 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025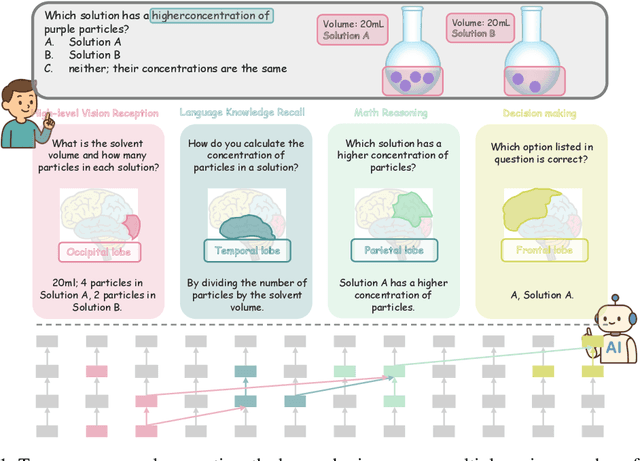
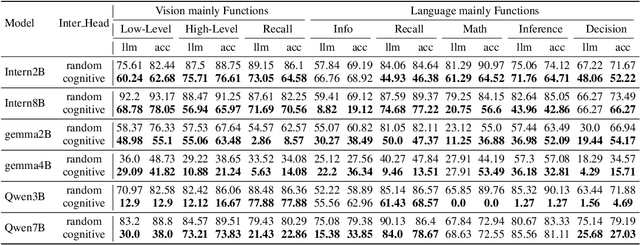
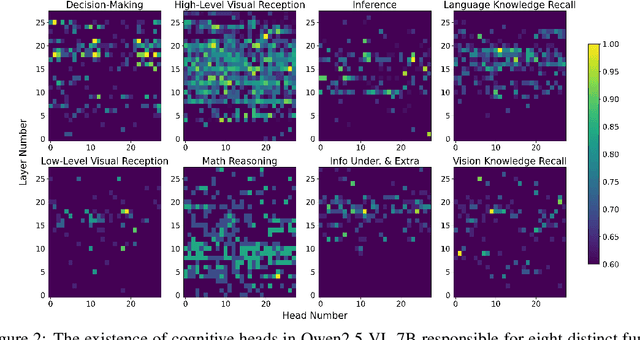

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
Beyond Perception: Evaluating Abstract Visual Reasoning through Multi-Stage Task
May 28, 2025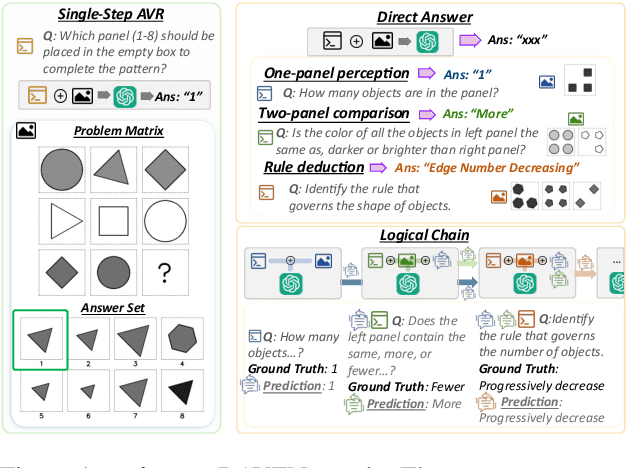
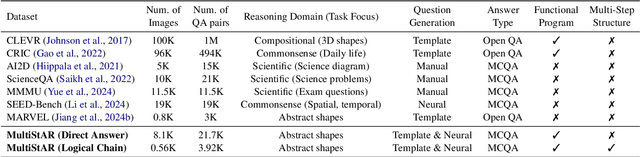
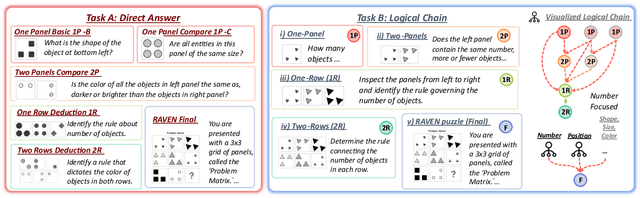
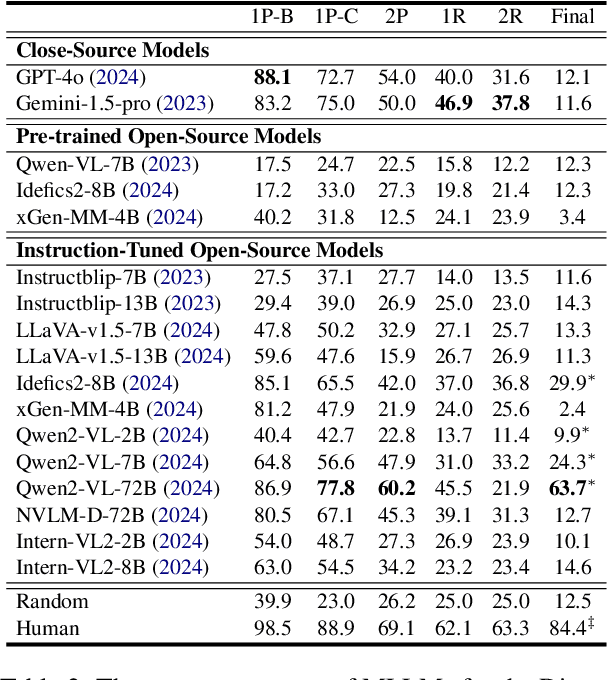
Current Multimodal Large Language Models (MLLMs) excel in general visual reasoning but remain underexplored in Abstract Visual Reasoning (AVR), which demands higher-order reasoning to identify abstract rules beyond simple perception. Existing AVR benchmarks focus on single-step reasoning, emphasizing the end result but neglecting the multi-stage nature of reasoning process. Past studies found MLLMs struggle with these benchmarks, but it doesn't explain how they fail. To address this gap, we introduce MultiStAR, a Multi-Stage AVR benchmark, based on RAVEN, designed to assess reasoning across varying levels of complexity. Additionally, existing metrics like accuracy only focus on the final outcomes while do not account for the correctness of intermediate steps. Therefore, we propose a novel metric, MSEval, which considers the correctness of intermediate steps in addition to the final outcomes. We conduct comprehensive experiments on MultiStAR using 17 representative close-source and open-source MLLMs. The results reveal that while existing MLLMs perform adequately on basic perception tasks, they continue to face challenges in more complex rule detection stages.
From Reasoning to Generalization: Knowledge-Augmented LLMs for ARC Benchmark
May 23, 2025Recent reasoning-oriented LLMs have demonstrated strong performance on challenging tasks such as mathematics and science examinations. However, core cognitive faculties of human intelligence, such as abstract reasoning and generalization, remain underexplored. To address this, we evaluate recent reasoning-oriented LLMs on the Abstraction and Reasoning Corpus (ARC) benchmark, which explicitly demands both faculties. We formulate ARC as a program synthesis task and propose nine candidate solvers. Experimental results show that repeated-sampling planning-aided code generation (RSPC) achieves the highest test accuracy and demonstrates consistent generalization across most LLMs. To further improve performance, we introduce an ARC solver, Knowledge Augmentation for Abstract Reasoning (KAAR), which encodes core knowledge priors within an ontology that classifies priors into three hierarchical levels based on their dependencies. KAAR progressively expands LLM reasoning capacity by gradually augmenting priors at each level, and invokes RSPC to generate candidate solutions after each augmentation stage. This stage-wise reasoning reduces interference from irrelevant priors and improves LLM performance. Empirical results show that KAAR maintains strong generalization and consistently outperforms non-augmented RSPC across all evaluated LLMs, achieving around 5% absolute gains and up to 64.52% relative improvement. Despite these achievements, ARC remains a challenging benchmark for reasoning-oriented LLMs, highlighting future avenues of progress in LLMs.
State-Based Disassembly Planning
Jan 09, 2025



It has been shown recently that physics-based simulation significantly enhances the disassembly capabilities of real-world assemblies with diverse 3D shapes and stringent motion constraints. However, the efficiency suffers when tackling intricate disassembly tasks that require numerous simulations and increased simulation time. In this work, we propose a State-Based Disassembly Planning (SBDP) approach, prioritizing physics-based simulation with translational motion over rotational motion to facilitate autonomy, reducing dependency on human input, while storing intermediate motion states to improve search scalability. We introduce two novel evaluation functions derived from new Directional Blocking Graphs (DBGs) enriched with state information to scale up the search. Our experiments show that SBDP with new evaluation functions and DBGs constraints outperforms the state-of-the-art in disassembly planning in terms of success rate and computational efficiency over benchmark datasets consisting of thousands of physically valid industrial assemblies.
Planning-Driven Programming: A Large Language Model Programming Workflow
Nov 21, 2024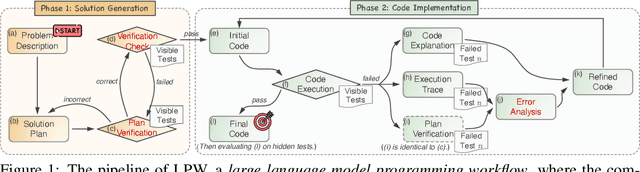
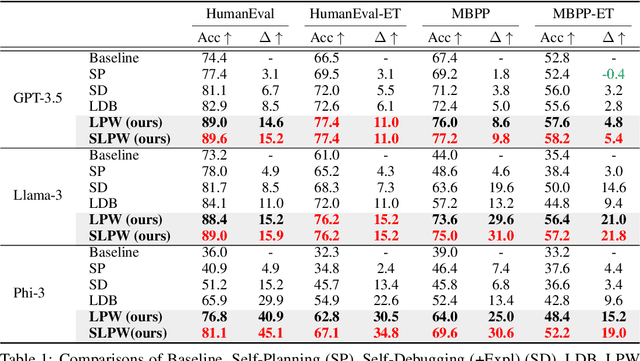


The strong performance of large language models (LLMs) on natural language processing tasks raises extensive discussion on their application to code generation. Recent work suggests multiple sampling approaches to improve initial code generation accuracy or program repair approaches to refine the code. However, these methods suffer from LLMs' inefficiencies and limited reasoning capacity. In this work, we propose an LLM programming workflow (LPW) designed to improve both initial code generation and subsequent refinements within a structured two-phase workflow. Specifically, in the solution generation phase, the LLM first outlines a solution plan that decomposes the problem into manageable sub-problems and then verifies the generated solution plan through visible test cases. Subsequently, in the code implementation phase, the LLM initially drafts a code according to the solution plan and its verification. If the generated code fails the visible tests, the plan verification serves as the intended natural language solution to inform the refinement process for correcting bugs. We further introduce SLPW, a sampling variant of LPW, which initially generates multiple solution plans and plan verifications, produces a program for each plan and its verification, and refines each program as necessary until one successfully passes the visible tests. Compared to the state-of-the-art methods across various existing LLMs, our experimental results show that LPW significantly improves the Pass@1 accuracy by up to 16.4% on well-established text-to-code generation benchmarks, especially with a notable improvement of around 10% on challenging benchmarks. Additionally, SLPW demonstrates up to a 5.6% improvement over LPW and sets new state-of-the-art Pass@1 accuracy on various benchmarks, e.g., 98.2% on HumanEval, 84.8% on MBPP, 64.0% on APPS, and 35.3% on CodeContest, using GPT-4o as the backbone.
Open-World Amodal Appearance Completion
Nov 20, 2024Understanding and reconstructing occluded objects is a challenging problem, especially in open-world scenarios where categories and contexts are diverse and unpredictable. Traditional methods, however, are typically restricted to closed sets of object categories, limiting their use in complex, open-world scenes. We introduce Open-World Amodal Appearance Completion, a training-free framework that expands amodal completion capabilities by accepting flexible text queries as input. Our approach generalizes to arbitrary objects specified by both direct terms and abstract queries. We term this capability reasoning amodal completion, where the system reconstructs the full appearance of the queried object based on the provided image and language query. Our framework unifies segmentation, occlusion analysis, and inpainting to handle complex occlusions and generates completed objects as RGBA elements, enabling seamless integration into applications such as 3D reconstruction and image editing. Extensive evaluations demonstrate the effectiveness of our approach in generalizing to novel objects and occlusions, establishing a new benchmark for amodal completion in open-world settings. The code and datasets will be released after paper acceptance.
KALE: An Artwork Image Captioning System Augmented with Heterogeneous Graph
Sep 17, 2024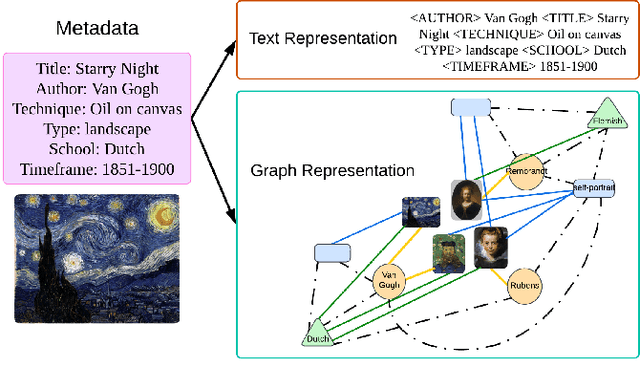
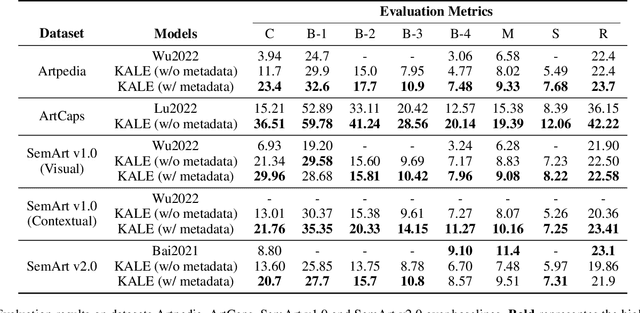
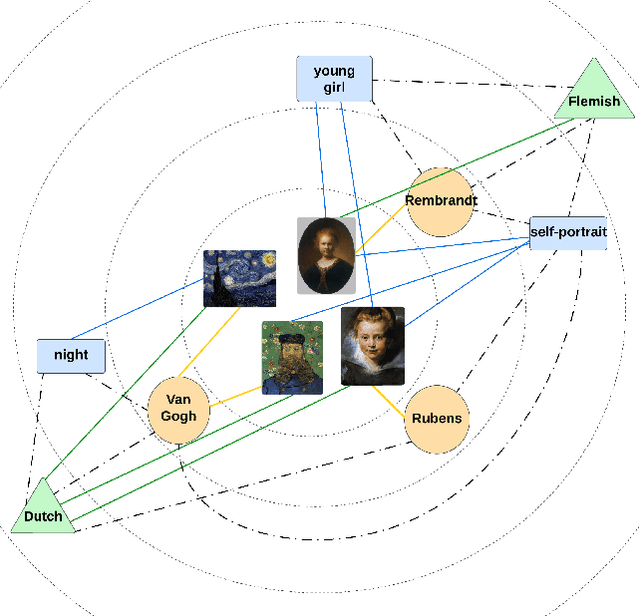
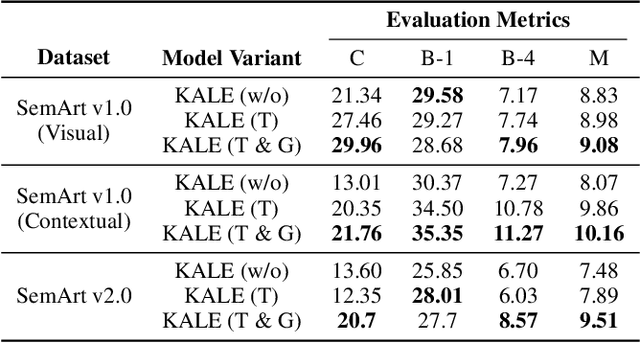
Exploring the narratives conveyed by fine-art paintings is a challenge in image captioning, where the goal is to generate descriptions that not only precisely represent the visual content but also offer a in-depth interpretation of the artwork's meaning. The task is particularly complex for artwork images due to their diverse interpretations and varied aesthetic principles across different artistic schools and styles. In response to this, we present KALE Knowledge-Augmented vision-Language model for artwork Elaborations), a novel approach that enhances existing vision-language models by integrating artwork metadata as additional knowledge. KALE incorporates the metadata in two ways: firstly as direct textual input, and secondly through a multimodal heterogeneous knowledge graph. To optimize the learning of graph representations, we introduce a new cross-modal alignment loss that maximizes the similarity between the image and its corresponding metadata. Experimental results demonstrate that KALE achieves strong performance (when evaluated with CIDEr, in particular) over existing state-of-the-art work across several artwork datasets. Source code of the project is available at https://github.com/Yanbei-Jiang/Artwork-Interpretation.
Sequential Amodal Segmentation via Cumulative Occlusion Learning
May 09, 2024
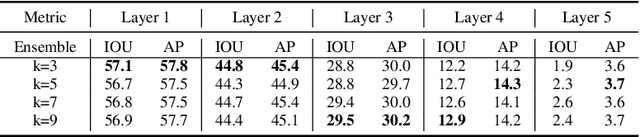
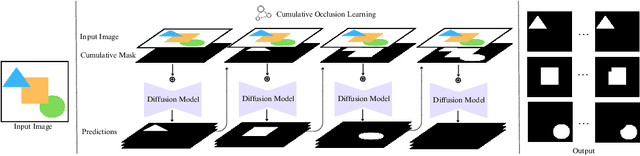

To fully understand the 3D context of a single image, a visual system must be able to segment both the visible and occluded regions of objects, while discerning their occlusion order. Ideally, the system should be able to handle any object and not be restricted to segmenting a limited set of object classes, especially in robotic applications. Addressing this need, we introduce a diffusion model with cumulative occlusion learning designed for sequential amodal segmentation of objects with uncertain categories. This model iteratively refines the prediction using the cumulative mask strategy during diffusion, effectively capturing the uncertainty of invisible regions and adeptly reproducing the complex distribution of shapes and occlusion orders of occluded objects. It is akin to the human capability for amodal perception, i.e., to decipher the spatial ordering among objects and accurately predict complete contours for occluded objects in densely layered visual scenes. Experimental results across three amodal datasets show that our method outperforms established baselines.
Perceiving Longer Sequences With Bi-Directional Cross-Attention Transformers
Feb 19, 2024
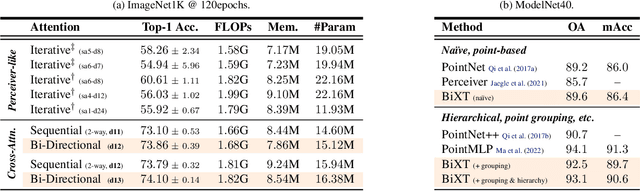
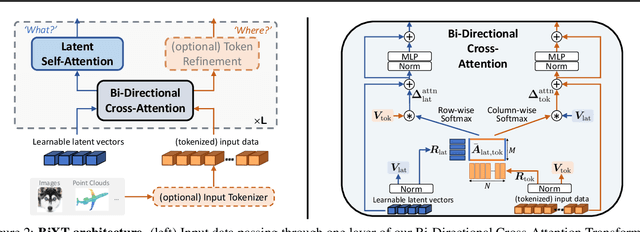
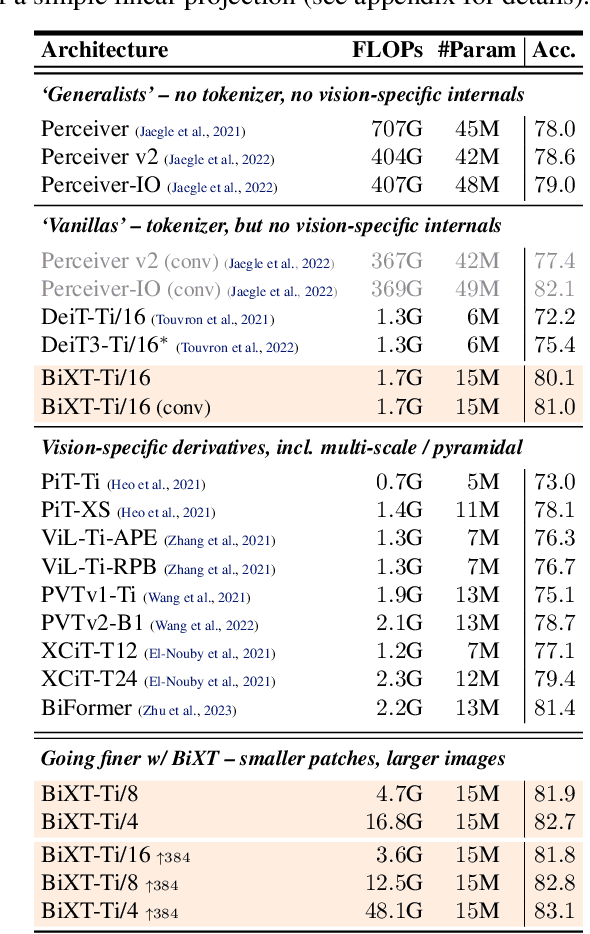
We present a novel bi-directional Transformer architecture (BiXT) which scales linearly with input size in terms of computational cost and memory consumption, but does not suffer the drop in performance or limitation to only one input modality seen with other efficient Transformer-based approaches. BiXT is inspired by the Perceiver architectures but replaces iterative attention with an efficient bi-directional cross-attention module in which input tokens and latent variables attend to each other simultaneously, leveraging a naturally emerging attention-symmetry between the two. This approach unlocks a key bottleneck experienced by Perceiver-like architectures and enables the processing and interpretation of both semantics (`what') and location (`where') to develop alongside each other over multiple layers -- allowing its direct application to dense and instance-based tasks alike. By combining efficiency with the generality and performance of a full Transformer architecture, BiXT can process longer sequences like point clouds or images at higher feature resolutions and achieves competitive performance across a range of tasks like point cloud part segmentation, semantic image segmentation and image classification.
Generalized Planning for the Abstraction and Reasoning Corpus
Jan 15, 2024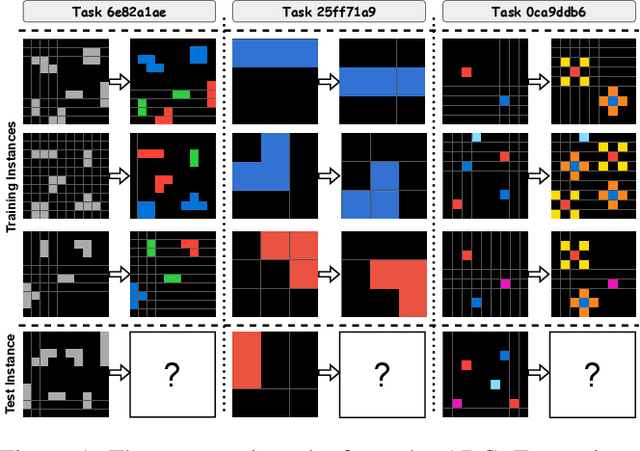
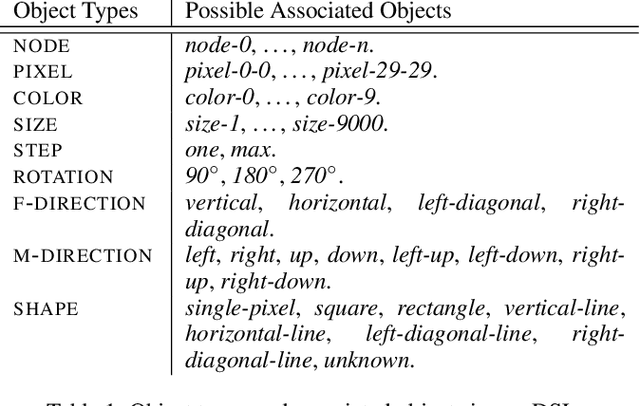

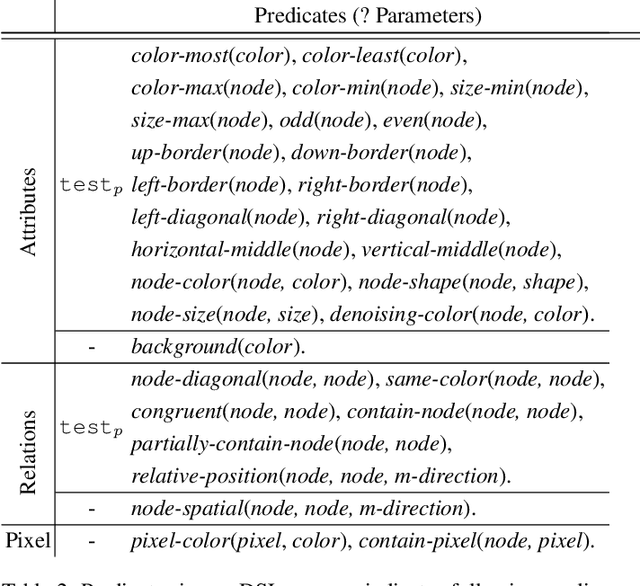
The Abstraction and Reasoning Corpus (ARC) is a general artificial intelligence benchmark that poses difficulties for pure machine learning methods due to its requirement for fluid intelligence with a focus on reasoning and abstraction. In this work, we introduce an ARC solver, Generalized Planning for Abstract Reasoning (GPAR). It casts an ARC problem as a generalized planning (GP) problem, where a solution is formalized as a planning program with pointers. We express each ARC problem using the standard Planning Domain Definition Language (PDDL) coupled with external functions representing object-centric abstractions. We show how to scale up GP solvers via domain knowledge specific to ARC in the form of restrictions over the actions model, predicates, arguments and valid structure of planning programs. Our experiments demonstrate that GPAR outperforms the state-of-the-art solvers on the object-centric tasks of the ARC, showing the effectiveness of GP and the expressiveness of PDDL to model ARC problems. The challenges provided by the ARC benchmark motivate research to advance existing GP solvers and understand new relations with other planning computational models. Code is available at github.com/you68681/GPAR.