning to mimic human judges and guides the system to generate natural responses. Experimental results demonstrate that DAL effectively improves both diversity and overall quality of the generated responses. DAL outperforms the state-of-the-art methods regarding automatic metrics and human evaluations.
Proactive Human-Machine Conversation with Explicit Conversation Goals
Jun 13, 2019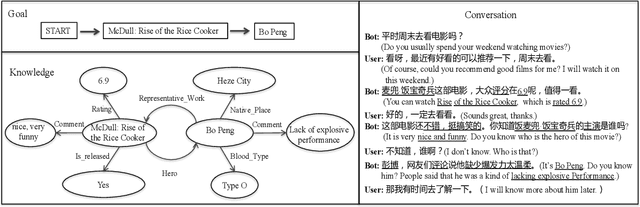
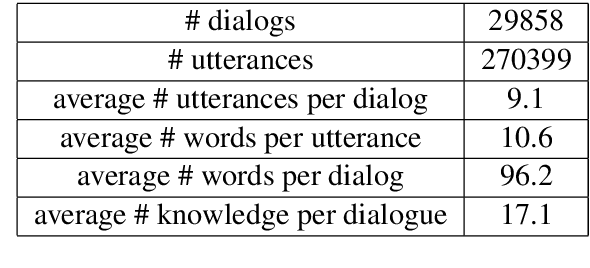
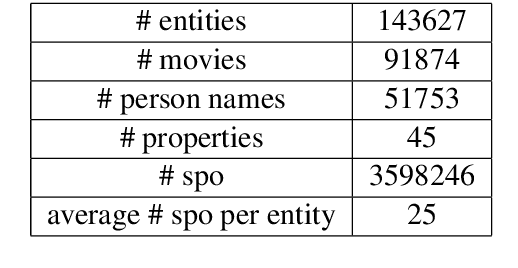
Though great progress has been made for human-machine conversation, current dialogue system is still in its infancy: it usually converses passively and utters words more as a matter of response, rather than on its own initiatives. In this paper, we take a radical step towards building a human-like conversational agent: endowing it with the ability of proactively leading the conversation (introducing a new topic or maintaining the current topic). To facilitate the development of such conversation systems, we create a new dataset named DuConv where one acts as a conversation leader and the other acts as the follower. The leader is provided with a knowledge graph and asked to sequentially change the discussion topics, following the given conversation goal, and meanwhile keep the dialogue as natural and engaging as possible. DuConv enables a very challenging task as the model needs to both understand dialogue and plan over the given knowledge graph. We establish baseline results on this dataset (about 270K utterances and 30k dialogues) using several state-of-the-art models. Experimental results show that dialogue models that plan over the knowledge graph can make full use of related knowledge to generate more diverse multi-turn conversations. The baseline systems along with the dataset are publicly available
Know More about Each Other: Evolving Dialogue Strategy via Compound Assessment
Jun 03, 2019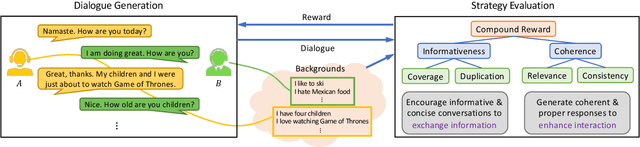
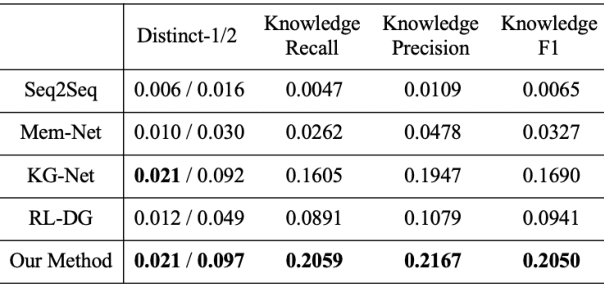
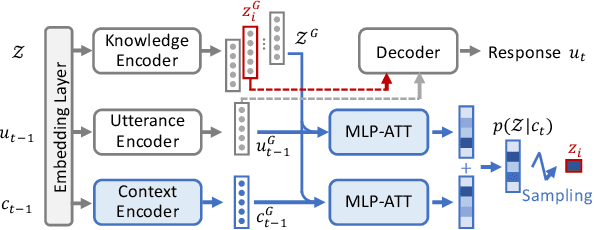
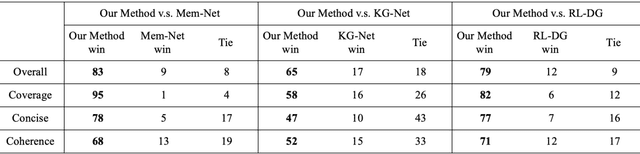
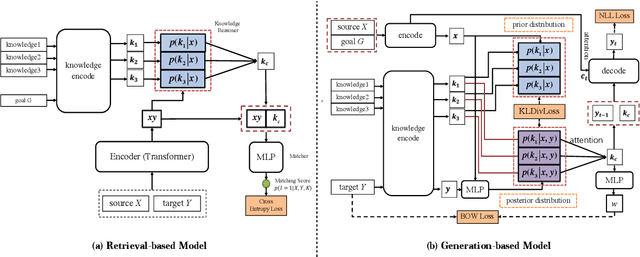
In this paper, a novel Generation-Evaluation framework is developed for multi-turn conversations with the objective of letting both participants know more about each other. For the sake of rational knowledge utilization and coherent conversation flow, a dialogue strategy which controls knowledge selection is instantiated and continuously adapted via reinforcement learning. Under the deployed strategy, knowledge grounded conversations are conducted with two dialogue agents. The generated dialogues are comprehensively evaluated on aspects like informativeness and coherence, which are aligned with our objective and human instinct. These assessments are integrated as a compound reward to guide the evolution of dialogue strategy via policy gradient. Comprehensive experiments have been carried out on the publicly available dataset, demonstrating that the proposed method outperforms the other state-of-the-art approaches significantly.
Learning to Select Knowledge for Response Generation in Dialog Systems
Feb 13, 2019
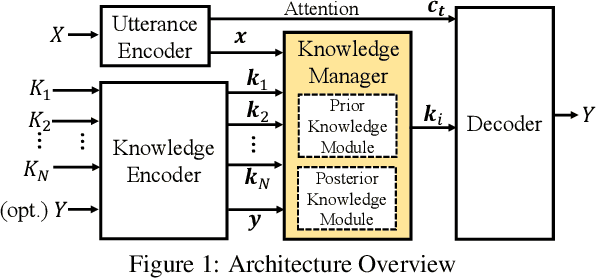
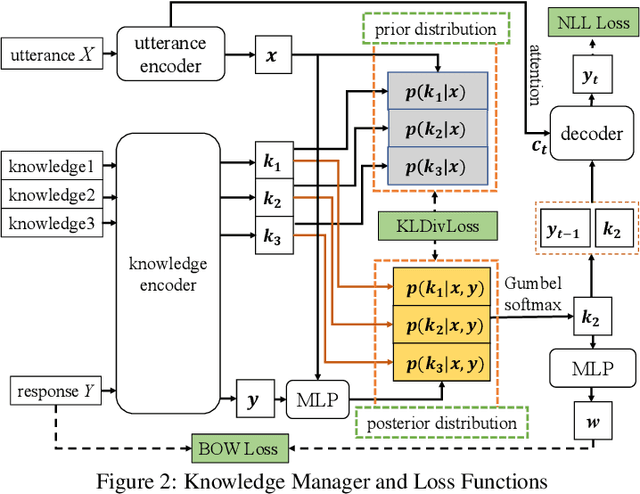
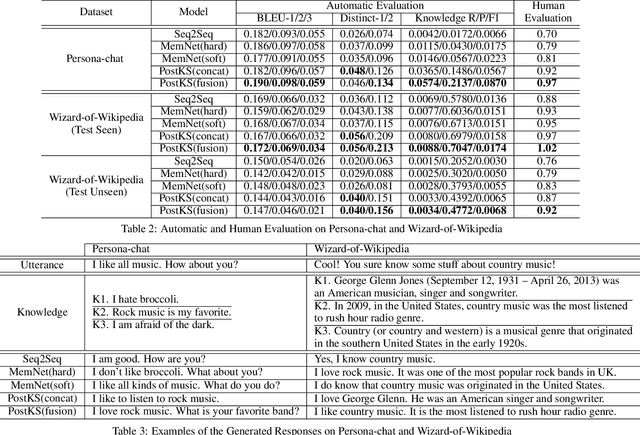
Generating informative responses in end-to-end neural dialogue systems attracts a lot of attention in recent years. Various previous work leverages external knowledge and the dialogue contexts to generate such responses. Nevertheless, few has demonstrated their capability on incorporating the appropriate knowledge in response generation. Motivated by this, we propose a novel open-domain conversation generation model in this paper, which employs the posterior knowledge distribution to guide knowledge selection, therefore generating more appropriate and informative responses in conversations. To the best of our knowledge, we are the first one who utilize the posterior knowledge distribution to facilitate conversation generation. Our experiments on both automatic and human evaluation clearly verify the superior performance of our model over the state-of-the-art baselines.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
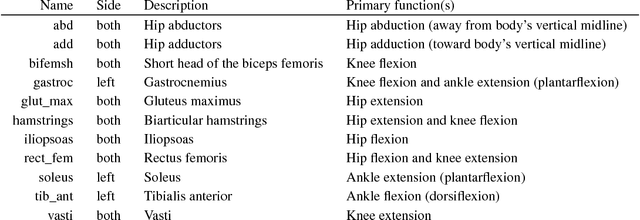
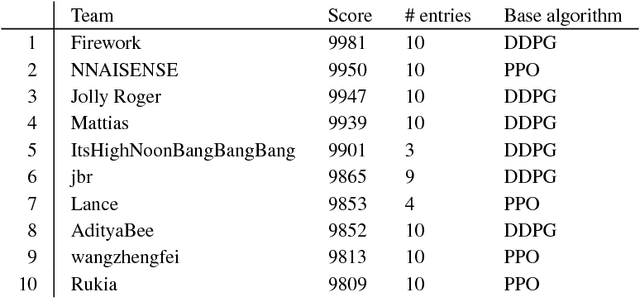

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Familia: A Configurable Topic Modeling Framework for Industrial Text Engineering
Aug 14, 2018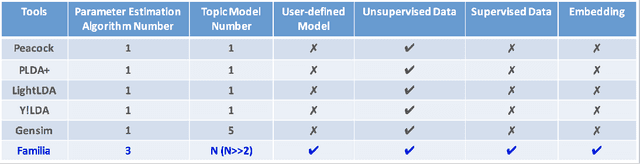
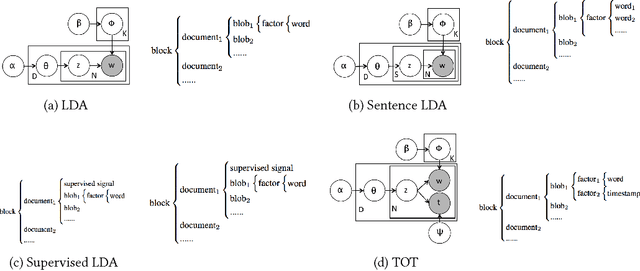
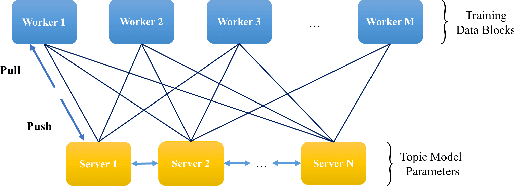
In the last decade, a variety of topic models have been proposed for text engineering. However, except Probabilistic Latent Semantic Analysis (PLSA) and Latent Dirichlet Allocation (LDA), most of existing topic models are seldom applied or considered in industrial scenarios. This phenomenon is caused by the fact that there are very few convenient tools to support these topic models so far. Intimidated by the demanding expertise and labor of designing and implementing parameter inference algorithms, software engineers are prone to simply resort to PLSA/LDA, without considering whether it is proper for their problem at hand or not. In this paper, we propose a configurable topic modeling framework named Familia, in order to bridge the huge gap between academic research fruits and current industrial practice. Familia supports an important line of topic models that are widely applicable in text engineering scenarios. In order to relieve burdens of software engineers without knowledge of Bayesian networks, Familia is able to conduct automatic parameter inference for a variety of topic models. Simply through changing the data organization of Familia, software engineers are able to easily explore a broad spectrum of existing topic models or even design their own topic models, and find the one that best suits the problem at hand. With its superior extendability, Familia has a novel sampling mechanism that strikes balance between effectiveness and efficiency of parameter inference. Furthermore, Familia is essentially a big topic modeling framework that supports parallel parameter inference and distributed parameter storage. The utilities and necessity of Familia are demonstrated in real-life industrial applications. Familia would significantly enlarge software engineers' arsenal of topic models and pave the way for utilizing highly customized topic models in real-life problems.
Familia: An Open-Source Toolkit for Industrial Topic Modeling
Jul 31, 2017



Familia is an open-source toolkit for pragmatic topic modeling in industry. Familia abstracts the utilities of topic modeling in industry as two paradigms: semantic representation and semantic matching. Efficient implementations of the two paradigms are made publicly available for the first time. Furthermore, we provide off-the-shelf topic models trained on large-scale industrial corpora, including Latent Dirichlet Allocation (LDA), SentenceLDA and Topical Word Embedding (TWE). We further describe typical applications which are successfully powered by topic modeling, in order to ease the confusions and difficulties of software engineers during topic model selection and utilization.