 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPT: Confusion-Aware Prompt Tuning for Reducing Vision-Language Misalignment
Mar 03, 2026Vision-language models like CLIP have achieved remarkable progress in cross-modal representation learning, yet suffer from systematic misclassifications among visually and semantically similar categories. We observe that such confusion patterns are not random but persistently occur between specific category pairs, revealing the model's intrinsic bias and limited fine-grained discriminative ability. To address this, we propose CAPT, a Confusion-Aware Prompt Tuning framework that enables models to learn from their own misalignment. Specifically, we construct a Confusion Bank to explicitly model stable confusion relationships across categories and misclassified samples. On this basis, we introduce a Semantic Confusion Miner (SEM) to capture global inter-class confusion through semantic difference and commonality prompts, and a Sample Confusion Miner (SAM) to retrieve representative misclassified instances from the bank and capture sample-level cues through a Diff-Manner Adapter that integrates global and local contexts. To further unify confusion information across different granularities, a Multi-Granularity Difference Expert (MGDE) module is designed to jointly leverage semantic- and sample-level experts for more robust confusion-aware reasoning. Extensive experiments on 11 benchmark datasets demonstrate that our method significantly reduces confusion-induced errors while enhancing the discriminability and generalization of both base and novel classes, successfully resolving 50.72 percent of confusable sample pairs. Code will be released at https://github.com/greatest-gourmet/CAPT.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
mFabric: An Efficient and Scalable Fabric for Mixture-of-Experts Training
Jan 07, 2025



Mixture-of-Expert (MoE) models outperform conventional models by selectively activating different subnets, named \emph{experts}, on a per-token basis. This gated computation generates dynamic communications that cannot be determined beforehand, challenging the existing GPU interconnects that remain \emph{static} during the distributed training process. In this paper, we advocate for a first-of-its-kind system, called mFabric, that unlocks topology reconfiguration \emph{during} distributed MoE training. Towards this vision, we first perform a production measurement study and show that the MoE dynamic communication pattern has \emph{strong locality}, alleviating the requirement of global reconfiguration. Based on this, we design and implement a \emph{regionally reconfigurable high-bandwidth domain} on top of existing electrical interconnects using optical circuit switching (OCS), achieving scalability while maintaining rapid adaptability. We have built a fully functional mFabric prototype with commodity hardware and a customized collective communication runtime that trains state-of-the-art MoE models with \emph{in-training} topology reconfiguration across 32 A100 GPUs. Large-scale packet-level simulations show that mFabric delivers comparable performance as the non-blocking fat-tree fabric while boosting the training cost efficiency (e.g., performance per dollar) of four representative MoE models by 1.2$\times$--1.5$\times$ and 1.9$\times$--2.3$\times$ at 100 Gbps and 400 Gbps link bandwidths, respectively.
Source-free Semantic Regularization Learning for Semi-supervised Domain Adaptation
Jan 02, 2025



Semi-supervised domain adaptation (SSDA) has been extensively researched due to its ability to improve classification performance and generalization ability of models by using a small amount of labeled data on the target domain. However, existing methods cannot effectively adapt to the target domain due to difficulty in fully learning rich and complex target semantic information and relationships. In this paper, we propose a novel SSDA learning framework called semantic regularization learning (SERL), which captures the target semantic information from multiple perspectives of regularization learning to achieve adaptive fine-tuning of the source pre-trained model on the target domain. SERL includes three robust semantic regularization techniques. Firstly, semantic probability contrastive regularization (SPCR) helps the model learn more discriminative feature representations from a probabilistic perspective, using semantic information on the target domain to understand the similarities and differences between samples. Additionally, adaptive weights in SPCR can help the model learn the semantic distribution correctly through the probabilities of different samples. To further comprehensively understand the target semantic distribution, we introduce hard-sample mixup regularization (HMR), which uses easy samples as guidance to mine the latent target knowledge contained in hard samples, thereby learning more complete and complex target semantic knowledge. Finally, target prediction regularization (TPR) regularizes the target predictions of the model by maximizing the correlation between the current prediction and the past learned objective, thereby mitigating the misleading of semantic information caused by erroneous pseudo-labels. Extensive experiments on three benchmark datasets demonstrate that our SERL method achieves state-of-the-art performance.
Learning from Different Samples: A Source-free Framework for Semi-supervised Domain Adaptation
Nov 11, 2024Semi-supervised domain adaptation (SSDA) has been widely studied due to its ability to utilize a few labeled target data to improve the generalization ability of the model. However, existing methods only consider designing certain strategies for target samples to adapt, ignoring the exploration of customized learning for different target samples. When the model encounters complex target distribution, existing methods will perform limited due to the inability to clearly and comprehensively learn the knowledge of multiple types of target samples. To fill this gap, this paper focuses on designing a framework to use different strategies for comprehensively mining different target samples. We propose a novel source-free framework (SOUF) to achieve semi-supervised fine-tuning of the source pre-trained model on the target domain. Different from existing SSDA methods, SOUF decouples SSDA from the perspectives of different target samples, specifically designing robust learning techniques for unlabeled, reliably labeled, and noisy pseudo-labeled target samples. For unlabeled target samples, probability-based weighted contrastive learning (PWC) helps the model learn more discriminative feature representations. To mine the latent knowledge of labeled target samples, reliability-based mixup contrastive learning (RMC) learns complex knowledge from the constructed reliable sample set. Finally, predictive regularization learning (PR) further mitigates the misleading effect of noisy pseudo-labeled samples on the model. Extensive experiments on benchmark datasets demonstrate the superiority of our framework over state-of-the-art methods.
Learning Robust Correlation with Foundation Model for Weakly-Supervised Few-Shot Segmentation
May 30, 2024Existing few-shot segmentation (FSS) only considers learning support-query correlation and segmenting unseen categories under the precise pixel masks. However, the cost of a large number of pixel masks during training is expensive. This paper considers a more challenging scenario, weakly-supervised few-shot segmentation (WS-FSS), which only provides category ($i.e.$ image-level) labels. It requires the model to learn robust support-query information when the generated mask is inaccurate. In this work, we design a Correlation Enhancement Network (CORENet) with foundation model, which utilizes multi-information guidance to learn robust correlation. Specifically, correlation-guided transformer (CGT) utilizes self-supervised ViT tokens to learn robust correlation from both local and global perspectives. From the perspective of semantic categories, the class-guided module (CGM) guides the model to locate valuable correlations through the pre-trained CLIP. Finally, the embedding-guided module (EGM) implicitly guides the model to supplement the inevitable information loss during the correlation learning by the original appearance embedding and finally generates the query mask. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ have shown that CORENet exhibits excellent performance compared to existing methods.
RestNet: Boosting Cross-Domain Few-Shot Segmentation with Residual Transformation Network
Sep 14, 2023



Cross-domain few-shot segmentation (CD-FSS) aims to achieve semantic segmentation in previously unseen domains with a limited number of annotated samples. Although existing CD-FSS models focus on cross-domain feature transformation, relying exclusively on inter-domain knowledge transfer may lead to the loss of critical intra-domain information. To this end, we propose a novel residual transformation network (RestNet) that facilitates knowledge transfer while retaining the intra-domain support-query feature information. Specifically, we propose a Semantic Enhanced Anchor Transform (SEAT) module that maps features to a stable domain-agnostic space using advanced semantics. Additionally, an Intra-domain Residual Enhancement (IRE) module is designed to maintain the intra-domain representation of the original discriminant space in the new space. We also propose a mask prediction strategy based on prototype fusion to help the model gradually learn how to segment. Our RestNet can transfer cross-domain knowledge from both inter-domain and intra-domain without requiring additional fine-tuning. Extensive experiments on ISIC, Chest X-ray, and FSS-1000 show that our RestNet achieves state-of-the-art performance. Our code will be available soon.
Semi-supervised Domain Adaptation via Prototype-based Multi-level Learning
May 04, 2023In semi-supervised domain adaptation (SSDA), a few labeled target samples of each class help the model to transfer knowledge representation from the fully labeled source domain to the target domain. Many existing methods ignore the benefits of making full use of the labeled target samples from multi-level. To make better use of this additional data, we propose a novel Prototype-based Multi-level Learning (ProML) framework to better tap the potential of labeled target samples. To achieve intra-domain adaptation, we first introduce a pseudo-label aggregation based on the intra-domain optimal transport to help the model align the feature distribution of unlabeled target samples and the prototype. At the inter-domain level, we propose a cross-domain alignment loss to help the model use the target prototype for cross-domain knowledge transfer. We further propose a dual consistency based on prototype similarity and linear classifier to promote discriminative learning of compact target feature representation at the batch level. Extensive experiments on three datasets, including DomainNet, VisDA2017, and Office-Home demonstrate that our proposed method achieves state-of-the-art performance in SSDA.
HAFLO: GPU-Based Acceleration for Federated Logistic Regression
Aug 22, 2021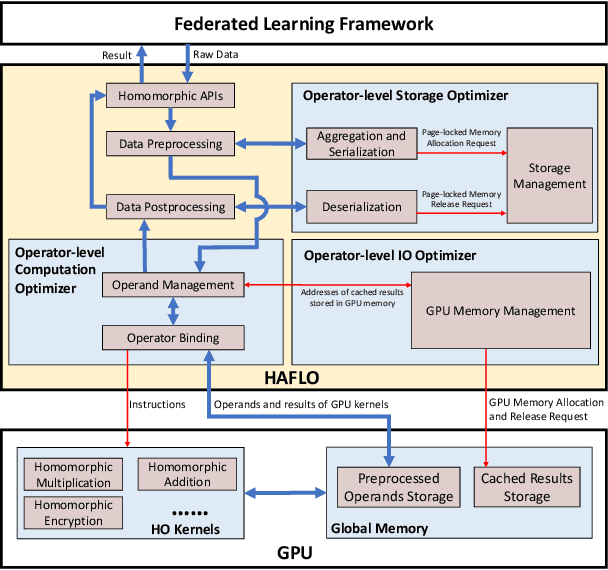

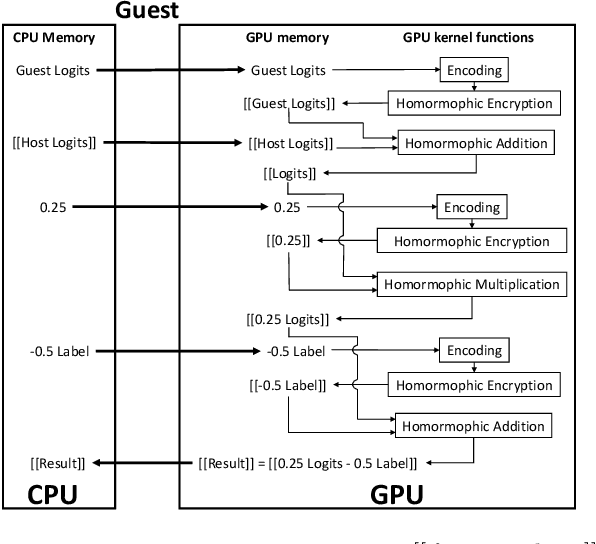

In recent years, federated learning (FL) has been widely applied for supporting decentralized collaborative learning scenarios. Among existing FL models, federated logistic regression (FLR) is a widely used statistic model and has been used in various industries. To ensure data security and user privacy, FLR leverages homomorphic encryption (HE) to protect the exchanged data among different collaborative parties. However, HE introduces significant computational overhead (i.e., the cost of data encryption/decryption and calculation over encrypted data), which eventually becomes the performance bottleneck of the whole system. In this paper, we propose HAFLO, a GPU-based solution to improve the performance of FLR. The core idea of HAFLO is to summarize a set of performance-critical homomorphic operators (HO) used by FLR and accelerate the execution of these operators through a joint optimization of storage, IO, and computation. The preliminary results show that our acceleration on FATE, a popular FL framework, achieves a 49.9$\times$ speedup for heterogeneous LR and 88.4$\times$ for homogeneous LR.