 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Based Pushing and Grasping Objects from Ungraspable Poses
Feb 26, 2023
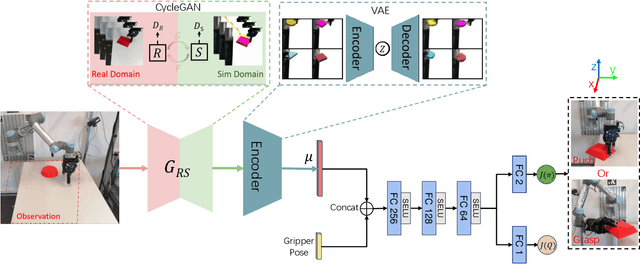


Grasping an object when it is in an ungraspable pose is a challenging task, such as books or other large flat objects placed horizontally on a table. Inspired by human manipulation, we address this problem by pushing the object to the edge of the table and then grasping it from the hanging part. In this paper, we develop a model-free Deep Reinforcement Learning framework to synergize pushing and grasping actions. We first pre-train a Variational Autoencoder to extract high-dimensional features of input scenario images. One Proximal Policy Optimization algorithm with the common reward and sharing layers of Actor-Critic is employed to learn both pushing and grasping actions with high data efficiency. Experiments show that our one network policy can converge 2.5 times faster than the policy using two parallel networks. Moreover, the experiments on unseen objects show that our policy can generalize to the challenging case of objects with curved surfaces and off-center irregularly shaped objects. Lastly, our policy can be transferred to a real robot without fine-tuning by using CycleGAN for domain adaption and outperforms the push-to-wall baseline.
Learning 6-DoF Task-oriented Grasp Detection via Implicit Estimation and Visual Affordance
Oct 16, 2022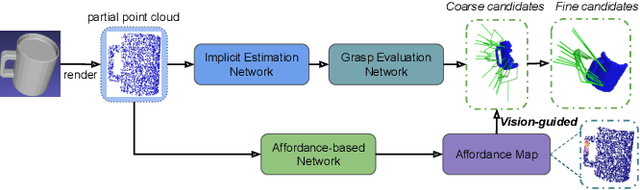

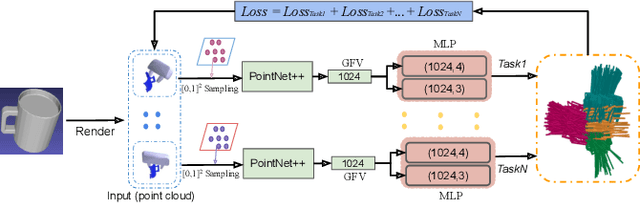
Currently, task-oriented grasp detection approaches are mostly based on pixel-level affordance detection and semantic segmentation. These pixel-level approaches heavily rely on the accuracy of a 2D affordance mask, and the generated grasp candidates are restricted to a small workspace. To mitigate these limitations, we first construct a novel affordance-based grasp dataset and propose a 6-DoF task-oriented grasp detection framework, which takes the observed object point cloud as input and predicts diverse 6-DoF grasp poses for different tasks. Specifically, our implicit estimation network and visual affordance network in this framework could directly predict coarse grasp candidates, and corresponding 3D affordance heatmap for each potential task, respectively. Furthermore, the grasping scores from coarse grasps are combined with heatmap values to generate more accurate and finer candidates. Our proposed framework shows significant improvements compared to baselines for existing and novel objects on our simulation dataset. Although our framework is trained based on the simulated objects and environment, the final generated grasp candidates can be accurately and stably executed in real robot experiments when the object is randomly placed on a support surface.
TransSC: Transformer-based Shape Completion for Grasp Evaluation
Jul 01, 2021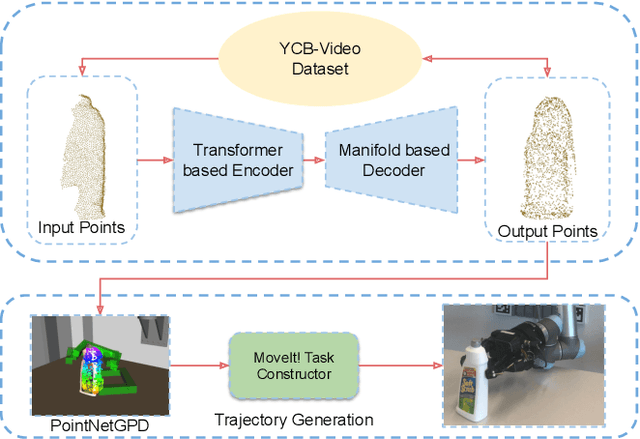
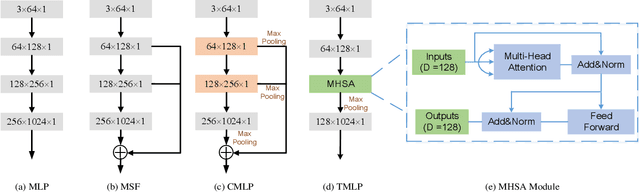
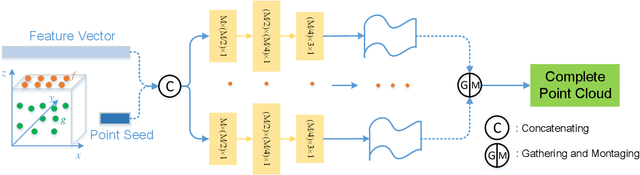
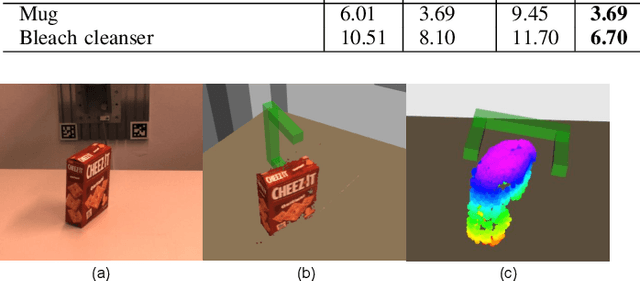
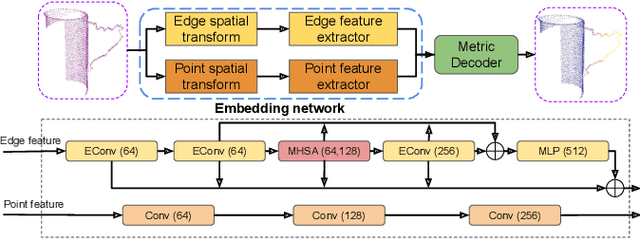
Currently, robotic grasping methods based on sparse partial point clouds have attained a great grasping performance on various objects while they often generate wrong grasping candidates due to the lack of geometric information on the object. In this work, we propose a novel and robust shape completion model (TransSC). This model has a transformer-based encoder to explore more point-wise features and a manifold-based decoder to exploit more object details using a partial point cloud as input. Quantitative experiments verify the effectiveness of the proposed shape completion network and demonstrate it outperforms existing methods. Besides, TransSC is integrated into a grasp evaluation network to generate a set of grasp candidates. The simulation experiment shows that TransSC improves the grasping generation result compared to the existing shape completion baselines. Furthermore, our robotic experiment shows that with TransSC the robot is more successful in grasping objects that are randomly placed on a support surface.
Self-Adapting Recurrent Models for Object Pushing from Learning in Simulation
Jul 27, 2020
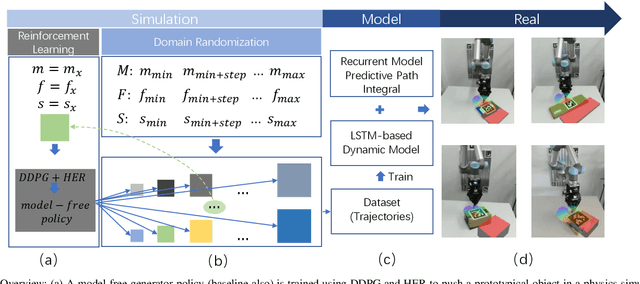
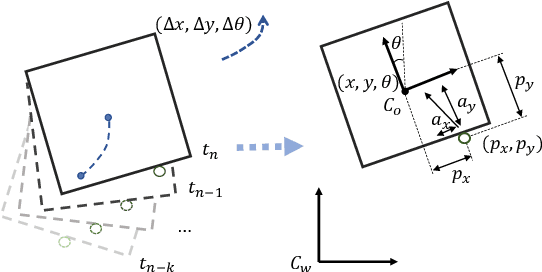
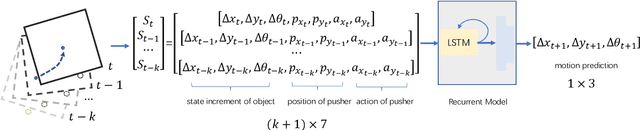
Planar pushing remains a challenging research topic, where building the dynamic model of the interaction is the core issue. Even an accurate analytical dynamic model is inherently unstable because physics parameters such as inertia and friction can only be approximated. Data-driven models usually rely on large amounts of training data, but data collection is time consuming when working with real robots. In this paper, we collect all training data in a physics simulator and build an LSTM-based model to fit the pushing dynamics. Domain Randomization is applied to capture the pushing trajectories of a generalized class of objects. When executed on the real robot, the trained recursive model adapts to the tracked object's real dynamics within a few steps. We propose the algorithm \emph{Recurrent} Model Predictive Path Integral (RMPPI) as a variation of the original MPPI approach, employing state-dependent recurrent models. As a comparison, we also train a Deep Deterministic Policy Gradient (DDPG) network as a model-free baseline, which is also used as the action generator in the data collection phase. During policy training, Hindsight Experience Replay is used to improve exploration efficiency. Pushing experiments on our UR5 platform demonstrate the model's adaptability and the effectiveness of the proposed framework.
A Mobile Robot Hand-Arm Teleoperation System by Vision and IMU
Mar 11, 2020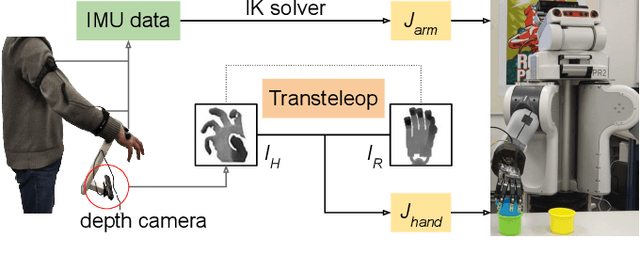
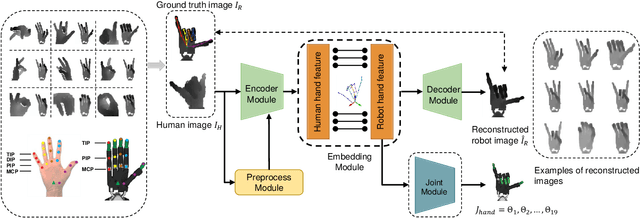


In this paper, we present a multimodal mobile teleoperation system that consists of a novel vision-based hand pose regression network (Transteleop) and an IMU-based arm tracking method. Transteleop observes the human hand through a low-cost depth camera and generates not only joint angles but also depth images of paired robot hand poses through an image-to-image translation process. A keypoint-based reconstruction loss explores the resemblance in appearance and anatomy between human and robotic hands and enriches the local features of reconstructed images. A wearable camera holder enables simultaneous hand-arm control and facilitates the mobility of the whole teleoperation system. Network evaluation results on a test dataset and a variety of complex manipulation tasks that go beyond simple pick-and-place operations show the efficiency and stability of our multimodal teleoperation system.
Robust Robotic Pouring using Audition and Haptics
Feb 29, 2020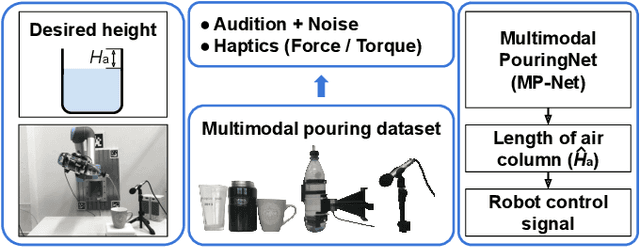
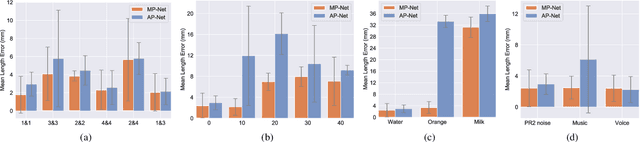
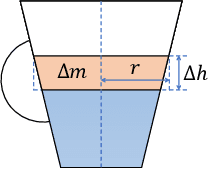
Robust and accurate estimation of liquid height lies as an essential part of pouring tasks for service robots. However, vision-based methods often fail in occluded conditions while audio-based methods cannot work well in a noisy environment. We instead propose a multimodal pouring network (MP-Net) that is able to robustly predict liquid height by conditioning on both audition and haptics input. MP-Net is trained on a self-collected multimodal pouring dataset. This dataset contains 300 robot pouring recordings with audio and force/torque measurements for three types of target containers. We also augment the audio data by inserting robot noise. We evaluated MP-Net on our collected dataset and a wide variety of robot experiments. Both network training results and robot experiments demonstrate that MP-Net is robust against noise and changes to the task and environment. Moreover, we further combine the predicted height and force data to estimate the shape of the target container.
Making Sense of Audio Vibration for Liquid Height Estimation in Robotic Pouring
Mar 02, 2019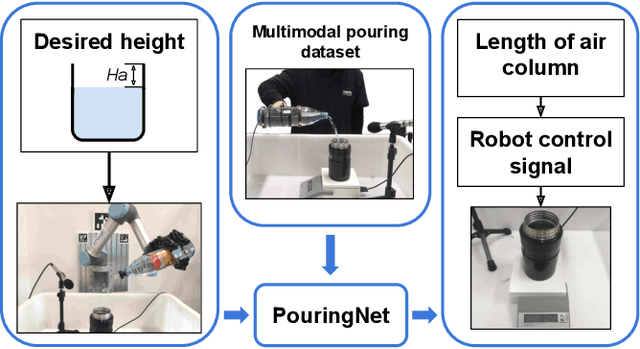
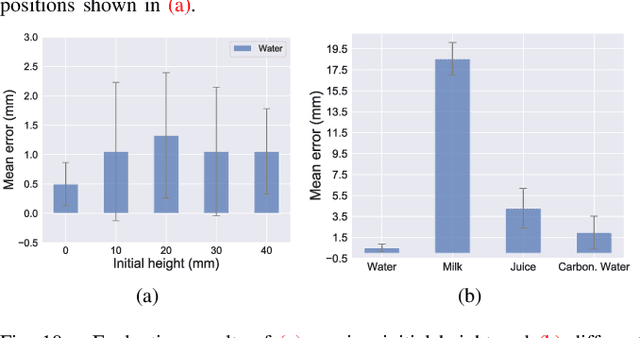
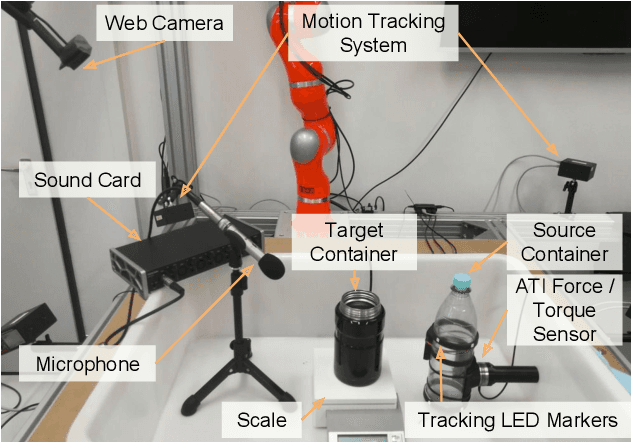
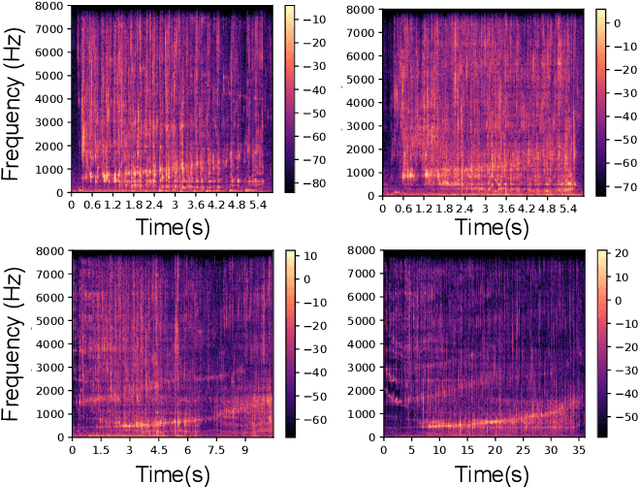
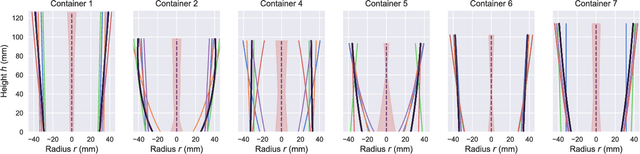
In this paper, we focus on the challenging perception problem in robotic pouring. Most of the existing approaches either leverage visual or haptic information. However, these techniques may suffer from poor generalization performances on opaque containers or concerning measuring precision. To tackle these drawbacks, we propose to make use of audio vibration sensing and design a deep neural network PouringNet to predict the liquid height from the audio fragment during the robotic pouring task. PouringNet is trained on our collected real-world pouring dataset with multimodal sensing data, which contains more than 3000 recordings of audio, force feedback, video and trajectory data of the human hand that performs the pouring task. Each record represents a complete pouring procedure. We conduct several evaluations on PouringNet with our dataset and robotic hardware. The results demonstrate that our PouringNet generalizes well across different liquid containers, positions of the audio receiver, initial liquid heights and types of liquid, and facilitates a more robust and accurate audio-based perception for robotic pouring.
Vision-based Teleoperation of Shadow Dexterous Hand using End-to-End Deep Neural Network
Feb 18, 2019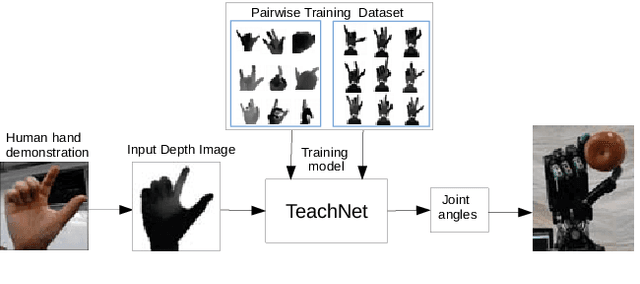
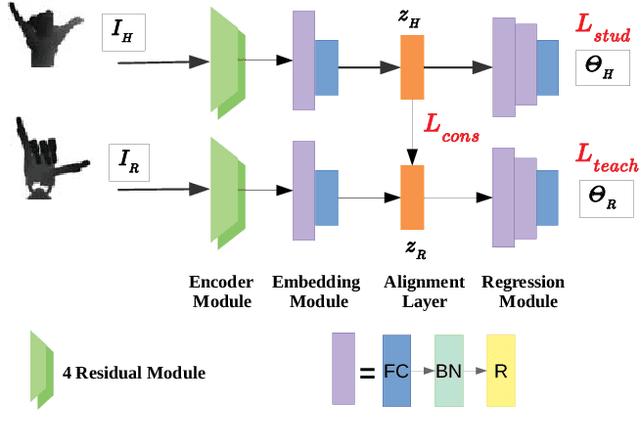
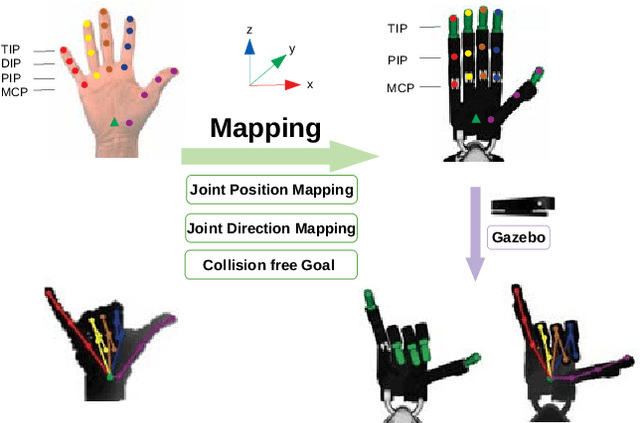

In this paper, we present TeachNet, a novel neural network architecture for intuitive and markerless vision-based teleoperation of dexterous robotic hands. Robot joint angles are directly generated from depth images of the human hand that produce visually similar robot hand poses in an end-to-end fashion. The special structure of TeachNet, combined with a consistency loss function, handles the differences in appearance and anatomy between human and robotic hands. A synchronized human-robot training set is generated from an existing dataset of labeled depth images of the human hand and simulated depth images of a robotic hand. The final training set includes 400K pairwise depth images and joint angles of a Shadow C6 robotic hand. The network evaluation results verify the superiority of TeachNet, especially regarding the high-precision condition. Imitation experiments and grasp tasks teleoperated by novice users demonstrate that TeachNet is more reliable and faster than the state-of-the-art vision-based teleoperation method.
PointNetGPD: Detecting Grasp Configurations from Point Sets
Feb 18, 2019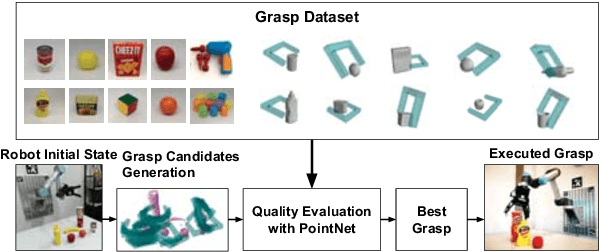
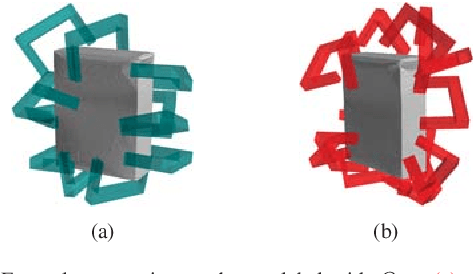
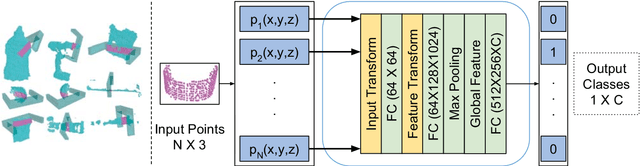
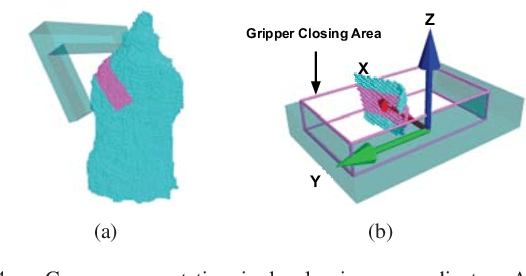
In this paper, we propose an end-to-end grasp evaluation model to address the challenging problem of localizing robot grasp configurations directly from the point cloud. Compared to recent grasp evaluation metrics that are based on handcrafted depth features and a convolutional neural network (CNN), our proposed PointNetGPD is lightweight and can directly process the 3D point cloud that locates within the gripper for grasp evaluation. Taking the raw point cloud as input, our proposed grasp evaluation network can capture the complex geometric structure of the contact area between the gripper and the object even if the point cloud is very sparse. To further improve our proposed model, we generate a larger-scale grasp dataset with 350k real point cloud and grasps with the YCB object set for training. The performance of the proposed model is quantitatively measured both in simulation and on robotic hardware. Experiments on object grasping and clutter removal show that our proposed model generalizes well to novel objects and outperforms state-of-the-art methods. Code and video are available at \href{https://lianghongzhuo.github.io/PointNetGPD}{https://lianghongzhuo.github.io/PointNetGPD}