 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
Oct 15, 2024



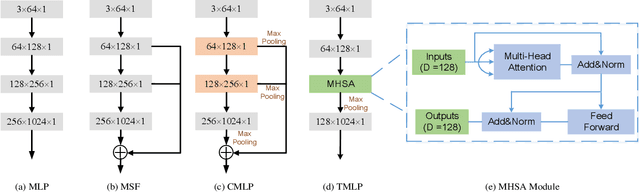
Affordance understanding, the task of identifying actionable regions on 3D objects, plays a vital role in allowing robotic systems to engage with and operate within the physical world. Although Visual Language Models (VLMs) have excelled in high-level reasoning and long-horizon planning for robotic manipulation, they still fall short in grasping the nuanced physical properties required for effective human-robot interaction. In this paper, we introduce PAVLM (Point cloud Affordance Vision-Language Model), an innovative framework that utilizes the extensive multimodal knowledge embedded in pre-trained language models to enhance 3D affordance understanding of point cloud. PAVLM integrates a geometric-guided propagation module with hidden embeddings from large language models (LLMs) to enrich visual semantics. On the language side, we prompt Llama-3.1 models to generate refined context-aware text, augmenting the instructional input with deeper semantic cues. Experimental results on the 3D-AffordanceNet benchmark demonstrate that PAVLM outperforms baseline methods for both full and partial point clouds, particularly excelling in its generalization to novel open-world affordance tasks of 3D objects. For more information, visit our project site: pavlm-source.github.io.
CASE: Commonsense-Augmented Score with an Expanded Answer Space
Nov 03, 2023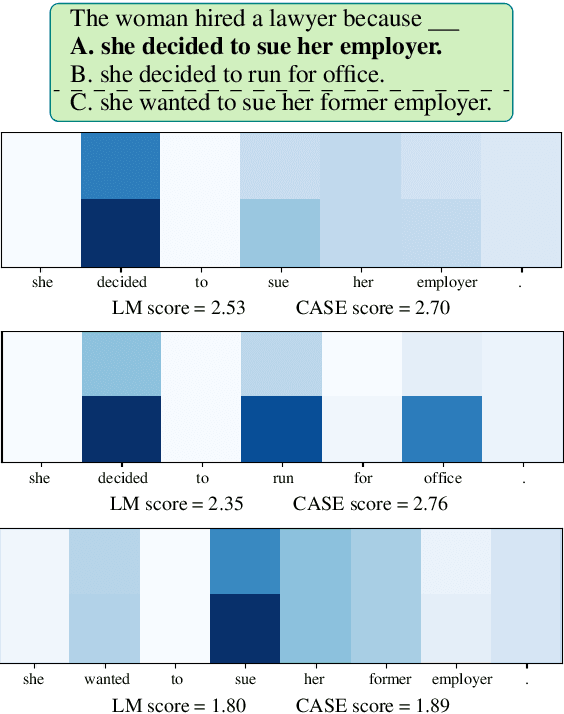
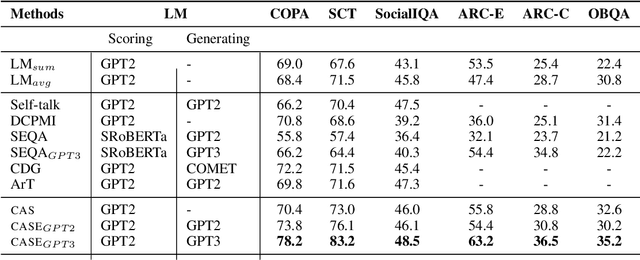
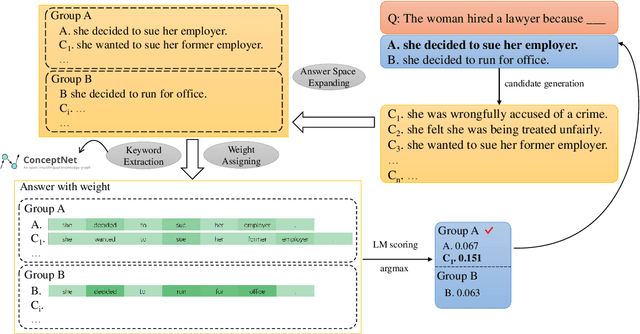
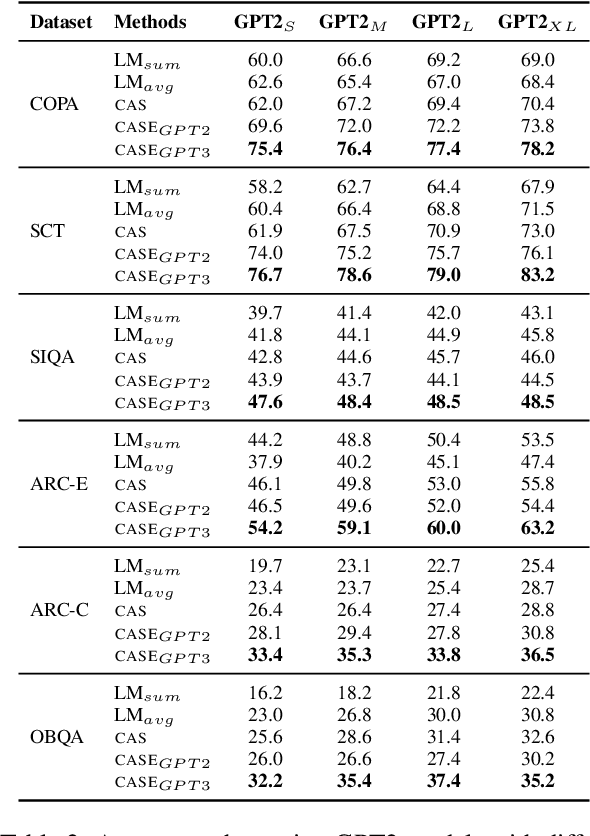
LLMs have demonstrated impressive zero-shot performance on NLP tasks thanks to the knowledge they acquired in their training. In multiple-choice QA tasks, the LM probabilities are used as an imperfect measure of the plausibility of each answer choice. One of the major limitations of the basic score is that it treats all words as equally important. We propose CASE, a Commonsense-Augmented Score with an Expanded Answer Space. CASE addresses this limitation by assigning importance weights for individual words based on their semantic relations to other words in the input. The dynamic weighting approach outperforms basic LM scores, not only because it reduces noise from unimportant words, but also because it informs the model of implicit commonsense knowledge that may be useful for answering the question. We then also follow prior work in expanding the answer space by generating lexically-divergent answers that are conceptually-similar to the choices. When combined with answer space expansion, our method outperforms strong baselines on 5 commonsense benchmarks. We further show these two approaches are complementary and may be especially beneficial when using smaller LMs.
RestNet: Boosting Cross-Domain Few-Shot Segmentation with Residual Transformation Network
Sep 14, 2023



Cross-domain few-shot segmentation (CD-FSS) aims to achieve semantic segmentation in previously unseen domains with a limited number of annotated samples. Although existing CD-FSS models focus on cross-domain feature transformation, relying exclusively on inter-domain knowledge transfer may lead to the loss of critical intra-domain information. To this end, we propose a novel residual transformation network (RestNet) that facilitates knowledge transfer while retaining the intra-domain support-query feature information. Specifically, we propose a Semantic Enhanced Anchor Transform (SEAT) module that maps features to a stable domain-agnostic space using advanced semantics. Additionally, an Intra-domain Residual Enhancement (IRE) module is designed to maintain the intra-domain representation of the original discriminant space in the new space. We also propose a mask prediction strategy based on prototype fusion to help the model gradually learn how to segment. Our RestNet can transfer cross-domain knowledge from both inter-domain and intra-domain without requiring additional fine-tuning. Extensive experiments on ISIC, Chest X-ray, and FSS-1000 show that our RestNet achieves state-of-the-art performance. Our code will be available soon.
Semi-supervised Domain Adaptation via Prototype-based Multi-level Learning
May 04, 2023In semi-supervised domain adaptation (SSDA), a few labeled target samples of each class help the model to transfer knowledge representation from the fully labeled source domain to the target domain. Many existing methods ignore the benefits of making full use of the labeled target samples from multi-level. To make better use of this additional data, we propose a novel Prototype-based Multi-level Learning (ProML) framework to better tap the potential of labeled target samples. To achieve intra-domain adaptation, we first introduce a pseudo-label aggregation based on the intra-domain optimal transport to help the model align the feature distribution of unlabeled target samples and the prototype. At the inter-domain level, we propose a cross-domain alignment loss to help the model use the target prototype for cross-domain knowledge transfer. We further propose a dual consistency based on prototype similarity and linear classifier to promote discriminative learning of compact target feature representation at the batch level. Extensive experiments on three datasets, including DomainNet, VisDA2017, and Office-Home demonstrate that our proposed method achieves state-of-the-art performance in SSDA.
Learning 6-DoF Task-oriented Grasp Detection via Implicit Estimation and Visual Affordance
Oct 16, 2022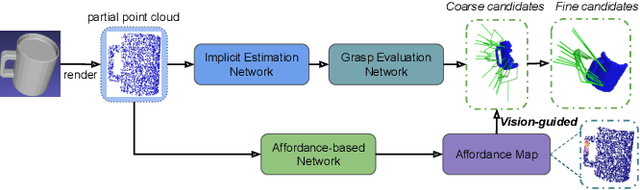

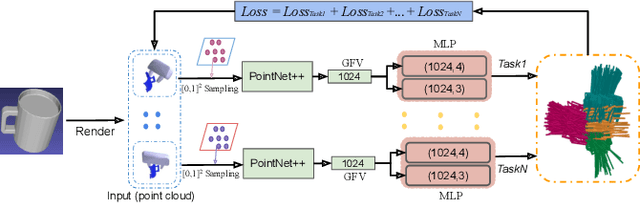
Currently, task-oriented grasp detection approaches are mostly based on pixel-level affordance detection and semantic segmentation. These pixel-level approaches heavily rely on the accuracy of a 2D affordance mask, and the generated grasp candidates are restricted to a small workspace. To mitigate these limitations, we first construct a novel affordance-based grasp dataset and propose a 6-DoF task-oriented grasp detection framework, which takes the observed object point cloud as input and predicts diverse 6-DoF grasp poses for different tasks. Specifically, our implicit estimation network and visual affordance network in this framework could directly predict coarse grasp candidates, and corresponding 3D affordance heatmap for each potential task, respectively. Furthermore, the grasping scores from coarse grasps are combined with heatmap values to generate more accurate and finer candidates. Our proposed framework shows significant improvements compared to baselines for existing and novel objects on our simulation dataset. Although our framework is trained based on the simulated objects and environment, the final generated grasp candidates can be accurately and stably executed in real robot experiments when the object is randomly placed on a support surface.
Hard Sample Aware Noise Robust Learning for Histopathology Image Classification
Dec 05, 2021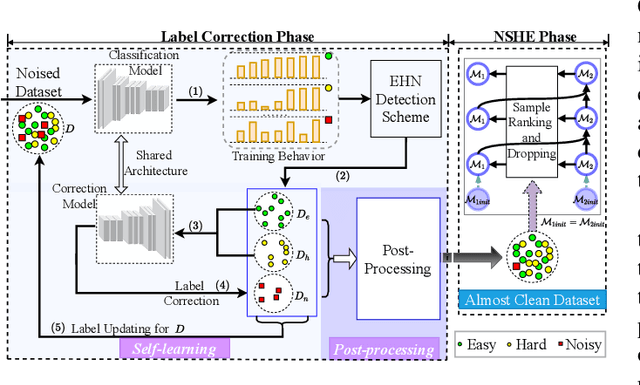
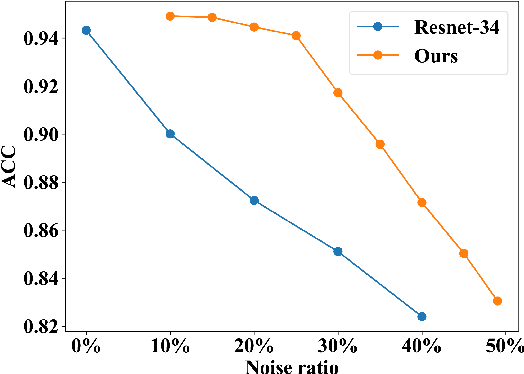
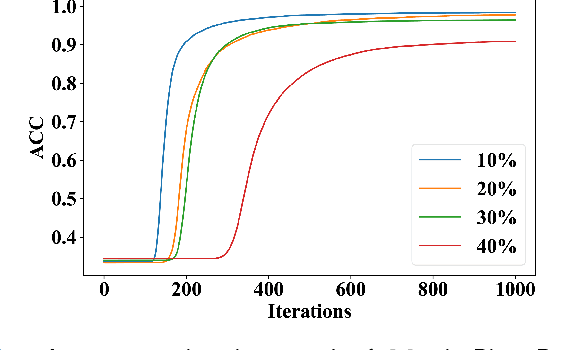
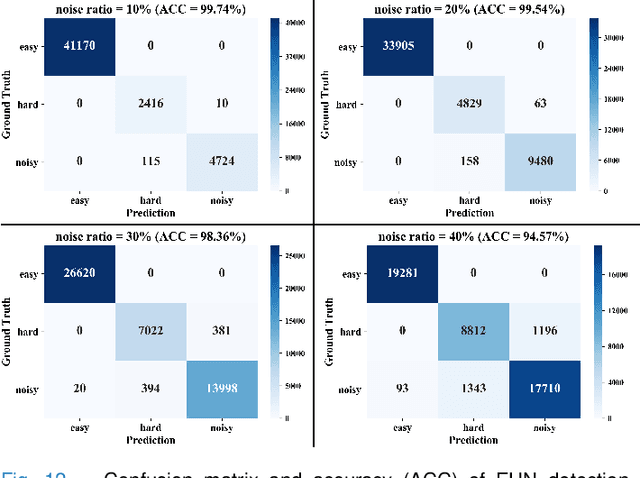
Deep learning-based histopathology image classification is a key technique to help physicians in improving the accuracy and promptness of cancer diagnosis. However, the noisy labels are often inevitable in the complex manual annotation process, and thus mislead the training of the classification model. In this work, we introduce a novel hard sample aware noise robust learning method for histopathology image classification. To distinguish the informative hard samples from the harmful noisy ones, we build an easy/hard/noisy (EHN) detection model by using the sample training history. Then we integrate the EHN into a self-training architecture to lower the noise rate through gradually label correction. With the obtained almost clean dataset, we further propose a noise suppressing and hard enhancing (NSHE) scheme to train the noise robust model. Compared with the previous works, our method can save more clean samples and can be directly applied to the real-world noisy dataset scenario without using a clean subset. Experimental results demonstrate that the proposed scheme outperforms the current state-of-the-art methods in both the synthetic and real-world noisy datasets. The source code and data are available at https://github.com/bupt-ai-cz/HSA-NRL/.
Sample Prior Guided Robust Model Learning to Suppress Noisy Labels
Dec 05, 2021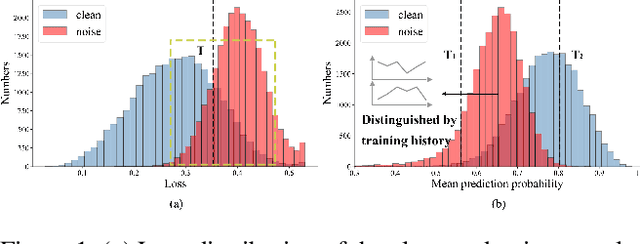
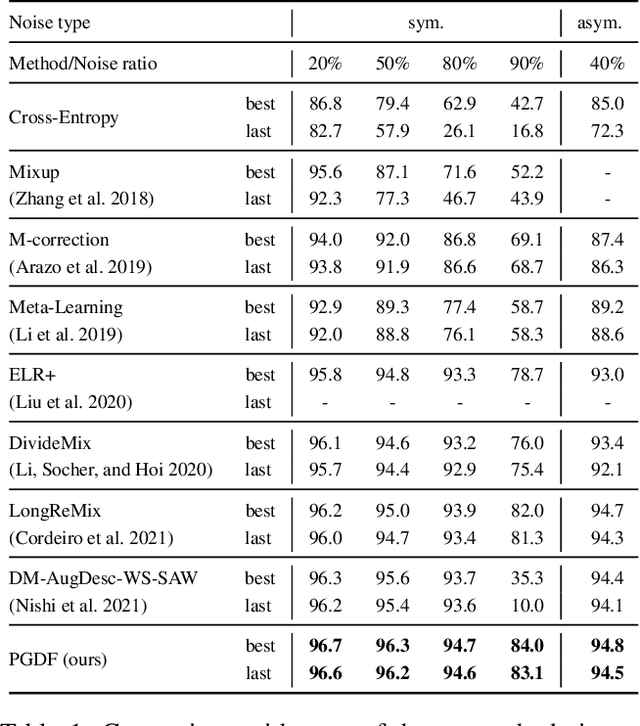
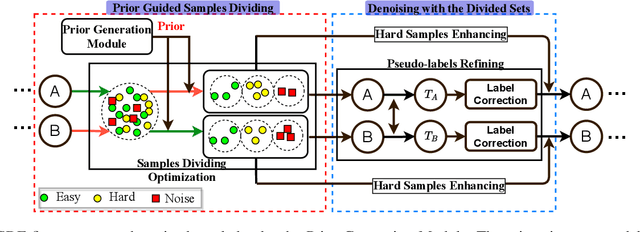
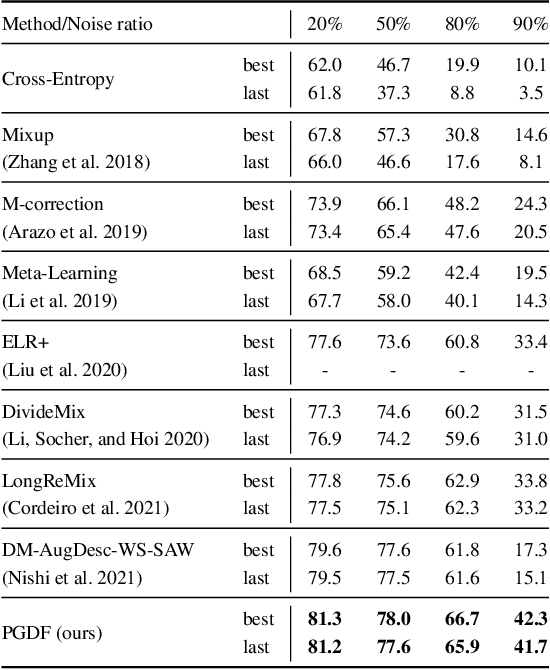
Imperfect labels are ubiquitous in real-world datasets and seriously harm the model performance. Several recent effective methods for handling noisy labels have two key steps: 1) dividing samples into cleanly labeled and wrongly labeled sets by training loss, 2) using semi-supervised methods to generate pseudo-labels for samples in the wrongly labeled set. However, current methods always hurt the informative hard samples due to the similar loss distribution between the hard samples and the noisy ones. In this paper, we proposed PGDF (Prior Guided Denoising Framework), a novel framework to learn a deep model to suppress noise by generating the samples' prior knowledge, which is integrated into both dividing samples step and semi-supervised step. Our framework can save more informative hard clean samples into the cleanly labeled set. Besides, our framework also promotes the quality of pseudo-labels during the semi-supervised step by suppressing the noise in the current pseudo-labels generating scheme. To further enhance the hard samples, we reweight the samples in the cleanly labeled set during training. We evaluated our method using synthetic datasets based on CIFAR-10 and CIFAR-100, as well as on the real-world datasets WebVision and Clothing1M. The results demonstrate substantial improvements over state-of-the-art methods.
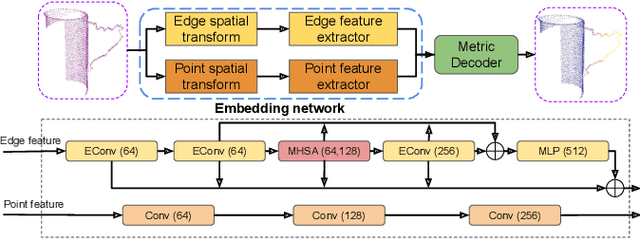
TransSC: Transformer-based Shape Completion for Grasp Evaluation
Jul 01, 2021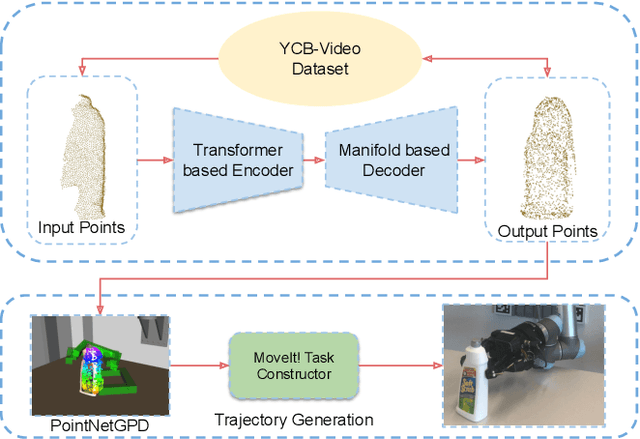
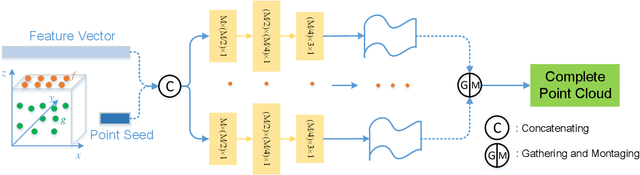
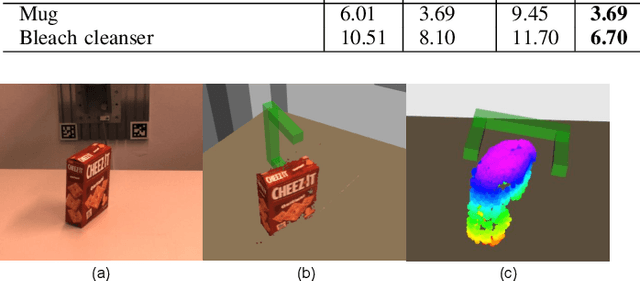
Currently, robotic grasping methods based on sparse partial point clouds have attained a great grasping performance on various objects while they often generate wrong grasping candidates due to the lack of geometric information on the object. In this work, we propose a novel and robust shape completion model (TransSC). This model has a transformer-based encoder to explore more point-wise features and a manifold-based decoder to exploit more object details using a partial point cloud as input. Quantitative experiments verify the effectiveness of the proposed shape completion network and demonstrate it outperforms existing methods. Besides, TransSC is integrated into a grasp evaluation network to generate a set of grasp candidates. The simulation experiment shows that TransSC improves the grasping generation result compared to the existing shape completion baselines. Furthermore, our robotic experiment shows that with TransSC the robot is more successful in grasping objects that are randomly placed on a support surface.
A Semantic-based Method for Unsupervised Commonsense Question Answering
May 31, 2021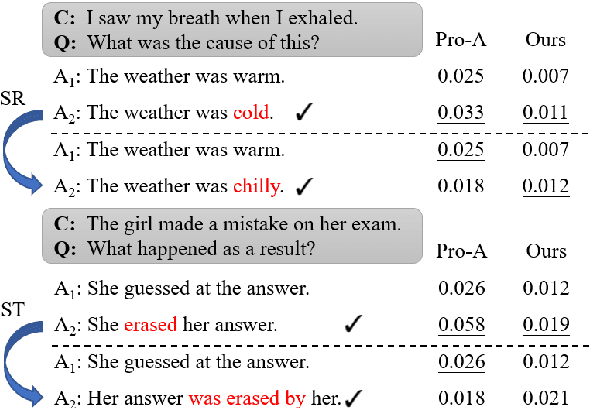

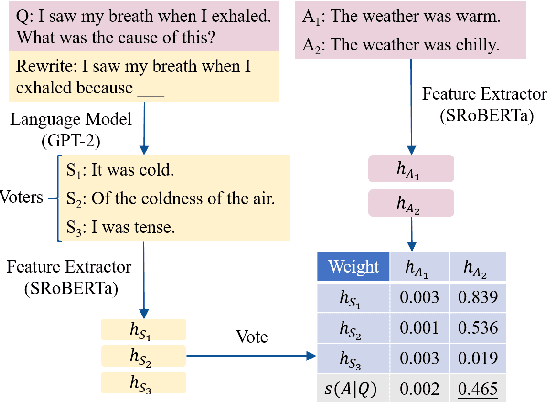
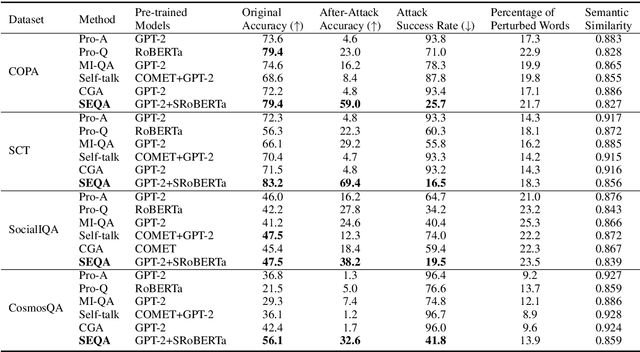
Unsupervised commonsense question answering is appealing since it does not rely on any labeled task data. Among existing work, a popular solution is to use pre-trained language models to score candidate choices directly conditioned on the question or context. However, such scores from language models can be easily affected by irrelevant factors, such as word frequencies, sentence structures, etc. These distracting factors may not only mislead the model to choose a wrong answer but also make it oversensitive to lexical perturbations in candidate answers. In this paper, we present a novel SEmantic-based Question Answering method (SEQA) for unsupervised commonsense question answering. Instead of directly scoring each answer choice, our method first generates a set of plausible answers with generative models (e.g., GPT-2), and then uses these plausible answers to select the correct choice by considering the semantic similarity between each plausible answer and each choice. We devise a simple, yet sound formalism for this idea and verify its effectiveness and robustness with extensive experiments. We evaluate the proposed method on four benchmark datasets, and our method achieves the best results in unsupervised settings. Moreover, when attacked by TextFooler with synonym replacement, SEQA demonstrates much less performance drops than baselines, thereby indicating stronger robustness.