 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Loop Multi-perspective Visual Servoing Approach with Reinforcement Learning
Dec 25, 2023
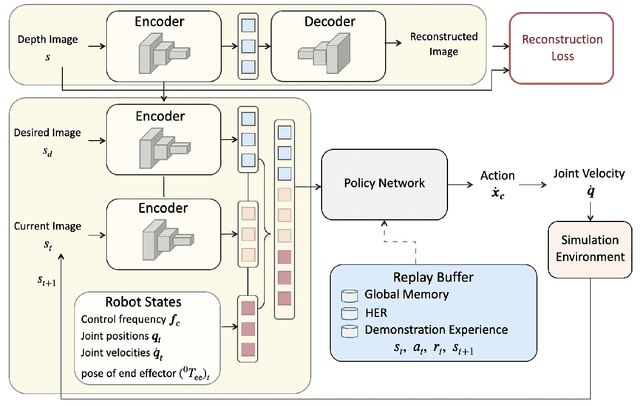
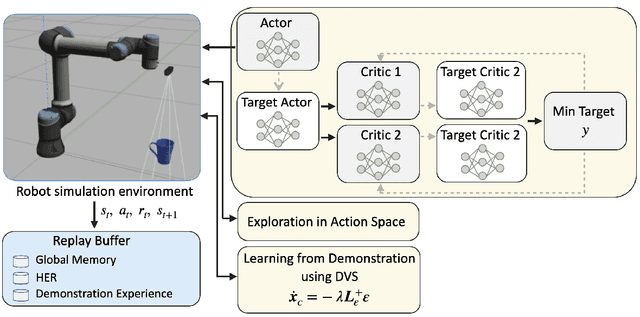
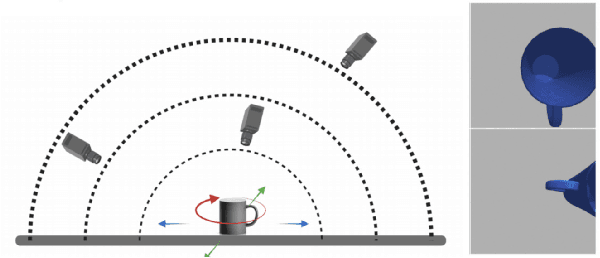
Traditional visual servoing methods suffer from serving between scenes from multiple perspectives, which humans can complete with visual signals alone. In this paper, we investigated how multi-perspective visual servoing could be solved under robot-specific constraints, including self-collision, singularity problems. We presented a novel learning-based multi-perspective visual servoing framework, which iteratively estimates robot actions from latent space representations of visual states using reinforcement learning. Furthermore, our approaches were trained and validated in a Gazebo simulation environment with connection to OpenAI/Gym. Through simulation experiments, we showed that our method can successfully learn an optimal control policy given initial images from different perspectives, and it outperformed the Direct Visual Servoing algorithm with mean success rate of 97.0%.
Subjective Bias in Abstractive Summarization
Jun 18, 2021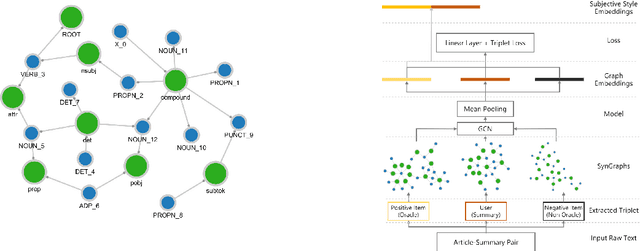

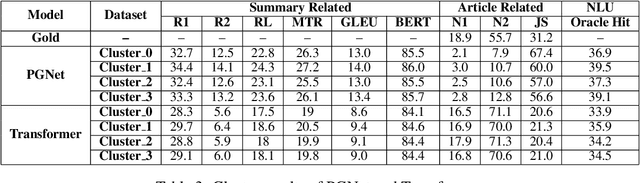
Due to the subjectivity of the summarization, it is a good practice to have more than one gold summary for each training document. However, many modern large-scale abstractive summarization datasets have only one-to-one samples written by different human with different styles. The impact of this phenomenon is understudied. We formulate the differences among possible multiple expressions summarizing the same content as subjective bias and examine the role of this bias in the context of abstractive summarization. In this paper a lightweight and effective method to extract the feature embeddings of subjective styles is proposed. Results of summarization models trained on style-clustered datasets show that there are certain types of styles that lead to better convergence, abstraction and generalization. The reproducible code and generated summaries are available online.