 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
ASR-EC Benchmark: Evaluating Large Language Models on Chinese ASR Error Correction
Dec 04, 2024Automatic speech Recognition (ASR) is a fundamental and important task in the field of speech and natural language processing. It is an inherent building block in many applications such as voice assistant, speech translation, etc. Despite the advancement of ASR technologies in recent years, it is still inevitable for modern ASR systems to have a substantial number of erroneous recognition due to environmental noise, ambiguity, etc. Therefore, the error correction in ASR is crucial. Motivated by this, this paper studies ASR error correction in the Chinese language, which is one of the most popular languages and enjoys a large number of users in the world. We first create a benchmark dataset named \emph{ASR-EC} that contains a wide spectrum of ASR errors generated by industry-grade ASR systems. To the best of our knowledge, it is the first Chinese ASR error correction benchmark. Then, inspired by the recent advances in \emph{large language models (LLMs)}, we investigate how to harness the power of LLMs to correct ASR errors. We apply LLMs to ASR error correction in three paradigms. The first paradigm is prompting, which is further categorized as zero-shot, few-shot, and multi-step. The second paradigm is finetuning, which finetunes LLMs with ASR error correction data. The third paradigm is multi-modal augmentation, which collectively utilizes the audio and ASR transcripts for error correction. Extensive experiments reveal that prompting is not effective for ASR error correction. Finetuning is effective only for a portion of LLMs. Multi-modal augmentation is the most effective method for error correction and achieves state-of-the-art performance.
Acoustic Model Optimization over Multiple Data Sources: Merging and Valuation
Oct 21, 2024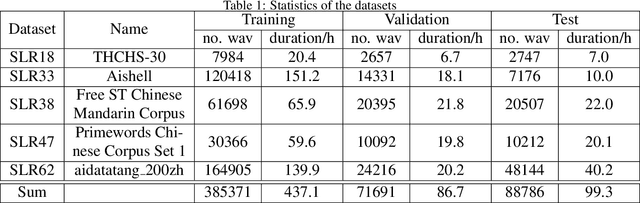
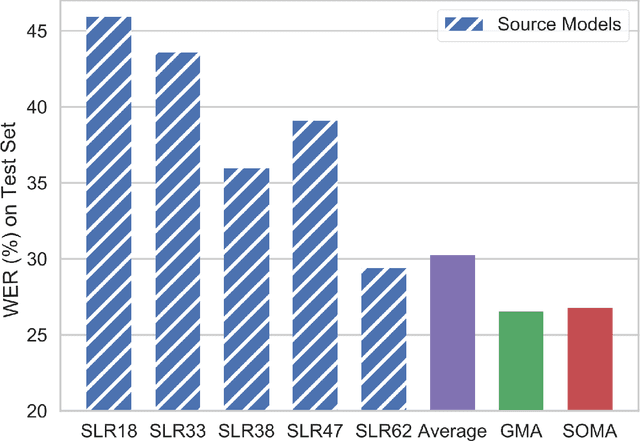
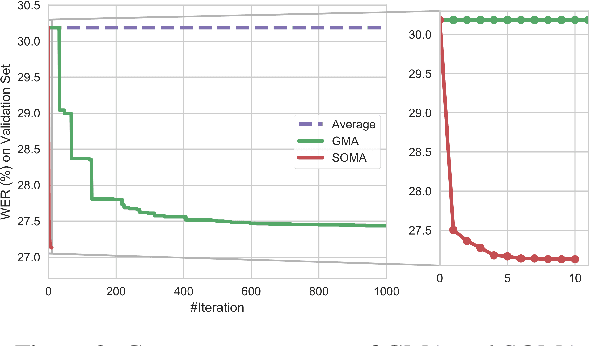
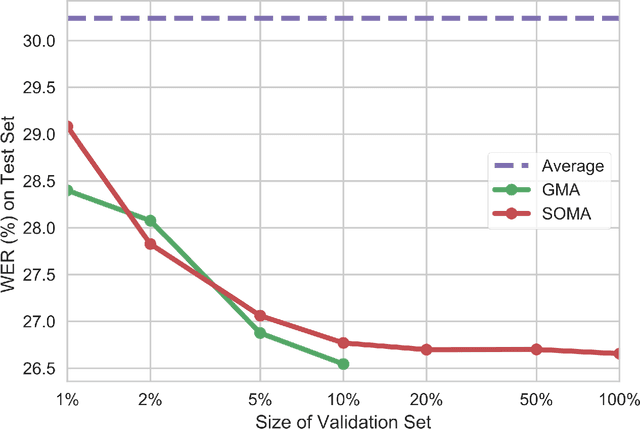
Due to the rising awareness of privacy protection and the voluminous scale of speech data, it is becoming infeasible for Automatic Speech Recognition (ASR) system developers to train the acoustic model with complete data as before. For example, the data may be owned by different curators, and it is not allowed to share with others. In this paper, we propose a novel paradigm to solve salient problems plaguing the ASR field. In the first stage, multiple acoustic models are trained based upon different subsets of the complete speech data, while in the second phase, two novel algorithms are utilized to generate a high-quality acoustic model based upon those trained on data subsets. We first propose the Genetic Merge Algorithm (GMA), which is a highly specialized algorithm for optimizing acoustic models but suffers from low efficiency. We further propose the SGD-Based Optimizational Merge Algorithm (SOMA), which effectively alleviates the efficiency bottleneck of GMA and maintains superior model accuracy. Extensive experiments on public data show that the proposed methods can significantly outperform the state-of-the-art. Furthermore, we introduce Shapley Value to estimate the contribution score of the trained models, which is useful for evaluating the effectiveness of the data and providing fair incentives to their curators.
Exploiting Student Parallelism for Low-latency GPU Inference of BERT-like Models in Online Services
Aug 22, 2024


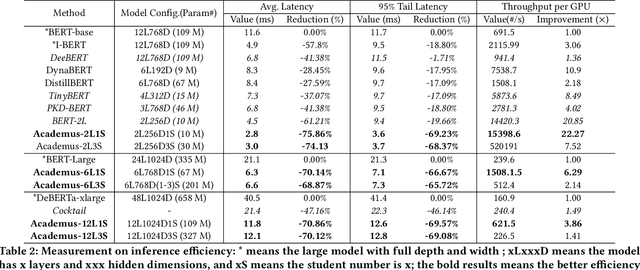
Due to high accuracy, BERT-like models have been widely adopted by discriminative text mining and web searching. However, large BERT-like models suffer from inefficient online inference, as they face the following two problems on GPUs. First, they rely on the large model depth to achieve high accuracy, which linearly increases the sequential computation on GPUs. Second, stochastic and dynamic online workloads cause extra costs. In this paper, we present Academus for low-latency online inference of BERT-like models. At the core of Academus is the novel student parallelism, which adopts boosting ensemble and stacking distillation to distill the original deep model into an equivalent group of parallel and shallow student models. This enables Academus to achieve the lower model depth (e.g., two layers) than baselines and consequently the lowest inference latency without affecting the accuracy.For occasional workload bursts, it can temporarily decrease the number of students with minimal accuracy loss to improve throughput. Additionally, it employs specialized system designs for student parallelism to better handle stochastic online workloads. We conduct comprehensive experiments to verify the effectiveness. The results show that Academus outperforms the baselines by 4.1X~1.6X in latency without compromising accuracy, and achieves up to 22.27X higher throughput for workload bursts.
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Oct 27, 2023



The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
Automatic Data Visualization Generation from Chinese Natural Language Questions
Sep 14, 2023



Data visualization has emerged as an effective tool for getting insights from massive datasets. Due to the hardness of manipulating the programming languages of data visualization, automatic data visualization generation from natural languages (Text-to-Vis) is becoming increasingly popular. Despite the plethora of research effort on the English Text-to-Vis, studies have yet to be conducted on data visualization generation from questions in Chinese. Motivated by this, we propose a Chinese Text-to-Vis dataset in the paper and demonstrate our first attempt to tackle this problem. Our model integrates multilingual BERT as the encoder, boosts the cross-lingual ability, and infuses the $n$-gram information into our word representation learning. Our experimental results show that our dataset is challenging and deserves further research.