 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Apr 07, 2026While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
Who Wrote the Book? Detecting and Attributing LLM Ghostwriters
Mar 30, 2026In this paper, we introduce GhostWriteBench, a dataset for LLM authorship attribution. It comprises long-form texts (50K+ words per book) generated by frontier LLMs, and is designed to test generalisation across multiple out-of-distribution (OOD) dimensions, including domain and unseen LLM author. We also propose TRACE -- a novel fingerprinting method that is interpretable and lightweight -- that works for both open- and closed-source models. TRACE creates the fingerprint by capturing token-level transition patterns (e.g., word rank) estimated by another lightweight language model. Experiments on GhostWriteBench demonstrate that TRACE achieves state-of-the-art performance, remains robust in OOD settings, and works well in limited training data scenarios.
Predicting Sentence Acceptability Judgments in Multimodal Contexts
Feb 24, 2026Previous work has examined the capacity of deep neural networks (DNNs), particularly transformers, to predict human sentence acceptability judgments, both independently of context, and in document contexts. We consider the effect of prior exposure to visual images (i.e., visual context) on these judgments for humans and large language models (LLMs). Our results suggest that, in contrast to textual context, visual images appear to have little if any impact on human acceptability ratings. However, LLMs display the compression effect seen in previous work on human judgments in document contexts. Different sorts of LLMs are able to predict human acceptability judgments to a high degree of accuracy, but in general, their performance is slightly better when visual contexts are removed. Moreover, the distribution of LLM judgments varies among models, with Qwen resembling human patterns, and others diverging from them. LLM-generated predictions on sentence acceptability are highly correlated with their normalised log probabilities in general. However, the correlations decrease when visual contexts are present, suggesting that a higher gap exists between the internal representations of LLMs and their generated predictions in the presence of visual contexts. Our experimental work suggests interesting points of similarity and of difference between human and LLM processing of sentences in multimodal contexts.
GPSBench: Do Large Language Models Understand GPS Coordinates?
Feb 18, 2026Large Language Models (LLMs) are increasingly deployed in applications that interact with the physical world, such as navigation, robotics, or mapping, making robust geospatial reasoning a critical capability. Despite that, LLMs' ability to reason about GPS coordinates and real-world geography remains underexplored. We introduce GPSBench, a dataset of 57,800 samples across 17 tasks for evaluating geospatial reasoning in LLMs, spanning geometric coordinate operations (e.g., distance and bearing computation) and reasoning that integrates coordinates with world knowledge. Focusing on intrinsic model capabilities rather than tool use, we evaluate 14 state-of-the-art LLMs and find that GPS reasoning remains challenging, with substantial variation across tasks: models are generally more reliable at real-world geographic reasoning than at geometric computations. Geographic knowledge degrades hierarchically, with strong country-level performance but weak city-level localization, while robustness to coordinate noise suggests genuine coordinate understanding rather than memorization. We further show that GPS-coordinate augmentation can improve in downstream geospatial tasks, and that finetuning induces trade-offs between gains in geometric computation and degradation in world knowledge. Our dataset and reproducible code are available at https://github.com/joey234/gpsbench
Context Volume Drives Performance: Tackling Domain Shift in Extremely Low-Resource Translation via RAG
Jan 15, 2026Neural Machine Translation (NMT) models for low-resource languages suffer significant performance degradation under domain shift. We quantify this challenge using Dhao, an indigenous language of Eastern Indonesia with no digital footprint beyond the New Testament (NT). When applied to the unseen Old Testament (OT), a standard NMT model fine-tuned on the NT drops from an in-domain score of 36.17 chrF++ to 27.11 chrF++. To recover this loss, we introduce a hybrid framework where a fine-tuned NMT model generates an initial draft, which is then refined by a Large Language Model (LLM) using Retrieval-Augmented Generation (RAG). The final system achieves 35.21 chrF++ (+8.10 recovery), effectively matching the original in-domain quality. Our analysis reveals that this performance is driven primarily by the number of retrieved examples rather than the choice of retrieval algorithm. Qualitative analysis confirms the LLM acts as a robust "safety net," repairing severe failures in zero-shot domains.
Investigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025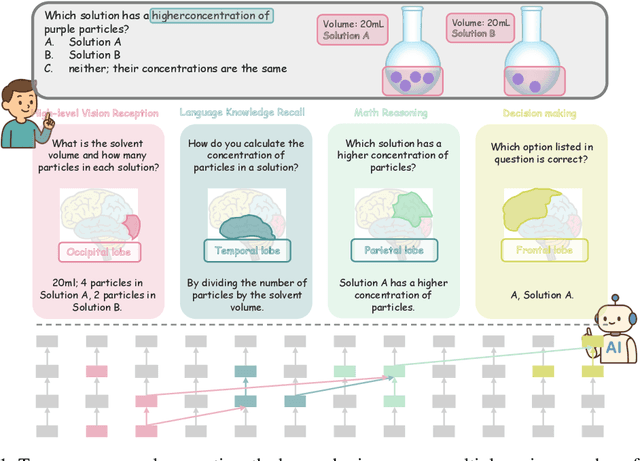
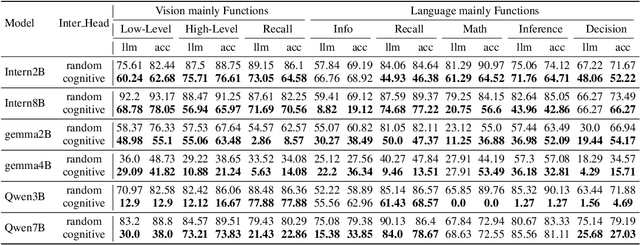
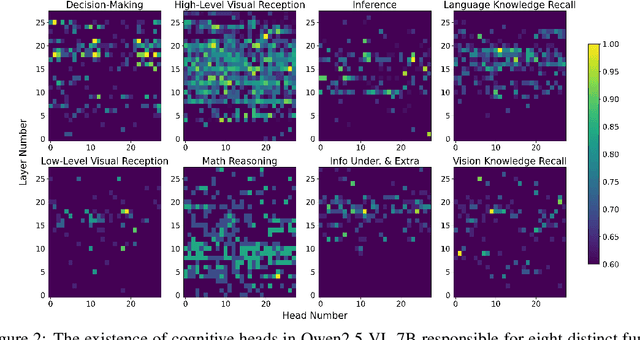

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
PROPA: Toward Process-level Optimization in Visual Reasoning via Reinforcement Learning
Nov 13, 2025Despite significant progress, Vision-Language Models (VLMs) still struggle with complex visual reasoning, where multi-step dependencies cause early errors to cascade through the reasoning chain. Existing post-training paradigms are limited: Supervised Fine-Tuning (SFT) relies on costly step-level annotations, while Reinforcement Learning with Verifiable Rewards (RLVR) methods like GRPO provide only sparse, outcome-level feedback, hindering stable optimization. We introduce PROPA (Process-level Reasoning Optimization with interleaved Policy Alignment), a novel framework that integrates Monte Carlo Tree Search (MCTS) with GRPO to generate dense, process-level rewards and optimize reasoning at each intermediate step without human annotations. To overcome the cold-start problem, PROPA interleaves GRPO updates with SFT, enabling the model to learn from both successful and failed reasoning trajectories. A Process Reward Model (PRM) is further trained to guide inference-time search, aligning the test-time search with the training signal. Across seven benchmarks and four VLM backbones, PROPA consistently outperforms both SFT- and RLVR-based baselines. It achieves up to 17.0% gains on in-domain tasks and 21.0% gains on out-of-domain tasks compared to existing state-of-the-art, establishing a strong reasoning and generalization capability for visual reasoning tasks. The code isavailable at: https://github.com/YanbeiJiang/PROPA.
Understanding the Geospatial Reasoning Capabilities of LLMs: A Trajectory Recovery Perspective
Oct 02, 2025We explore the geospatial reasoning capabilities of Large Language Models (LLMs), specifically, whether LLMs can read road network maps and perform navigation. We frame trajectory recovery as a proxy task, which requires models to reconstruct masked GPS traces, and introduce GLOBALTRACE, a dataset with over 4,000 real-world trajectories across diverse regions and transportation modes. Using road network as context, our prompting framework enables LLMs to generate valid paths without accessing any external navigation tools. Experiments show that LLMs outperform off-the-shelf baselines and specialized trajectory recovery models, with strong zero-shot generalization. Fine-grained analysis shows that LLMs have strong comprehension of the road network and coordinate systems, but also pose systematic biases with respect to regions and transportation modes. Finally, we demonstrate how LLMs can enhance navigation experiences by reasoning over maps in flexible ways to incorporate user preferences.
Beyond Perception: Evaluating Abstract Visual Reasoning through Multi-Stage Task
May 28, 2025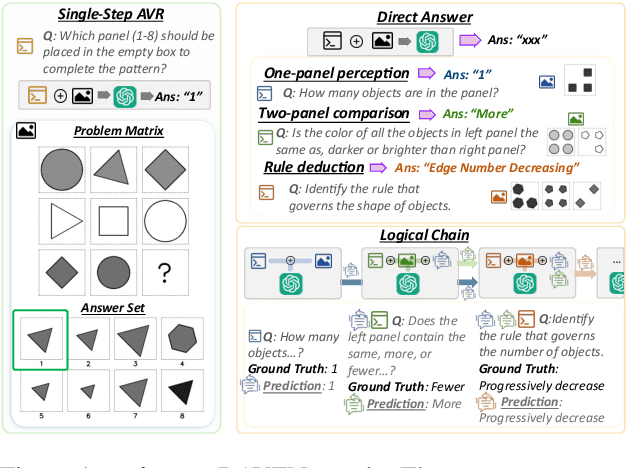
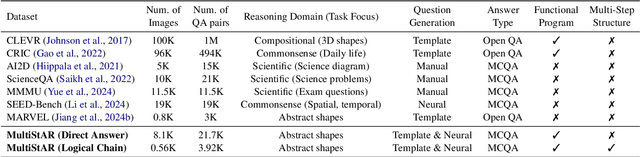
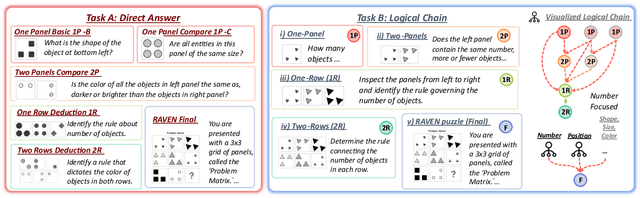
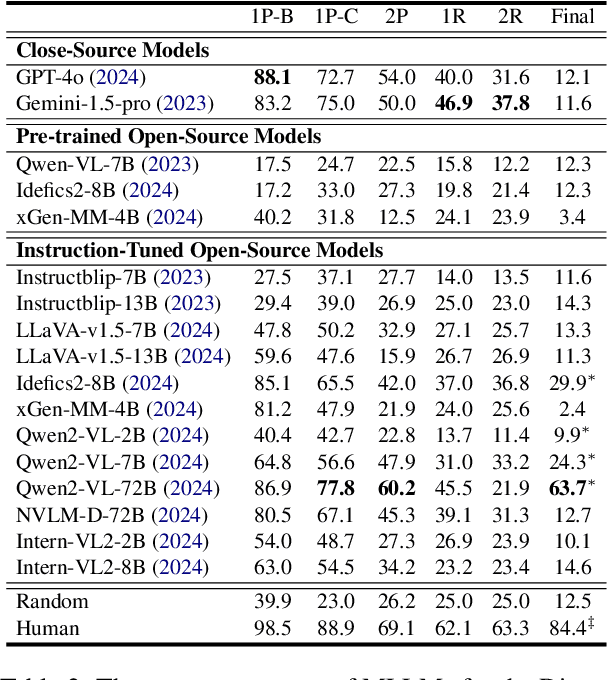
Current Multimodal Large Language Models (MLLMs) excel in general visual reasoning but remain underexplored in Abstract Visual Reasoning (AVR), which demands higher-order reasoning to identify abstract rules beyond simple perception. Existing AVR benchmarks focus on single-step reasoning, emphasizing the end result but neglecting the multi-stage nature of reasoning process. Past studies found MLLMs struggle with these benchmarks, but it doesn't explain how they fail. To address this gap, we introduce MultiStAR, a Multi-Stage AVR benchmark, based on RAVEN, designed to assess reasoning across varying levels of complexity. Additionally, existing metrics like accuracy only focus on the final outcomes while do not account for the correctness of intermediate steps. Therefore, we propose a novel metric, MSEval, which considers the correctness of intermediate steps in addition to the final outcomes. We conduct comprehensive experiments on MultiStAR using 17 representative close-source and open-source MLLMs. The results reveal that while existing MLLMs perform adequately on basic perception tasks, they continue to face challenges in more complex rule detection stages.
FLUKE: A Linguistically-Driven and Task-Agnostic Framework for Robustness Evaluation
Apr 24, 2025



We present FLUKE (Framework for LingUistically-driven and tasK-agnostic robustness Evaluation), a task-agnostic framework for assessing model robustness through systematic minimal variations of test data. FLUKE introduces controlled variations across linguistic levels - from orthography to dialect and style varieties - and leverages large language models (LLMs) with human validation to generate modifications. We demonstrate FLUKE's utility by evaluating both fine-tuned models and LLMs across four diverse NLP tasks, and reveal that (1) the impact of linguistic variations is highly task-dependent, with some tests being critical for certain tasks but irrelevant for others; (2) while LLMs have better overall robustness compared to fine-tuned models, they still exhibit significant brittleness to certain linguistic variations; (3) all models show substantial vulnerability to negation modifications across most tasks. These findings highlight the importance of systematic robustness testing for understanding model behaviors.