 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Student Parallelism for Low-latency GPU Inference of BERT-like Models in Online Services
Paper and Code
Aug 22, 2024


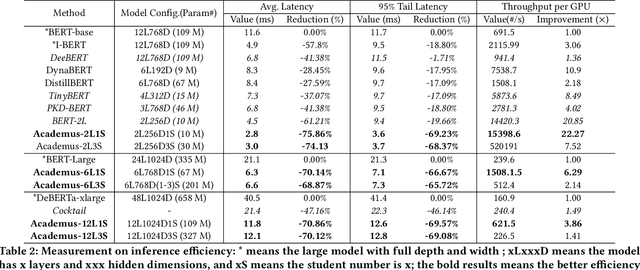
Due to high accuracy, BERT-like models have been widely adopted by discriminative text mining and web searching. However, large BERT-like models suffer from inefficient online inference, as they face the following two problems on GPUs. First, they rely on the large model depth to achieve high accuracy, which linearly increases the sequential computation on GPUs. Second, stochastic and dynamic online workloads cause extra costs. In this paper, we present Academus for low-latency online inference of BERT-like models. At the core of Academus is the novel student parallelism, which adopts boosting ensemble and stacking distillation to distill the original deep model into an equivalent group of parallel and shallow student models. This enables Academus to achieve the lower model depth (e.g., two layers) than baselines and consequently the lowest inference latency without affecting the accuracy.For occasional workload bursts, it can temporarily decrease the number of students with minimal accuracy loss to improve throughput. Additionally, it employs specialized system designs for student parallelism to better handle stochastic online workloads. We conduct comprehensive experiments to verify the effectiveness. The results show that Academus outperforms the baselines by 4.1X~1.6X in latency without compromising accuracy, and achieves up to 22.27X higher throughput for workload bursts.