 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoHeal: An End-to-End System for Personalized Therapeutic Music Retrieval from Fine-grained Emotions
Sep 19, 2025



Existing digital mental wellness tools often overlook the nuanced emotional states underlying everyday challenges. For example, pre-sleep anxiety affects more than 1.5 billion people worldwide, yet current approaches remain largely static and "one-size-fits-all", failing to adapt to individual needs. In this work, we present EmoHeal, an end-to-end system that delivers personalized, three-stage supportive narratives. EmoHeal detects 27 fine-grained emotions from user text with a fine-tuned XLM-RoBERTa model, mapping them to musical parameters via a knowledge graph grounded in music therapy principles (GEMS, iso-principle). EmoHeal retrieves audiovisual content using the CLAMP3 model to guide users from their current state toward a calmer one ("match-guide-target"). A within-subjects study (N=40) demonstrated significant supportive effects, with participants reporting substantial mood improvement (M=4.12, p<0.001) and high perceived emotion recognition accuracy (M=4.05, p<0.001). A strong correlation between perceived accuracy and therapeutic outcome (r=0.72, p<0.001) validates our fine-grained approach. These findings establish the viability of theory-driven, emotion-aware digital wellness tools and provides a scalable AI blueprint for operationalizing music therapy principles.
mFabric: An Efficient and Scalable Fabric for Mixture-of-Experts Training
Jan 07, 2025



Mixture-of-Expert (MoE) models outperform conventional models by selectively activating different subnets, named \emph{experts}, on a per-token basis. This gated computation generates dynamic communications that cannot be determined beforehand, challenging the existing GPU interconnects that remain \emph{static} during the distributed training process. In this paper, we advocate for a first-of-its-kind system, called mFabric, that unlocks topology reconfiguration \emph{during} distributed MoE training. Towards this vision, we first perform a production measurement study and show that the MoE dynamic communication pattern has \emph{strong locality}, alleviating the requirement of global reconfiguration. Based on this, we design and implement a \emph{regionally reconfigurable high-bandwidth domain} on top of existing electrical interconnects using optical circuit switching (OCS), achieving scalability while maintaining rapid adaptability. We have built a fully functional mFabric prototype with commodity hardware and a customized collective communication runtime that trains state-of-the-art MoE models with \emph{in-training} topology reconfiguration across 32 A100 GPUs. Large-scale packet-level simulations show that mFabric delivers comparable performance as the non-blocking fat-tree fabric while boosting the training cost efficiency (e.g., performance per dollar) of four representative MoE models by 1.2$\times$--1.5$\times$ and 1.9$\times$--2.3$\times$ at 100 Gbps and 400 Gbps link bandwidths, respectively.
Towards Fair and Efficient Learning-based Congestion Control
Mar 04, 2024



Recent years have witnessed a plethora of learning-based solutions for congestion control (CC) that demonstrate better performance over traditional TCP schemes. However, they fail to provide consistently good convergence properties, including {\em fairness}, {\em fast convergence} and {\em stability}, due to the mismatch between their objective functions and these properties. Despite being intuitive, integrating these properties into existing learning-based CC is challenging, because: 1) their training environments are designed for the performance optimization of single flow but incapable of cooperative multi-flow optimization, and 2) there is no directly measurable metric to represent these properties into the training objective function. We present Astraea, a new learning-based congestion control that ensures fast convergence to fairness with stability. At the heart of Astraea is a multi-agent deep reinforcement learning framework that explicitly optimizes these convergence properties during the training process by enabling the learning of interactive policy between multiple competing flows, while maintaining high performance. We further build a faithful multi-flow environment that emulates the competing behaviors of concurrent flows, explicitly expressing convergence properties to enable their optimization during training. We have fully implemented Astraea and our comprehensive experiments show that Astraea can quickly converge to fairness point and exhibit better stability than its counterparts. For example, \sys achieves near-optimal bandwidth sharing (i.e., fairness) when multiple flows compete for the same bottleneck, delivers up to 8.4$\times$ faster convergence speed and 2.8$\times$ smaller throughput deviation, while achieving comparable or even better performance over prior solutions.
Domain-specific Communication Optimization for Distributed DNN Training
Aug 16, 2020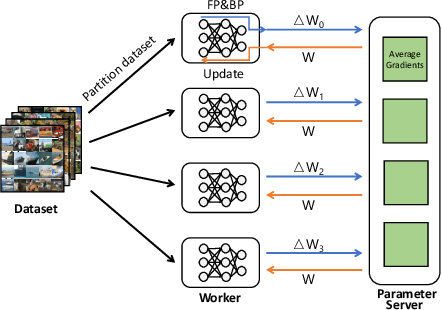

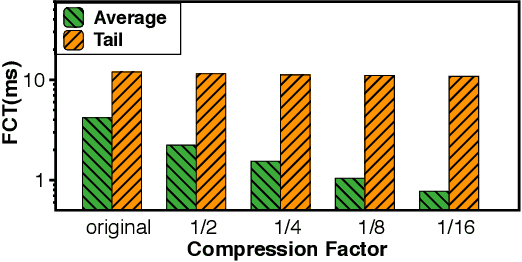
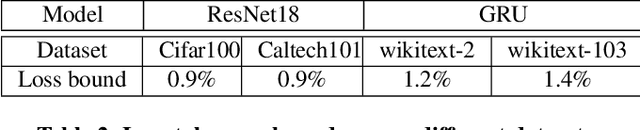
Communication overhead poses an important obstacle to distributed DNN training and draws increasing attention in recent years. Despite continuous efforts, prior solutions such as gradient compression/reduction, compute/communication overlapping and layer-wise flow scheduling, etc., are still coarse-grained and insufficient for an efficient distributed training especially when the network is under pressure. We present DLCP, a novel solution exploiting the domain-specific properties of deep learning to optimize communication overhead of DNN training in a fine-grained manner. At its heart, DLCP comprises of several key innovations beyond prior work: e.g., it exploits {\em bounded loss tolerance} of SGD-based training to improve tail communication latency which cannot be avoided purely through gradient compression. It then performs fine-grained packet-level prioritization and dropping, as opposed to flow-level scheduling, based on layers and magnitudes of gradients to further speedup model convergence without affecting accuracy. In addition, it leverages inter-packet order-independency to perform per-packet load balancing without causing classical re-ordering issues. DLCP works with both Parameter Server and collective communication routines. We have implemented DLCP with commodity switches, integrated it with various training frameworks including TensorFlow, MXNet and PyTorch, and deployed it in our small-scale testbed with 10 Nvidia V100 GPUs. Our testbed experiments and large-scale simulations show that DLCP delivers up to $84.3\%$ additional training acceleration over the best existing solutions.