 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneForge: Structured World Supervision from 3D Interventions
May 14, 2026Many multimodal learning tasks require supervision that remains consistent across edits, viewpoints, and scene-level interventions. However, such supervision is difficult to obtain from observation-level datasets, which do not expose the underlying scene state or how changes propagate through it. We present SceneForge, an intervention-driven framework that generates structured supervision from editable 3D world states. SceneForge represents each scene as a persistent world with semantic, geometric, and physical dependencies. By applying explicit interventions (e.g., object removal or camera variation) and propagating their effects through scene dependencies, SceneForge renders supervision that remains consistent with object structure and scene-level effects. This produces aligned outputs including counterfactual observations, multi-view observations, and effect-aware signals such as shadows and reflections, all derived from a shared world state rather than post hoc image-space processing. We instantiate SceneForge using Infinigen and Blender to construct a licensing-clean indoor supervision resource with a large number of counterfactual pairs and aligned annotations from over 2K scenes, covering both diverse single-view and registered multi-view settings. Under matched training budgets, incorporating SceneForge supervision improves both object removal and scene removal performance across multiple benchmarks in both quantitative and qualitative evaluation. These results indicate that modeling supervision as structured state transitions in editable worlds provides a practical and scalable foundation for intervention-consistent multimodal learning.
Neural Distribution Prior for LiDAR Out-of-Distribution Detection
Apr 10, 2026LiDAR-based perception is critical for autonomous driving due to its robustness to poor lighting and visibility conditions. Yet, current models operate under the closed-set assumption and often fail to recognize unexpected out-of-distribution (OOD) objects in the open world. Existing OOD scoring functions exhibit limited performance because they ignore the pronounced class imbalance inherent in LiDAR OOD detection and assume a uniform class distribution. To address this limitation, we propose the Neural Distribution Prior (NDP), a framework that models the distributional structure of network predictions and adaptively reweights OOD scores based on alignment with a learned distribution prior. NDP dynamically captures the logit distribution patterns of training data and corrects class-dependent confidence bias through an attention-based module. We further introduce a Perlin noise-based OOD synthesis strategy that generates diverse auxiliary OOD samples from input scans, enabling robust OOD training without external datasets. Extensive experiments on the SemanticKITTI and STU benchmarks demonstrate that NDP substantially improves OOD detection performance, achieving a point-level AP of 61.31\% on the STU test set, which is more than 10$\times$ higher than the previous best result. Our framework is compatible with various existing OOD scoring formulations, providing an effective solution for open-world LiDAR perception.
Attention in Space: Functional Roles of VLM Heads for Spatial Reasoning
Mar 21, 2026Despite remarkable advances in large Vision-Language Models (VLMs), spatial reasoning remains a persistent challenge. In this work, we investigate how attention heads within VLMs contribute to spatial reasoning by analyzing their functional roles through a mechanistic interpretability lens. We introduce CogVSR, a dataset that decomposes complex spatial reasoning questions into step-by-step subquestions designed to simulate human-like reasoning via a chain-of-thought paradigm, with each subquestion linked to specific cognitive functions such as spatial perception or relational reasoning. Building on CogVSR, we develop a probing framework to identify and characterize attention heads specialized for these functions. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions. Notably, spatially specialized heads are fewer than those for other cognitive functions, highlighting their scarcity. We propose methods to activate latent spatial heads, improving spatial understanding. Intervention experiments further demonstrate their critical role in spatial reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. This study provides new interpretability driven insights into how VLMs attend to space and paves the way for enhancing complex spatial reasoning in multimodal models.
Reasoning-Driven Amodal Completion: Collaborative Agents and Perceptual Evaluation
Dec 24, 2025

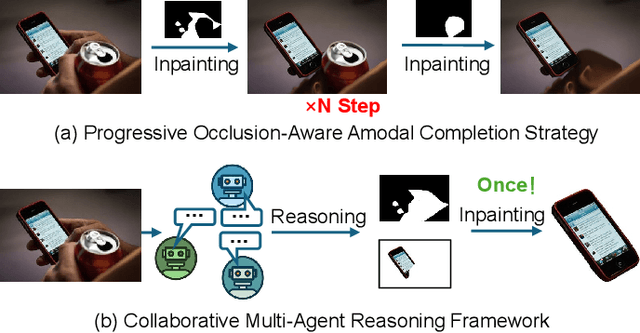

Amodal completion, the task of inferring invisible object parts, faces significant challenges in maintaining semantic consistency and structural integrity. Prior progressive approaches are inherently limited by inference instability and error accumulation. To tackle these limitations, we present a Collaborative Multi-Agent Reasoning Framework that explicitly decouples Semantic Planning from Visual Synthesis. By employing specialized agents for upfront reasoning, our method generates a structured, explicit plan before pixel generation, enabling visually and semantically coherent single-pass synthesis. We integrate this framework with two critical mechanisms: (1) a self-correcting Verification Agent that employs Chain-of-Thought reasoning to rectify visible region segmentation and identify residual occluders strictly within the Semantic Planning phase, and (2) a Diverse Hypothesis Generator that addresses the ambiguity of invisible regions by offering diverse, plausible semantic interpretations, surpassing the limited pixel-level variations of standard random seed sampling. Furthermore, addressing the limitations of traditional metrics in assessing inferred invisible content, we introduce the MAC-Score (MLLM Amodal Completion Score), a novel human-aligned evaluation metric. Validated against human judgment and ground truth, these metrics establish a robust standard for assessing structural completeness and semantic consistency with visible context. Extensive experiments demonstrate that our framework significantly outperforms state-of-the-art methods across multiple datasets. Our project is available at: https://fanhongxing.github.io/remac-page.
Relative Energy Learning for LiDAR Out-of-Distribution Detection
Nov 11, 2025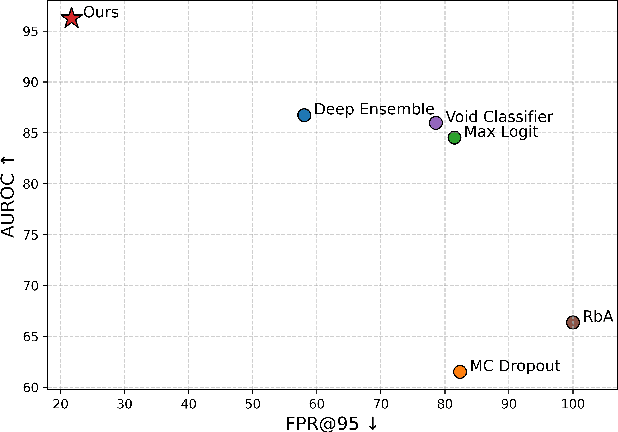
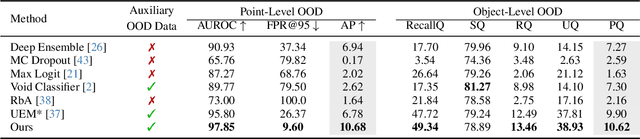
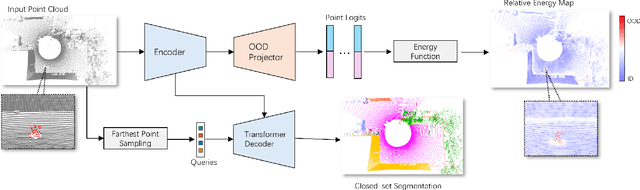

Out-of-distribution (OOD) detection is a critical requirement for reliable autonomous driving, where safety depends on recognizing road obstacles and unexpected objects beyond the training distribution. Despite extensive research on OOD detection in 2D images, direct transfer to 3D LiDAR point clouds has been proven ineffective. Current LiDAR OOD methods struggle to distinguish rare anomalies from common classes, leading to high false-positive rates and overconfident errors in safety-critical settings. We propose Relative Energy Learning (REL), a simple yet effective framework for OOD detection in LiDAR point clouds. REL leverages the energy gap between positive (in-distribution) and negative logits as a relative scoring function, mitigating calibration issues in raw energy values and improving robustness across various scenes. To address the absence of OOD samples during training, we propose a lightweight data synthesis strategy called Point Raise, which perturbs existing point clouds to generate auxiliary anomalies without altering the inlier semantics. Evaluated on SemanticKITTI and the Spotting the Unexpected (STU) benchmark, REL consistently outperforms existing methods by a large margin. Our results highlight that modeling relative energy, combined with simple synthetic outliers, provides a principled and scalable solution for reliable OOD detection in open-world autonomous driving.
Beyond Perception: Evaluating Abstract Visual Reasoning through Multi-Stage Task
May 28, 2025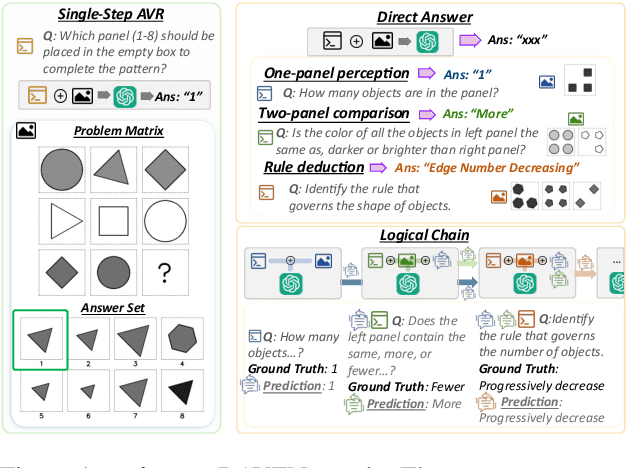
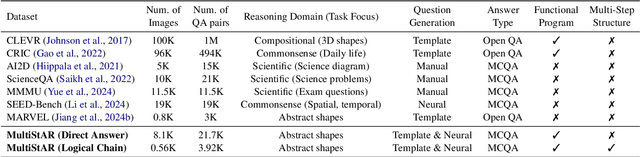
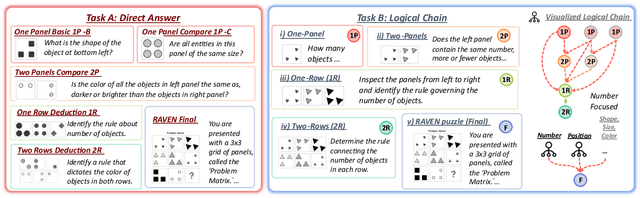
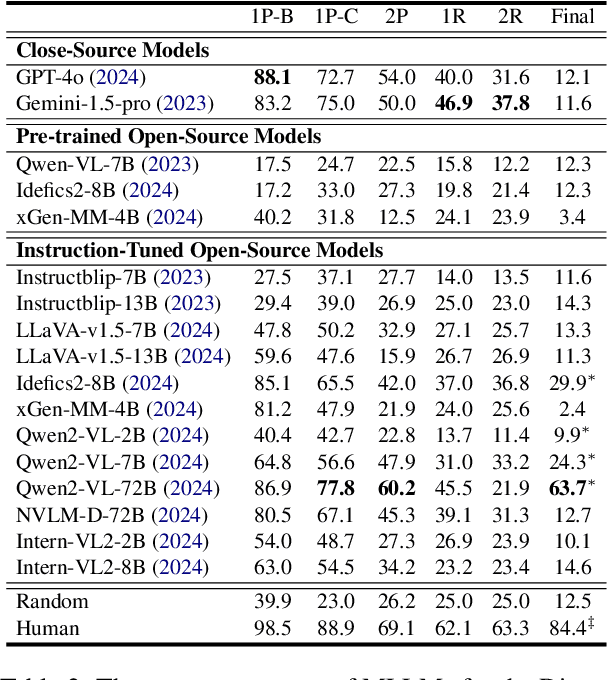
Current Multimodal Large Language Models (MLLMs) excel in general visual reasoning but remain underexplored in Abstract Visual Reasoning (AVR), which demands higher-order reasoning to identify abstract rules beyond simple perception. Existing AVR benchmarks focus on single-step reasoning, emphasizing the end result but neglecting the multi-stage nature of reasoning process. Past studies found MLLMs struggle with these benchmarks, but it doesn't explain how they fail. To address this gap, we introduce MultiStAR, a Multi-Stage AVR benchmark, based on RAVEN, designed to assess reasoning across varying levels of complexity. Additionally, existing metrics like accuracy only focus on the final outcomes while do not account for the correctness of intermediate steps. Therefore, we propose a novel metric, MSEval, which considers the correctness of intermediate steps in addition to the final outcomes. We conduct comprehensive experiments on MultiStAR using 17 representative close-source and open-source MLLMs. The results reveal that while existing MLLMs perform adequately on basic perception tasks, they continue to face challenges in more complex rule detection stages.
Open-World Amodal Appearance Completion
Nov 20, 2024Understanding and reconstructing occluded objects is a challenging problem, especially in open-world scenarios where categories and contexts are diverse and unpredictable. Traditional methods, however, are typically restricted to closed sets of object categories, limiting their use in complex, open-world scenes. We introduce Open-World Amodal Appearance Completion, a training-free framework that expands amodal completion capabilities by accepting flexible text queries as input. Our approach generalizes to arbitrary objects specified by both direct terms and abstract queries. We term this capability reasoning amodal completion, where the system reconstructs the full appearance of the queried object based on the provided image and language query. Our framework unifies segmentation, occlusion analysis, and inpainting to handle complex occlusions and generates completed objects as RGBA elements, enabling seamless integration into applications such as 3D reconstruction and image editing. Extensive evaluations demonstrate the effectiveness of our approach in generalizing to novel objects and occlusions, establishing a new benchmark for amodal completion in open-world settings. The code and datasets will be released after paper acceptance.
Sequential Amodal Segmentation via Cumulative Occlusion Learning
May 09, 2024
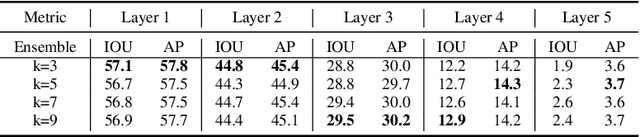
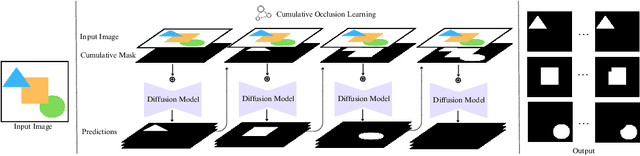

To fully understand the 3D context of a single image, a visual system must be able to segment both the visible and occluded regions of objects, while discerning their occlusion order. Ideally, the system should be able to handle any object and not be restricted to segmenting a limited set of object classes, especially in robotic applications. Addressing this need, we introduce a diffusion model with cumulative occlusion learning designed for sequential amodal segmentation of objects with uncertain categories. This model iteratively refines the prediction using the cumulative mask strategy during diffusion, effectively capturing the uncertainty of invisible regions and adeptly reproducing the complex distribution of shapes and occlusion orders of occluded objects. It is akin to the human capability for amodal perception, i.e., to decipher the spatial ordering among objects and accurately predict complete contours for occluded objects in densely layered visual scenes. Experimental results across three amodal datasets show that our method outperforms established baselines.
Amodal Intra-class Instance Segmentation: New Dataset and Benchmark
Mar 12, 2023



Images of realistic scenes often contain intra-class objects that are heavily occluded from each other, making the amodal perception task that requires parsing the occluded parts of the objects challenging. Although important for downstream tasks such as robotic grasping systems, the lack of large-scale amodal datasets with detailed annotations makes it difficult to model intra-class occlusions explicitly. This paper introduces a new amodal dataset for image amodal completion tasks, which contains over 255K images of intra-class occlusion scenarios, annotated with multiple masks, amodal bounding boxes, dual order relations and full appearance for instances and background. We also present a point-supervised scheme with layer priors for amodal instance segmentation specifically designed for intra-class occlusion scenarios. Experiments show that our weakly supervised approach outperforms the SOTA fully supervised methods, while our layer priors design exhibits remarkable performance improvements in the case of intra-class occlusion in both synthetic and real images.
Image Amodal Completion: A Survey
Jul 05, 2022



Existing computer vision systems can compete with humans in understanding the visible parts of objects, but still fall far short of humans when it comes to depicting the invisible parts of partially occluded objects. Image amodal completion aims to equip computers with human-like amodal completion functions to understand an intact object despite it being partially occluded. The main purpose of this survey is to provide an intuitive understanding of the research hotspots, key technologies and future trends in the field of image amodal completion. Firstly, we present a comprehensive review of the latest literature in this emerging field, exploring three key tasks in image amodal completion, including amodal shape completion, amodal appearance completion, and order perception. Then we examine popular datasets related to image amodal completion along with their common data collection methods and evaluation metrics. Finally, we discuss real-world applications and future research directions for image amodal completion, facilitating the reader's understanding of the challenges of existing technologies and upcoming research trends.