 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamVQ: Beam Search with Vector Quantization to Mitigate Data Scarcity in Physical Spatiotemporal Forecasting
Feb 26, 2025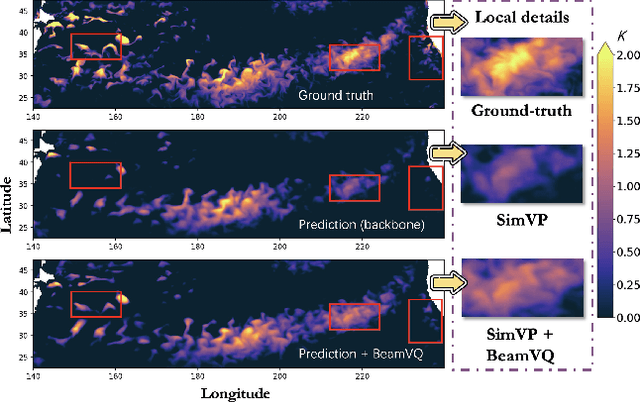
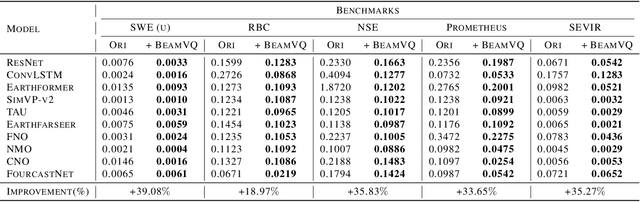
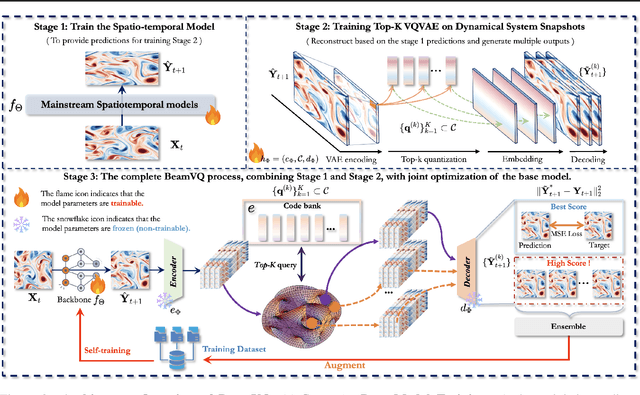
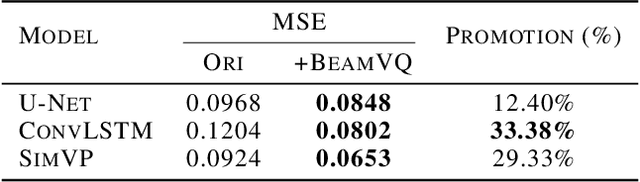
In practice, physical spatiotemporal forecasting can suffer from data scarcity, because collecting large-scale data is non-trivial, especially for extreme events. Hence, we propose \method{}, a novel probabilistic framework to realize iterative self-training with new self-ensemble strategies, achieving better physical consistency and generalization on extreme events. Following any base forecasting model, we can encode its deterministic outputs into a latent space and retrieve multiple codebook entries to generate probabilistic outputs. Then BeamVQ extends the beam search from discrete spaces to the continuous state spaces in this field. We can further employ domain-specific metrics (e.g., Critical Success Index for extreme events) to filter out the top-k candidates and develop the new self-ensemble strategy by combining the high-quality candidates. The self-ensemble can not only improve the inference quality and robustness but also iteratively augment the training datasets during continuous self-training. Consequently, BeamVQ realizes the exploration of rare but critical phenomena beyond the original dataset. Comprehensive experiments on different benchmarks and backbones show that BeamVQ consistently reduces forecasting MSE (up to 39%), enhancing extreme events detection and proving its effectiveness in handling data scarcity.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Exploiting Student Parallelism for Low-latency GPU Inference of BERT-like Models in Online Services
Aug 22, 2024


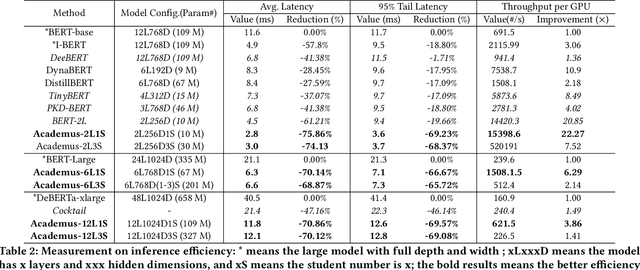
Due to high accuracy, BERT-like models have been widely adopted by discriminative text mining and web searching. However, large BERT-like models suffer from inefficient online inference, as they face the following two problems on GPUs. First, they rely on the large model depth to achieve high accuracy, which linearly increases the sequential computation on GPUs. Second, stochastic and dynamic online workloads cause extra costs. In this paper, we present Academus for low-latency online inference of BERT-like models. At the core of Academus is the novel student parallelism, which adopts boosting ensemble and stacking distillation to distill the original deep model into an equivalent group of parallel and shallow student models. This enables Academus to achieve the lower model depth (e.g., two layers) than baselines and consequently the lowest inference latency without affecting the accuracy.For occasional workload bursts, it can temporarily decrease the number of students with minimal accuracy loss to improve throughput. Additionally, it employs specialized system designs for student parallelism to better handle stochastic online workloads. We conduct comprehensive experiments to verify the effectiveness. The results show that Academus outperforms the baselines by 4.1X~1.6X in latency without compromising accuracy, and achieves up to 22.27X higher throughput for workload bursts.
BeamVQ: Aligning Space-Time Forecasting Model via Self-training on Physics-aware Metrics
May 27, 2024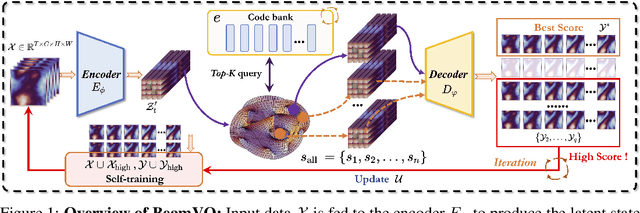
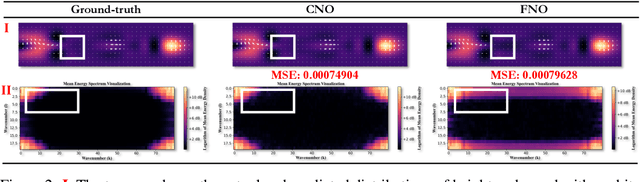
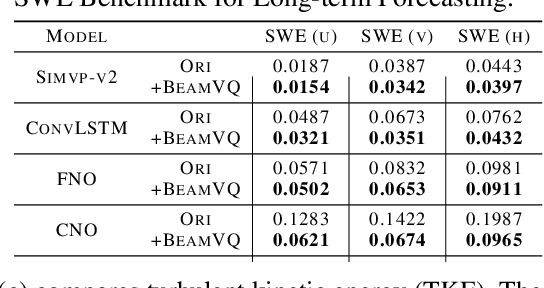
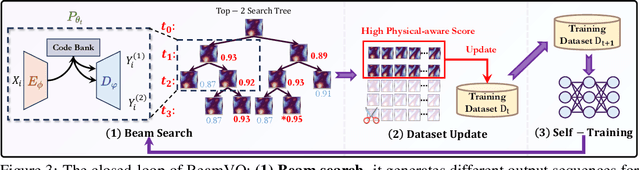
Data-driven deep learning has emerged as the new paradigm to model complex physical space-time systems. These data-driven methods learn patterns by optimizing statistical metrics and tend to overlook the adherence to physical laws, unlike traditional model-driven numerical methods. Thus, they often generate predictions that are not physically realistic. On the other hand, by sampling a large amount of high quality predictions from a data-driven model, some predictions will be more physically plausible than the others and closer to what will happen in the future. Based on this observation, we propose \emph{Beam search by Vector Quantization} (BeamVQ) to enhance the physical alignment of data-driven space-time forecasting models. The key of BeamVQ is to train model on self-generated samples filtered with physics-aware metrics. To be flexibly support different backbone architectures, BeamVQ leverages a code bank to transform any encoder-decoder model to the continuous state space into discrete codes. Afterwards, it iteratively employs beam search to sample high-quality sequences, retains those with the highest physics-aware scores, and trains model on the new dataset. Comprehensive experiments show that BeamVQ not only gave an average statistical skill score boost for more than 32% for ten backbones on five datasets, but also significantly enhances physics-aware metrics.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
May 23, 2024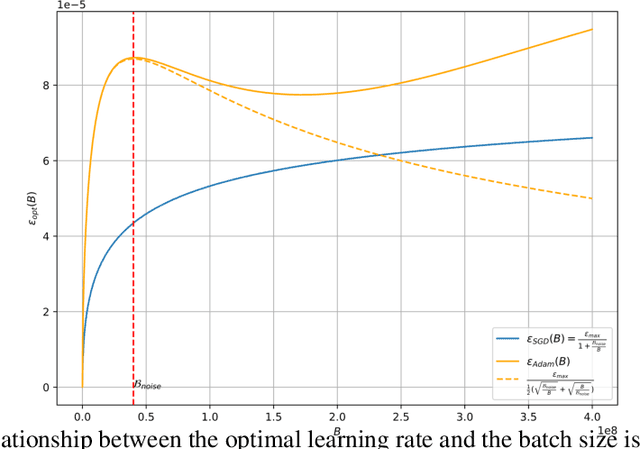
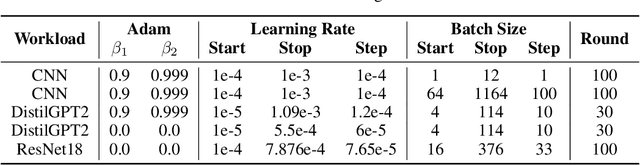
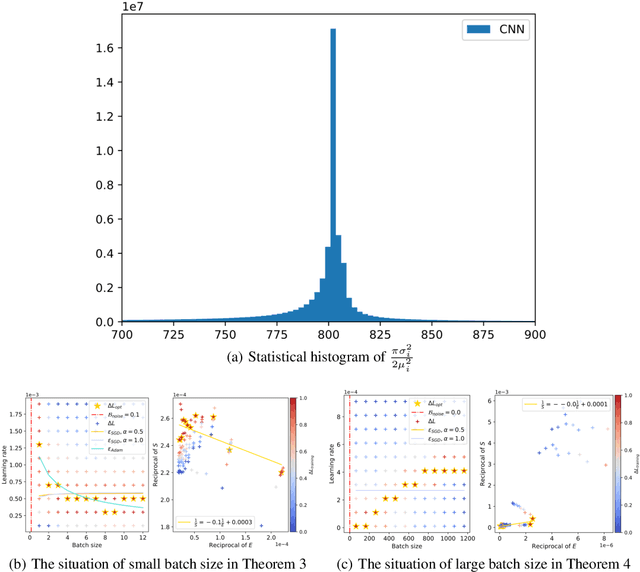
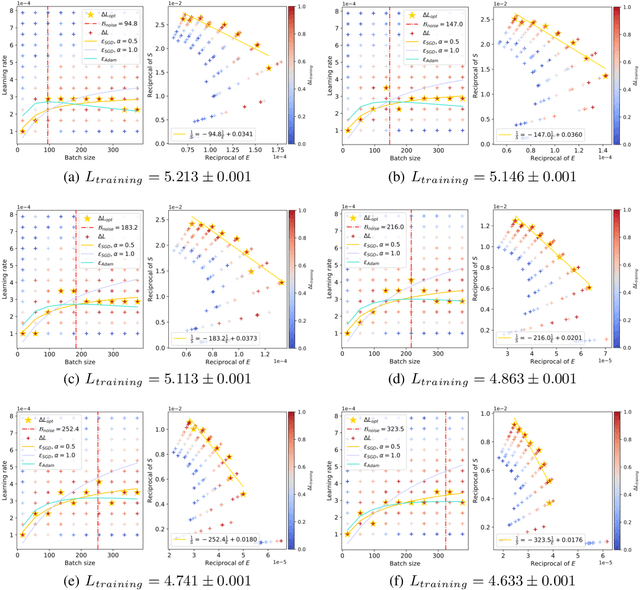
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Spatio-Temporal Fluid Dynamics Modeling via Physical-Awareness and Parameter Diffusion Guidance
Mar 18, 2024This paper proposes a two-stage framework named ST-PAD for spatio-temporal fluid dynamics modeling in the field of earth sciences, aiming to achieve high-precision simulation and prediction of fluid dynamics through spatio-temporal physics awareness and parameter diffusion guidance. In the upstream stage, we design a vector quantization reconstruction module with temporal evolution characteristics, ensuring balanced and resilient parameter distribution by introducing general physical constraints. In the downstream stage, a diffusion probability network involving parameters is utilized to generate high-quality future states of fluids, while enhancing the model's generalization ability by perceiving parameters in various physical setups. Extensive experiments on multiple benchmark datasets have verified the effectiveness and robustness of the ST-PAD framework, which showcase that ST-PAD outperforms current mainstream models in fluid dynamics modeling and prediction, especially in effectively capturing local representations and maintaining significant advantages in OOD generations.
Domain-specific Communication Optimization for Distributed DNN Training
Aug 16, 2020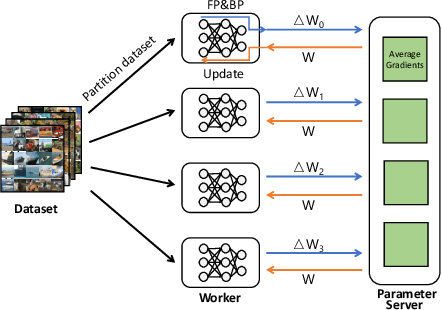

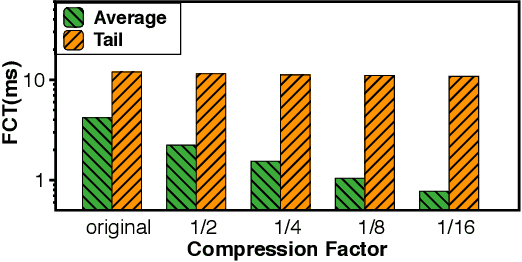
Communication overhead poses an important obstacle to distributed DNN training and draws increasing attention in recent years. Despite continuous efforts, prior solutions such as gradient compression/reduction, compute/communication overlapping and layer-wise flow scheduling, etc., are still coarse-grained and insufficient for an efficient distributed training especially when the network is under pressure. We present DLCP, a novel solution exploiting the domain-specific properties of deep learning to optimize communication overhead of DNN training in a fine-grained manner. At its heart, DLCP comprises of several key innovations beyond prior work: e.g., it exploits {\em bounded loss tolerance} of SGD-based training to improve tail communication latency which cannot be avoided purely through gradient compression. It then performs fine-grained packet-level prioritization and dropping, as opposed to flow-level scheduling, based on layers and magnitudes of gradients to further speedup model convergence without affecting accuracy. In addition, it leverages inter-packet order-independency to perform per-packet load balancing without causing classical re-ordering issues. DLCP works with both Parameter Server and collective communication routines. We have implemented DLCP with commodity switches, integrated it with various training frameworks including TensorFlow, MXNet and PyTorch, and deployed it in our small-scale testbed with 10 Nvidia V100 GPUs. Our testbed experiments and large-scale simulations show that DLCP delivers up to $84.3\%$ additional training acceleration over the best existing solutions.
Divide-and-Shuffle Synchronization for Distributed Machine Learning
Jul 07, 2020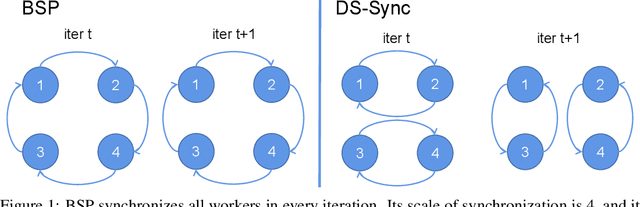
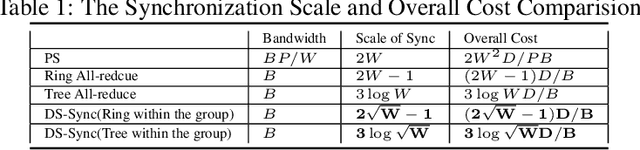

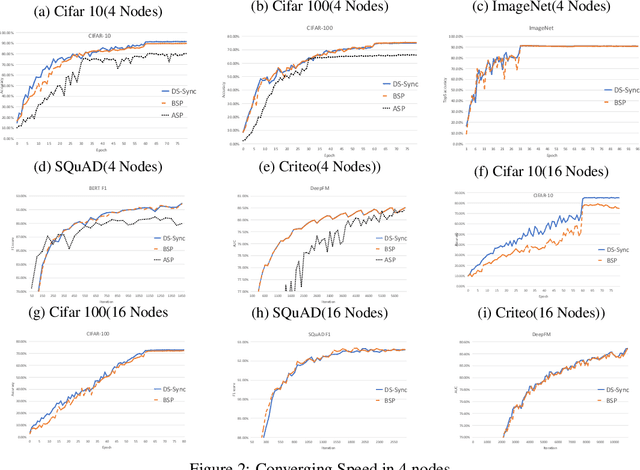
Distributed Machine Learning suffers from the bottleneck of synchronization to all-reduce workers' updates. Previous works mainly consider better network topology, gradient compression, or stale updates to speed up communication and relieve the bottleneck. However, all these works ignore the importance of reducing the scale of synchronized elements and inevitable serial executed operators. To address the problem, our work proposes the Divide-and-Shuffle Synchronization(DS-Sync), which divides workers into several parallel groups and shuffles group members. DS-Sync only synchronizes the workers in the same group so that the scale of a group is much smaller. The shuffle of workers maintains the algorithm's convergence speed, which is interpreted in theory. Comprehensive experiments also show the significant improvements in the latest and popular models like Bert, WideResnet, and DeepFM on challenging datasets.
Quantifying the Performance of Federated Transfer Learning
Dec 30, 2019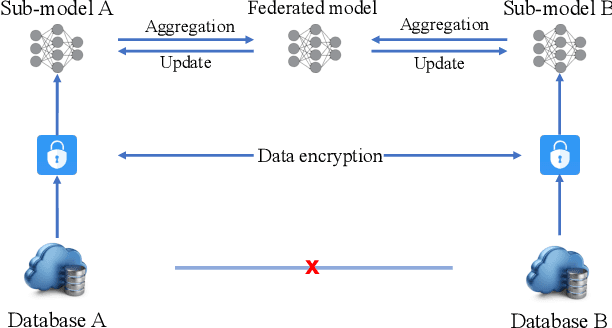
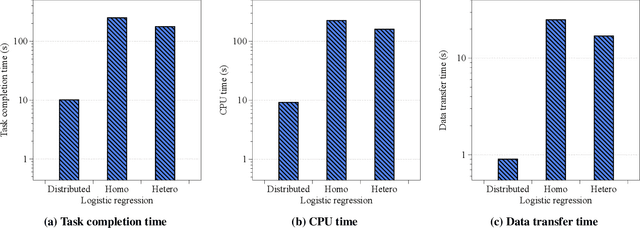
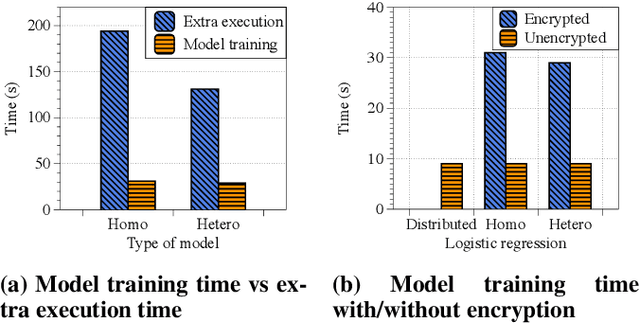
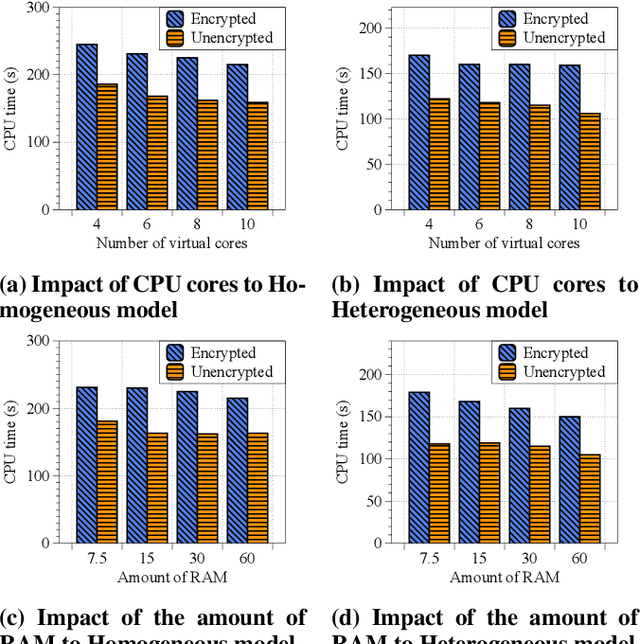
The scarcity of data and isolated data islands encourage different organizations to share data with each other to train machine learning models. However, there are increasing concerns on the problems of data privacy and security, which urges people to seek a solution like Federated Transfer Learning (FTL) to share training data without violating data privacy. FTL leverages transfer learning techniques to utilize data from different sources for training, while achieving data privacy protection without significant accuracy loss. However, the benefits come with a cost of extra computation and communication consumption, resulting in efficiency problems. In order to efficiently deploy and scale up FTL solutions in practice, we need a deep understanding on how the infrastructure affects the efficiency of FTL. Our paper tries to answer this question by quantitatively measuring a real-world FTL implementation FATE on Google Cloud. According to the results of carefully designed experiments, we verified that the following bottlenecks can be further optimized: 1) Inter-process communication is the major bottleneck; 2) Data encryption adds considerable computation overhead; 3) The Internet networking condition affects the performance a lot when the model is large.