 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Flow to One Step: Real-Time Multi-Modal Trajectory Policies via Implicit Maximum Likelihood Estimation-based Distribution Distillation
Mar 10, 2026Generative policies based on diffusion and flow matching achieve strong performance in robotic manipulation by modeling multi-modal human demonstrations. However, their reliance on iterative Ordinary Differential Equation (ODE) integration introduces substantial latency, limiting high-frequency closed-loop control. Recent single-step acceleration methods alleviate this overhead but often exhibit distributional collapse, producing averaged trajectories that fail to execute coherent manipulation strategies. We propose a framework that distills a Conditional Flow Matching (CFM) expert into a fast single-step student via Implicit Maximum Likelihood Estimation (IMLE). A bi-directional Chamfer distance provides a set-level objective that promotes both mode coverage and fidelity, enabling preservation of the teacher multi-modal action distribution in a single forward pass. A unified perception encoder further integrates multi-view RGB, depth, point clouds, and proprioception into a geometry-aware representation. The resulting high-frequency control supports real-time receding-horizon re-planning and improved robustness under dynamic disturbances.
M4Diffuser: Multi-View Diffusion Policy with Manipulability-Aware Control for Robust Mobile Manipulation
Sep 18, 2025Mobile manipulation requires the coordinated control of a mobile base and a robotic arm while simultaneously perceiving both global scene context and fine-grained object details. Existing single-view approaches often fail in unstructured environments due to limited fields of view, exploration, and generalization abilities. Moreover, classical controllers, although stable, struggle with efficiency and manipulability near singularities. To address these challenges, we propose M4Diffuser, a hybrid framework that integrates a Multi-View Diffusion Policy with a novel Reduced and Manipulability-aware QP (ReM-QP) controller for mobile manipulation. The diffusion policy leverages proprioceptive states and complementary camera perspectives with both close-range object details and global scene context to generate task-relevant end-effector goals in the world frame. These high-level goals are then executed by the ReM-QP controller, which eliminates slack variables for computational efficiency and incorporates manipulability-aware preferences for robustness near singularities. Comprehensive experiments in simulation and real-world environments show that M4Diffuser achieves 7 to 56 percent higher success rates and reduces collisions by 3 to 31 percent over baselines. Our approach demonstrates robust performance for smooth whole-body coordination, and strong generalization to unseen tasks, paving the way for reliable mobile manipulation in unstructured environments. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/m4diffuser.
DORA: Object Affordance-Guided Reinforcement Learning for Dexterous Robotic Manipulation
May 20, 2025Dexterous robotic manipulation remains a longstanding challenge in robotics due to the high dimensionality of control spaces and the semantic complexity of object interaction. In this paper, we propose an object affordance-guided reinforcement learning framework that enables a multi-fingered robotic hand to learn human-like manipulation strategies more efficiently. By leveraging object affordance maps, our approach generates semantically meaningful grasp pose candidates that serve as both policy constraints and priors during training. We introduce a voting-based grasp classification mechanism to ensure functional alignment between grasp configurations and object affordance regions. Furthermore, we incorporate these constraints into a generalizable RL pipeline and design a reward function that unifies affordance-awareness with task-specific objectives. Experimental results across three manipulation tasks - cube grasping, jug grasping and lifting, and hammer use - demonstrate that our affordance-guided approach improves task success rates by an average of 15.4% compared to baselines. These findings highlight the critical role of object affordance priors in enhancing sample efficiency and learning generalizable, semantically grounded manipulation policies. For more details, please visit our project website https://sites.google.com/view/dora-manip.
LensDFF: Language-enhanced Sparse Feature Distillation for Efficient Few-Shot Dexterous Manipulation
Mar 05, 2025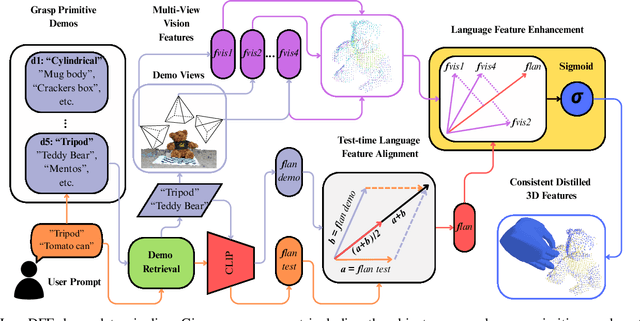
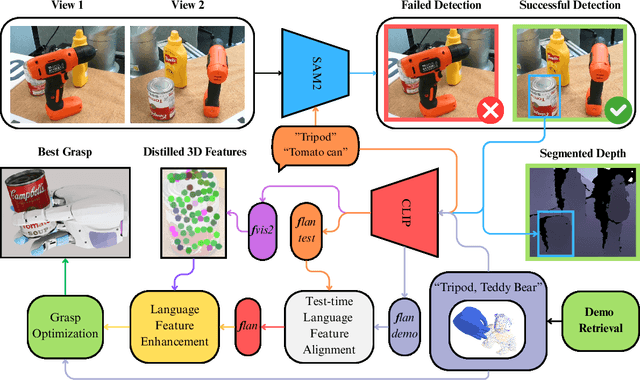

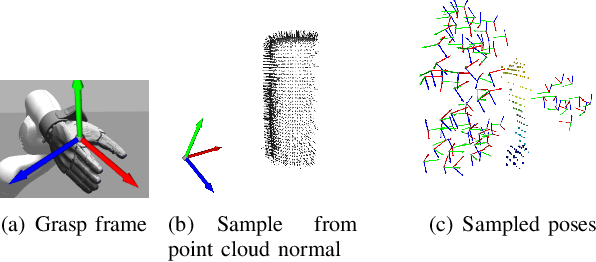
Learning dexterous manipulation from few-shot demonstrations is a significant yet challenging problem for advanced, human-like robotic systems. Dense distilled feature fields have addressed this challenge by distilling rich semantic features from 2D visual foundation models into the 3D domain. However, their reliance on neural rendering models such as Neural Radiance Fields (NeRF) or Gaussian Splatting results in high computational costs. In contrast, previous approaches based on sparse feature fields either suffer from inefficiencies due to multi-view dependencies and extensive training or lack sufficient grasp dexterity. To overcome these limitations, we propose Language-ENhanced Sparse Distilled Feature Field (LensDFF), which efficiently distills view-consistent 2D features onto 3D points using our novel language-enhanced feature fusion strategy, thereby enabling single-view few-shot generalization. Based on LensDFF, we further introduce a few-shot dexterous manipulation framework that integrates grasp primitives into the demonstrations to generate stable and highly dexterous grasps. Moreover, we present a real2sim grasp evaluation pipeline for efficient grasp assessment and hyperparameter tuning. Through extensive simulation experiments based on the real2sim pipeline and real-world experiments, our approach achieves competitive grasping performance, outperforming state-of-the-art approaches.
ClearDepth: Enhanced Stereo Perception of Transparent Objects for Robotic Manipulation
Sep 13, 2024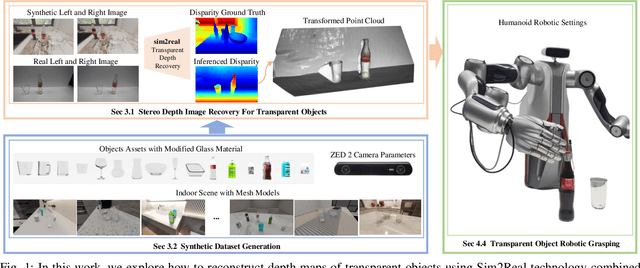
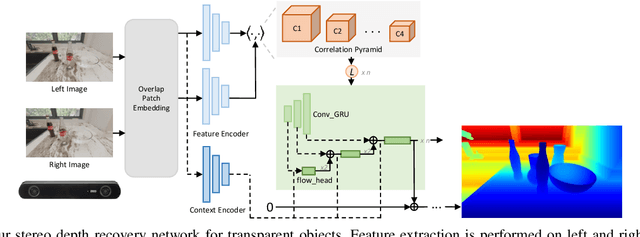
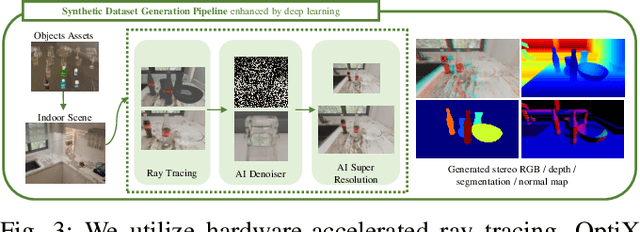

Transparent object depth perception poses a challenge in everyday life and logistics, primarily due to the inability of standard 3D sensors to accurately capture depth on transparent or reflective surfaces. This limitation significantly affects depth map and point cloud-reliant applications, especially in robotic manipulation. We developed a vision transformer-based algorithm for stereo depth recovery of transparent objects. This approach is complemented by an innovative feature post-fusion module, which enhances the accuracy of depth recovery by structural features in images. To address the high costs associated with dataset collection for stereo camera-based perception of transparent objects, our method incorporates a parameter-aligned, domain-adaptive, and physically realistic Sim2Real simulation for efficient data generation, accelerated by AI algorithm. Our experimental results demonstrate the model's exceptional Sim2Real generalizability in real-world scenarios, enabling precise depth mapping of transparent objects to assist in robotic manipulation. Project details are available at https://sites.google.com/view/cleardepth/ .
DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
Jul 24, 2024



We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.
FFHFlow: A Flow-based Variational Approach for Multi-fingered Grasp Synthesis in Real Time
Jul 21, 2024Synthesizing diverse and accurate grasps with multi-fingered hands is an important yet challenging task in robotics. Previous efforts focusing on generative modeling have fallen short of precisely capturing the multi-modal, high-dimensional grasp distribution. To address this, we propose exploiting a special kind of Deep Generative Model (DGM) based on Normalizing Flows (NFs), an expressive model for learning complex probability distributions. Specifically, we first observed an encouraging improvement in diversity by directly applying a single conditional NFs (cNFs), dubbed FFHFlow-cnf, to learn a grasp distribution conditioned on the incomplete point cloud. However, we also recognized limited performance gains due to restricted expressivity in the latent space. This motivated us to develop a novel flow-based d Deep Latent Variable Model (DLVM), namely FFHFlow-lvm, which facilitates more reasonable latent features, leading to both diverse and accurate grasp synthesis for unseen objects. Unlike Variational Autoencoders (VAEs), the proposed DLVM counteracts typical pitfalls such as mode collapse and mis-specified priors by leveraging two cNFs for the prior and likelihood distributions, which are usually restricted to being isotropic Gaussian. Comprehensive experiments in simulation and real-robot scenarios demonstrate that our method generates more accurate and diverse grasps than the VAE baselines. Additionally, a run-time comparison is conducted to reveal its high potential for real-time applications.
Close the Sim2real Gap via Physically-based Structured Light Synthetic Data Simulation
Jul 17, 2024



Despite the substantial progress in deep learning, its adoption in industrial robotics projects remains limited, primarily due to challenges in data acquisition and labeling. Previous sim2real approaches using domain randomization require extensive scene and model optimization. To address these issues, we introduce an innovative physically-based structured light simulation system, generating both RGB and physically realistic depth images, surpassing previous dataset generation tools. We create an RGBD dataset tailored for robotic industrial grasping scenarios and evaluate it across various tasks, including object detection, instance segmentation, and embedding sim2real visual perception in industrial robotic grasping. By reducing the sim2real gap and enhancing deep learning training, we facilitate the application of deep learning models in industrial settings. Project details are available at https://baikaixinpublic.github.io/structured light 3D synthesizer/.
Multi-fingered Robotic Hand Grasping in Cluttered Environments through Hand-object Contact Semantic Mapping
Apr 12, 2024The integration of optimization method and generative models has significantly advanced dexterous manipulation techniques for five-fingered hand grasping. Yet, the application of these techniques in cluttered environments is a relatively unexplored area. To address this research gap, we have developed a novel method for generating five-fingered hand grasp samples in cluttered settings. This method emphasizes simulated grasp quality and the nuanced interaction between the hand and surrounding objects. A key aspect of our approach is our data generation method, capable of estimating contact spatial and semantic representations and affordance grasps based on object affordance information. Furthermore, our Contact Semantic Conditional Variational Autoencoder (CoSe-CVAE) network is adept at creating comprehensive contact maps from point clouds, incorporating both spatial and semantic data. We introduce a unique grasp detection technique that efficiently formulates mechanical hand grasp poses from these maps. Additionally, our evaluation model is designed to assess grasp quality and collision probability, significantly improving the practicality of five-fingered hand grasping in complex scenarios. Our data generation method outperforms previous datasets in grasp diversity, scene diversity, modality diversity. Our grasp generation method has demonstrated remarkable success, outperforming established baselines with 81.0% average success rate in real-world single-object grasping and 75.3% success rate in multi-object grasping. The dataset and supplementary materials can be found at https://sites.google.com/view/ffh-clutteredgrasping, and we will release the code upon publication.
ToolEENet: Tool Affordance 6D Pose Estimation
Apr 05, 2024The exploration of robotic dexterous hands utilizing tools has recently attracted considerable attention. A significant challenge in this field is the precise awareness of a tool's pose when grasped, as occlusion by the hand often degrades the quality of the estimation. Additionally, the tool's overall pose often fails to accurately represent the contact interaction, thereby limiting the effectiveness of vision-guided, contact-dependent activities. To overcome this limitation, we present the innovative TOOLEE dataset, which, to the best of our knowledge, is the first to feature affordance segmentation of a tool's end-effector (EE) along with its defined 6D pose based on its usage. Furthermore, we propose the ToolEENet framework for accurate 6D pose estimation of the tool's EE. This framework begins by segmenting the tool's EE from raw RGBD data, then uses a diffusion model-based pose estimator for 6D pose estimation at a category-specific level. Addressing the issue of symmetry in pose estimation, we introduce a symmetry-aware pose representation that enhances the consistency of pose estimation. Our approach excels in this field, demonstrating high levels of precision and generalization. Furthermore, it shows great promise for application in contact-based manipulation scenarios. All data and codes are available on the project website: https://yuyangtu.github.io/projectToolEENet.html