 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
May 21, 2025Recent advances such as DeepSeek R1-Zero highlight the effectiveness of incentive training, a reinforcement learning paradigm that computes rewards solely based on the final answer part of a language model's output, thereby encouraging the generation of intermediate reasoning steps. However, these methods fundamentally rely on external verifiers, which limits their applicability to domains like mathematics and coding where such verifiers are readily available. Although reward models can serve as verifiers, they require high-quality annotated data and are costly to train. In this work, we propose NOVER, NO-VERifier Reinforcement Learning, a general reinforcement learning framework that requires only standard supervised fine-tuning data with no need for an external verifier. NOVER enables incentive training across a wide range of text-to-text tasks and outperforms the model of the same size distilled from large reasoning models such as DeepSeek R1 671B by 7.7 percent. Moreover, the flexibility of NOVER enables new possibilities for optimizing large language models, such as inverse incentive training.
EnigmaToM: Improve LLMs' Theory-of-Mind Reasoning Capabilities with Neural Knowledge Base of Entity States
Mar 05, 2025



Theory-of-Mind (ToM), the ability to infer others' perceptions and mental states, is fundamental to human interaction but remains a challenging task for Large Language Models (LLMs). While existing ToM reasoning methods show promise with reasoning via perceptual perspective-taking, they often rely excessively on LLMs, reducing their efficiency and limiting their applicability to high-order ToM reasoning, which requires multi-hop reasoning about characters' beliefs. To address these issues, we present EnigmaToM, a novel neuro-symbolic framework that enhances ToM reasoning by integrating a Neural Knowledge Base of entity states (Enigma) for (1) a psychology-inspired iterative masking mechanism that facilitates accurate perspective-taking and (2) knowledge injection that elicits key entity information. Enigma generates structured representations of entity states, which construct spatial scene graphs -- leveraging spatial information as an inductive bias -- for belief tracking of various ToM orders and enhancing events with fine-grained entity state details. Experimental results on multiple benchmarks, including ToMi, HiToM, and FANToM, show that EnigmaToM significantly improves ToM reasoning across LLMs of varying sizes, particularly excelling in high-order reasoning scenarios.
Evaluating LLMs' Assessment of Mixed-Context Hallucination Through the Lens of Summarization
Mar 03, 2025With the rapid development of large language models (LLMs), LLM-as-a-judge has emerged as a widely adopted approach for text quality evaluation, including hallucination evaluation. While previous studies have focused exclusively on single-context evaluation (e.g., discourse faithfulness or world factuality), real-world hallucinations typically involve mixed contexts, which remains inadequately evaluated. In this study, we use summarization as a representative task to comprehensively evaluate LLMs' capability in detecting mixed-context hallucinations, specifically distinguishing between factual and non-factual hallucinations. Through extensive experiments across direct generation and retrieval-based models of varying scales, our main observations are: (1) LLMs' intrinsic knowledge introduces inherent biases in hallucination evaluation; (2) These biases particularly impact the detection of factual hallucinations, yielding a significant performance bottleneck; (3) The fundamental challenge lies in effective knowledge utilization, balancing between LLMs' intrinsic knowledge and external context for accurate mixed-context hallucination evaluation.
Can LLMs Simulate L2-English Dialogue? An Information-Theoretic Analysis of L1-Dependent Biases
Feb 20, 2025This study evaluates Large Language Models' (LLMs) ability to simulate non-native-like English use observed in human second language (L2) learners interfered with by their native first language (L1). In dialogue-based interviews, we prompt LLMs to mimic L2 English learners with specific L1s (e.g., Japanese, Thai, Urdu) across seven languages, comparing their outputs to real L2 learner data. Our analysis examines L1-driven linguistic biases, such as reference word usage and avoidance behaviors, using information-theoretic and distributional density measures. Results show that modern LLMs (e.g., Qwen2.5, LLAMA3.3, DeepseekV3, GPT-4o) replicate L1-dependent patterns observed in human L2 data, with distinct influences from various languages (e.g., Japanese, Korean, and Mandarin significantly affect tense agreement, and Urdu influences noun-verb collocations). Our results reveal the potential of LLMs for L2 dialogue generation and evaluation for future educational applications.
Can We Catch the Elephant? The Evolvement of Hallucination Evaluation on Natural Language Generation: A Survey
Apr 18, 2024Hallucination in Natural Language Generation (NLG) is like the elephant in the room, obvious but often overlooked until recent achievements significantly improved the fluency and grammatical accuracy of generated text. For Large Language Models (LLMs), hallucinations can happen in various downstream tasks and casual conversations, which need accurate assessment to enhance reliability and safety. However, current studies on hallucination evaluation vary greatly, and people still find it difficult to sort out and select the most appropriate evaluation methods. Moreover, as NLP research gradually shifts to the domain of LLMs, it brings new challenges to this direction. This paper provides a comprehensive survey on the evolvement of hallucination evaluation methods, aiming to address three key aspects: 1) Diverse definitions and granularity of facts; 2) The categories of automatic evaluators and their applicability; 3) Unresolved issues and future directions.
Subjective Bias in Abstractive Summarization
Jun 18, 2021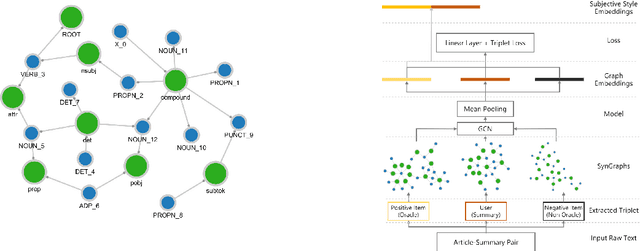

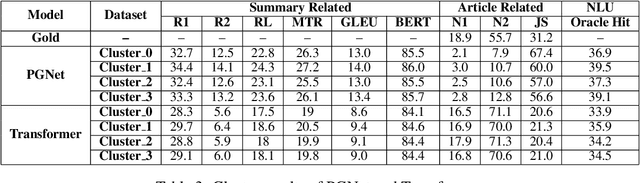
Due to the subjectivity of the summarization, it is a good practice to have more than one gold summary for each training document. However, many modern large-scale abstractive summarization datasets have only one-to-one samples written by different human with different styles. The impact of this phenomenon is understudied. We formulate the differences among possible multiple expressions summarizing the same content as subjective bias and examine the role of this bias in the context of abstractive summarization. In this paper a lightweight and effective method to extract the feature embeddings of subjective styles is proposed. Results of summarization models trained on style-clustered datasets show that there are certain types of styles that lead to better convergence, abstraction and generalization. The reproducible code and generated summaries are available online.