 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-o3: Deep Nested Omnimodal Deduction for Deliberative Audio-Visual Reasoning
Apr 27, 2026Omnimodal understanding entails a massive, highly redundant search space of cross-modal interactions, demanding focused and deliberative reasoning. Current reasoning paradigms rely on either sequential step-by-step generation or parallel sample-by-sample rollouts, leading to isolated reasoning trajectories. This inability to share promising intermediate paths severely limits exploration efficiency and causes compounding errors in complex audio-visual tasks. To break this bottleneck, we introduce Omni-o3, a novel framework driven by a deep nested deduction policy. By formulating reasoning as a dynamic recursive search, Omni-o3 inherently shares reasoning prefixes across branches, enabling the iterative execution of four atomic cognitive actions: expansion, selection, simulation, and backpropagation. To empower this framework, we propose a robust two-stage training paradigm: (1) cold-start supervised fine-tuning on 101K high-quality, long-chain trajectories distilled from 3.5M diverse omnimodal samples, enabling necessary recursive search patterns; and (2) nested group rollout-driven exploratory reinforcement learning on 18K complex multi-turn samples, explicitly guided by a novel multi-step reward model to stimulate deep nested reasoning. Extensive experiments demonstrate that Omni-o3 achieves competitive performance across 11 benchmarks, unlocking advanced capabilities in comprehensive audio-visual, visual-centric, and audio-centric reasoning tasks.
ASR-EC Benchmark: Evaluating Large Language Models on Chinese ASR Error Correction
Dec 04, 2024Automatic speech Recognition (ASR) is a fundamental and important task in the field of speech and natural language processing. It is an inherent building block in many applications such as voice assistant, speech translation, etc. Despite the advancement of ASR technologies in recent years, it is still inevitable for modern ASR systems to have a substantial number of erroneous recognition due to environmental noise, ambiguity, etc. Therefore, the error correction in ASR is crucial. Motivated by this, this paper studies ASR error correction in the Chinese language, which is one of the most popular languages and enjoys a large number of users in the world. We first create a benchmark dataset named \emph{ASR-EC} that contains a wide spectrum of ASR errors generated by industry-grade ASR systems. To the best of our knowledge, it is the first Chinese ASR error correction benchmark. Then, inspired by the recent advances in \emph{large language models (LLMs)}, we investigate how to harness the power of LLMs to correct ASR errors. We apply LLMs to ASR error correction in three paradigms. The first paradigm is prompting, which is further categorized as zero-shot, few-shot, and multi-step. The second paradigm is finetuning, which finetunes LLMs with ASR error correction data. The third paradigm is multi-modal augmentation, which collectively utilizes the audio and ASR transcripts for error correction. Extensive experiments reveal that prompting is not effective for ASR error correction. Finetuning is effective only for a portion of LLMs. Multi-modal augmentation is the most effective method for error correction and achieves state-of-the-art performance.
Acoustic Model Optimization over Multiple Data Sources: Merging and Valuation
Oct 21, 2024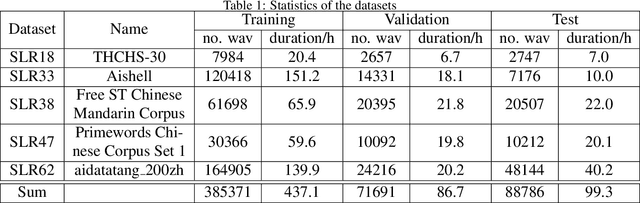
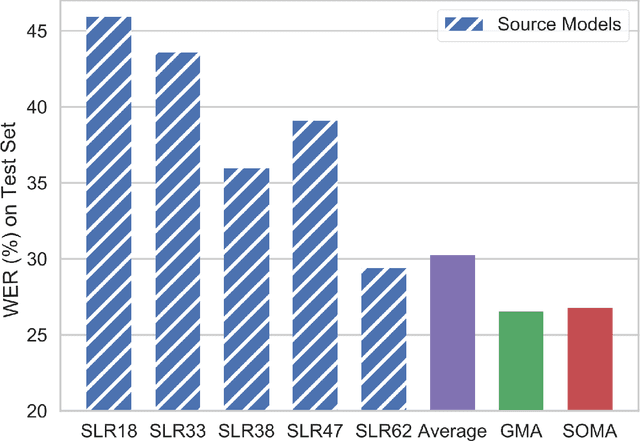
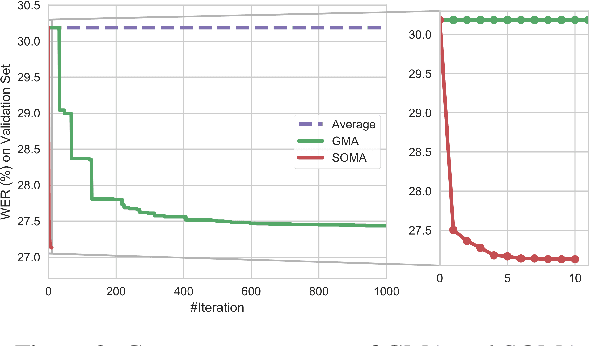
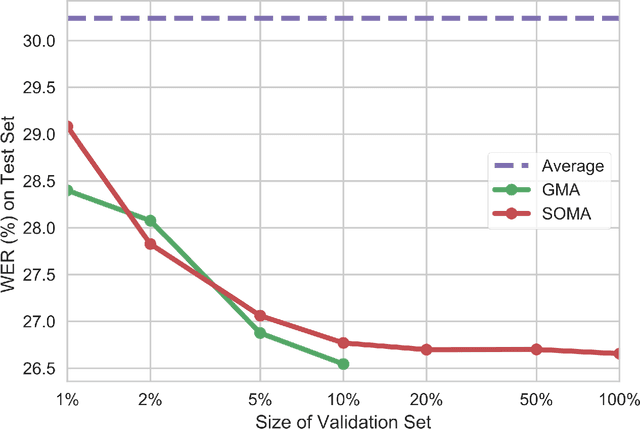
Due to the rising awareness of privacy protection and the voluminous scale of speech data, it is becoming infeasible for Automatic Speech Recognition (ASR) system developers to train the acoustic model with complete data as before. For example, the data may be owned by different curators, and it is not allowed to share with others. In this paper, we propose a novel paradigm to solve salient problems plaguing the ASR field. In the first stage, multiple acoustic models are trained based upon different subsets of the complete speech data, while in the second phase, two novel algorithms are utilized to generate a high-quality acoustic model based upon those trained on data subsets. We first propose the Genetic Merge Algorithm (GMA), which is a highly specialized algorithm for optimizing acoustic models but suffers from low efficiency. We further propose the SGD-Based Optimizational Merge Algorithm (SOMA), which effectively alleviates the efficiency bottleneck of GMA and maintains superior model accuracy. Extensive experiments on public data show that the proposed methods can significantly outperform the state-of-the-art. Furthermore, we introduce Shapley Value to estimate the contribution score of the trained models, which is useful for evaluating the effectiveness of the data and providing fair incentives to their curators.