 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multiple Diverse Responses with Multi-Mapping and Posterior Mapping Selection
Jun 05, 2019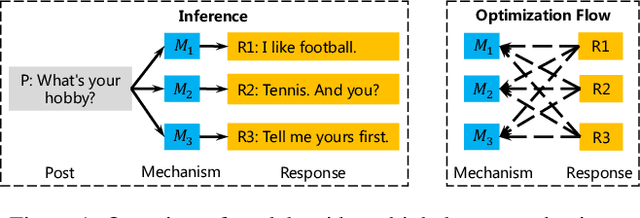
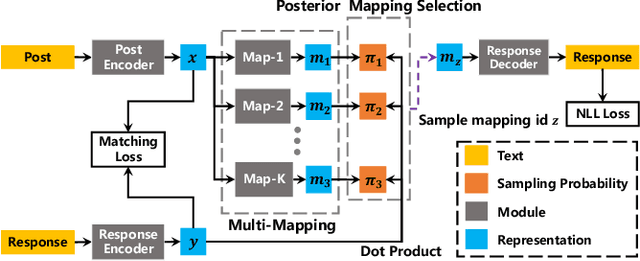
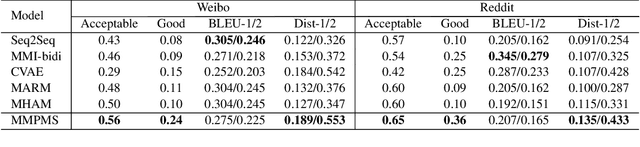
In human conversation an input post is open to multiple potential responses, which is typically regarded as a one-to-many problem. Promising approaches mainly incorporate multiple latent mechanisms to build the one-to-many relationship. However, without accurate selection of the latent mechanism corresponding to the target response during training, these methods suffer from a rough optimization of latent mechanisms. In this paper, we propose a multi-mapping mechanism to better capture the one-to-many relationship, where multiple mapping modules are employed as latent mechanisms to model the semantic mappings from an input post to its diverse responses. For accurate optimization of latent mechanisms, a posterior mapping selection module is designed to select the corresponding mapping module according to the target response for further optimization. We also introduce an auxiliary matching loss to facilitate the optimization of posterior mapping selection. Empirical results demonstrate the superiority of our model in generating multiple diverse and informative responses over the state-of-the-art methods.
Learning to Select Knowledge for Response Generation in Dialog Systems
Feb 13, 2019
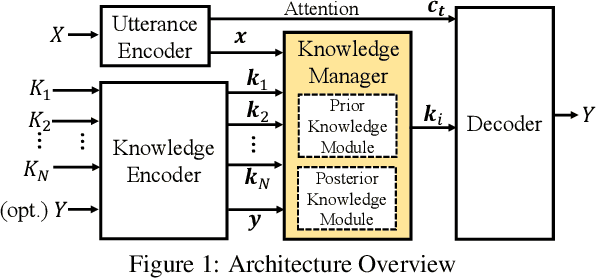
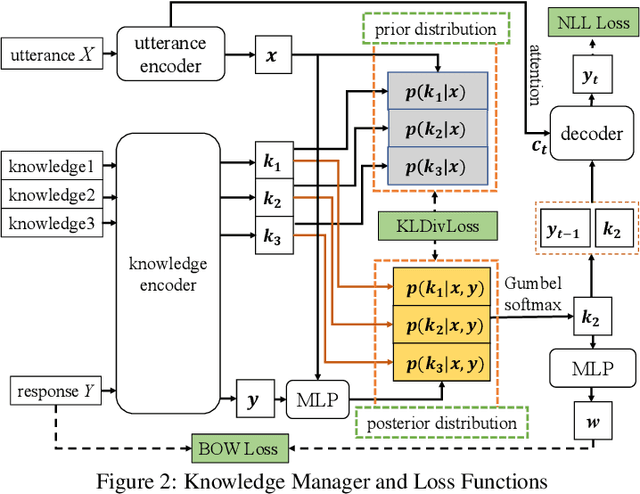
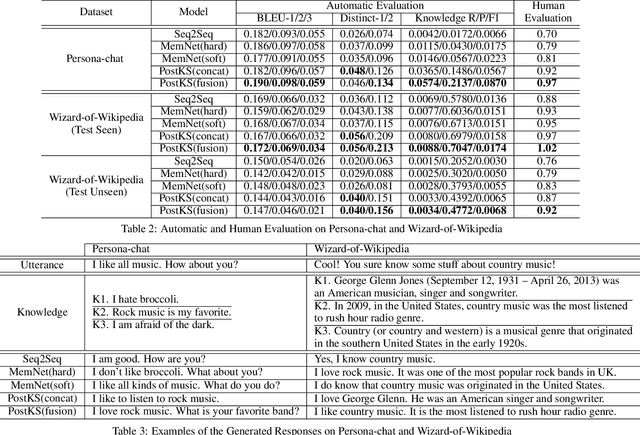
Generating informative responses in end-to-end neural dialogue systems attracts a lot of attention in recent years. Various previous work leverages external knowledge and the dialogue contexts to generate such responses. Nevertheless, few has demonstrated their capability on incorporating the appropriate knowledge in response generation. Motivated by this, we propose a novel open-domain conversation generation model in this paper, which employs the posterior knowledge distribution to guide knowledge selection, therefore generating more appropriate and informative responses in conversations. To the best of our knowledge, we are the first one who utilize the posterior knowledge distribution to facilitate conversation generation. Our experiments on both automatic and human evaluation clearly verify the superior performance of our model over the state-of-the-art baselines.
Familia: A Configurable Topic Modeling Framework for Industrial Text Engineering
Aug 14, 2018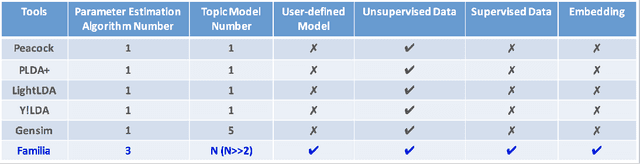
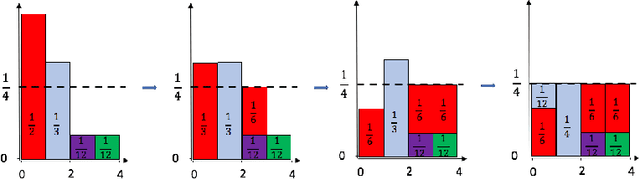
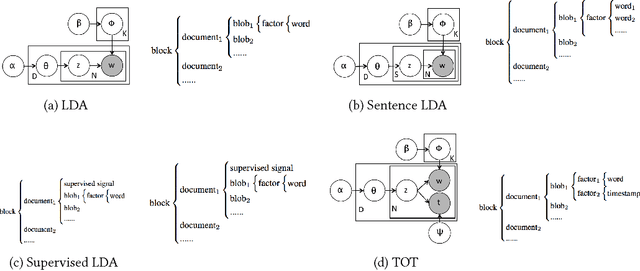
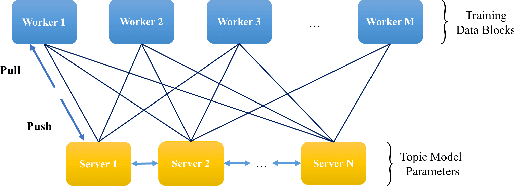
In the last decade, a variety of topic models have been proposed for text engineering. However, except Probabilistic Latent Semantic Analysis (PLSA) and Latent Dirichlet Allocation (LDA), most of existing topic models are seldom applied or considered in industrial scenarios. This phenomenon is caused by the fact that there are very few convenient tools to support these topic models so far. Intimidated by the demanding expertise and labor of designing and implementing parameter inference algorithms, software engineers are prone to simply resort to PLSA/LDA, without considering whether it is proper for their problem at hand or not. In this paper, we propose a configurable topic modeling framework named Familia, in order to bridge the huge gap between academic research fruits and current industrial practice. Familia supports an important line of topic models that are widely applicable in text engineering scenarios. In order to relieve burdens of software engineers without knowledge of Bayesian networks, Familia is able to conduct automatic parameter inference for a variety of topic models. Simply through changing the data organization of Familia, software engineers are able to easily explore a broad spectrum of existing topic models or even design their own topic models, and find the one that best suits the problem at hand. With its superior extendability, Familia has a novel sampling mechanism that strikes balance between effectiveness and efficiency of parameter inference. Furthermore, Familia is essentially a big topic modeling framework that supports parallel parameter inference and distributed parameter storage. The utilities and necessity of Familia are demonstrated in real-life industrial applications. Familia would significantly enlarge software engineers' arsenal of topic models and pave the way for utilizing highly customized topic models in real-life problems.