 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-specific Communication Optimization for Distributed DNN Training
Aug 16, 2020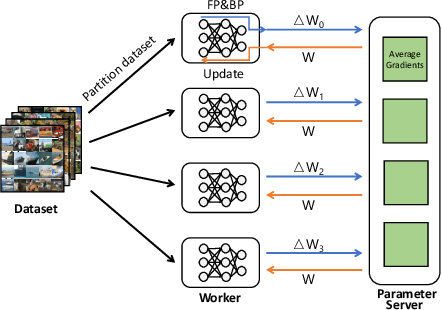

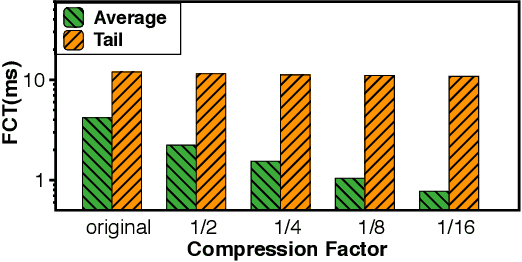
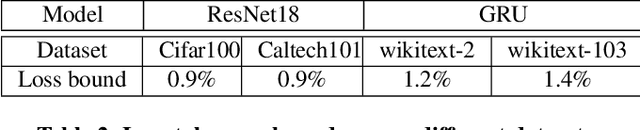
Communication overhead poses an important obstacle to distributed DNN training and draws increasing attention in recent years. Despite continuous efforts, prior solutions such as gradient compression/reduction, compute/communication overlapping and layer-wise flow scheduling, etc., are still coarse-grained and insufficient for an efficient distributed training especially when the network is under pressure. We present DLCP, a novel solution exploiting the domain-specific properties of deep learning to optimize communication overhead of DNN training in a fine-grained manner. At its heart, DLCP comprises of several key innovations beyond prior work: e.g., it exploits {\em bounded loss tolerance} of SGD-based training to improve tail communication latency which cannot be avoided purely through gradient compression. It then performs fine-grained packet-level prioritization and dropping, as opposed to flow-level scheduling, based on layers and magnitudes of gradients to further speedup model convergence without affecting accuracy. In addition, it leverages inter-packet order-independency to perform per-packet load balancing without causing classical re-ordering issues. DLCP works with both Parameter Server and collective communication routines. We have implemented DLCP with commodity switches, integrated it with various training frameworks including TensorFlow, MXNet and PyTorch, and deployed it in our small-scale testbed with 10 Nvidia V100 GPUs. Our testbed experiments and large-scale simulations show that DLCP delivers up to $84.3\%$ additional training acceleration over the best existing solutions.
Divide-and-Shuffle Synchronization for Distributed Machine Learning
Jul 07, 2020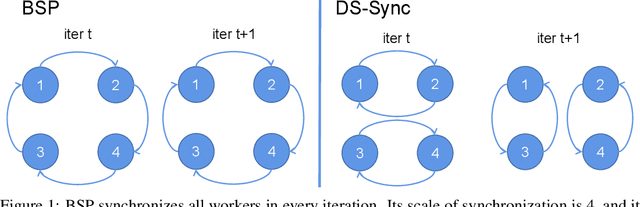
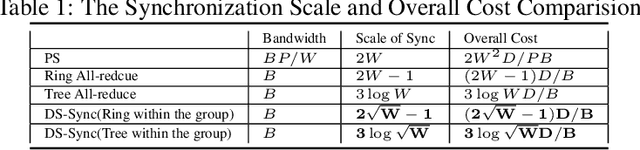

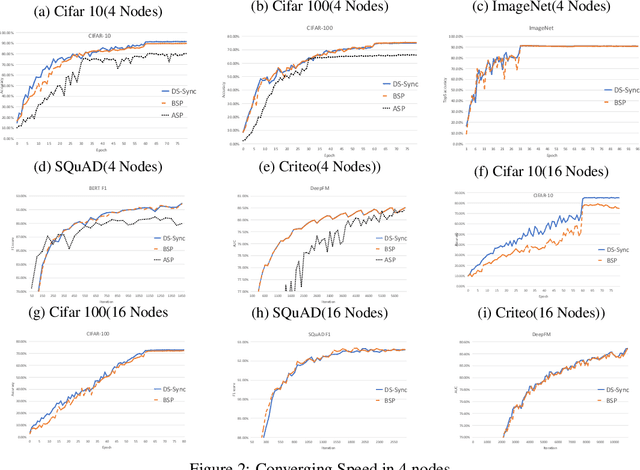
Distributed Machine Learning suffers from the bottleneck of synchronization to all-reduce workers' updates. Previous works mainly consider better network topology, gradient compression, or stale updates to speed up communication and relieve the bottleneck. However, all these works ignore the importance of reducing the scale of synchronized elements and inevitable serial executed operators. To address the problem, our work proposes the Divide-and-Shuffle Synchronization(DS-Sync), which divides workers into several parallel groups and shuffles group members. DS-Sync only synchronizes the workers in the same group so that the scale of a group is much smaller. The shuffle of workers maintains the algorithm's convergence speed, which is interpreted in theory. Comprehensive experiments also show the significant improvements in the latest and popular models like Bert, WideResnet, and DeepFM on challenging datasets.