 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTIndex: A Context-Aware Multi-Dimensional Spatiotemporal Information Extraction System
Apr 07, 2026Extracting structured knowledge from unstructured data still faces practical limitations: entity and event extraction pipelines remain brittle, knowledge graph construction requires costly ontology engineering, and cross-domain generalization is rarely production-ready. In contrast, space and time provide universal contextual anchors that naturally align heterogeneous information and benefit downstream tasks such as retrieval and reasoning. We introduce \textbf{STIndex}, an end-to-end system that structures unstructured content into a multidimensional spatiotemporal data warehouse. Users define domain-specific analysis dimensions with configurable hierarchies, while large language models perform context-aware extraction and grounding. \textbf{STIndex} integrates document-level memory, geocoding correction, and quality validation, and offers an interactive analytics dashboard for visualization, clustering, burst detection, and entity network analysis. In evaluation on a public health benchmark, \textbf{STIndex} improves spatiotemporal entity extraction F1 by 4.37\% (GPT-4o-mini) and 3.60\% (Qwen3-8B). A live demonstration and open-source code are available at https://stindex.ai4wa.com/dashboard.
ToolTree: Efficient LLM Agent Tool Planning via Dual-Feedback Monte Carlo Tree Search and Bidirectional Pruning
Mar 13, 2026Large Language Model (LLM) agents are increasingly applied to complex, multi-step tasks that require interaction with diverse external tools across various domains. However, current LLM agent tool planning methods typically rely on greedy, reactive tool selection strategies that lack foresight and fail to account for inter-tool dependencies. In this paper, we present ToolTree, a novel Monte Carlo tree search-inspired planning paradigm for tool planning. ToolTree explores possible tool usage trajectories using a dual-stage LLM evaluation and bidirectional pruning mechanism that enables the agent to make informed, adaptive decisions over extended tool-use sequences while pruning less promising branches before and after the tool execution. Empirical evaluations across both open-set and closed-set tool planning tasks on 4 benchmarks demonstrate that ToolTree consistently improves performance while keeping the highest efficiency, achieving an average gain of around 10\% compared to the state-of-the-art planning paradigm.
GeoChemAD: Benchmarking Unsupervised Geochemical Anomaly Detection for Mineral Exploration
Mar 13, 2026Geochemical anomaly detection plays a critical role in mineral exploration as deviations from regional geochemical baselines may indicate mineralization. Existing studies suffer from two key limitations: (1) single region scenarios which limit model generalizability; (2) proprietary datasets, which makes result reproduction unattainable. In this work, we introduce \textbf{GeoChemAD}, an open-source benchmark dataset compiled from government-led geological surveys, covering multiple regions, sampling sources, and target elements. The dataset comprises eight subsets representing diverse spatial scales and sampling conditions. To establish strong baselines, we reproduce and benchmark a range of unsupervised anomaly detection methods, including statistical models, generative and transformer-based approaches. Furthermore, we propose \textbf{GeoChemFormer}, a transformer-based framework that leverages self-supervised pretraining to learn target-element-aware geochemical representations for spatial samples. Extensive experiments demonstrate that GeoChemFormer consistently achieves superior and robust performance across all eight subsets, outperforming existing unsupervised methods in both anomaly detection accuracy and generalization capability. The proposed dataset and framework provide a foundation for reproducible research and future development in this direction.
BRIDGE: Benchmark for multi-hop Reasoning In long multimodal Documents with Grounded Evidence
Mar 09, 2026Multi-hop question answering (QA) is widely used to evaluate the reasoning capabilities of large language models, yet most benchmarks focus on final answer correctness and overlook intermediate reasoning, especially in long multimodal documents. We introduce BRIDGE, a benchmark for multi-hop reasoning over long scientific papers that require integrating evidence across text, tables, and figures. The dataset supports both chain-like and fan-out structures and provides explicit multi-hop reasoning annotations for step-level evaluation beyond answer accuracy. Experiments with state-of-the-art LLMs and multimodal retrieval-augmented generation (RAG) systems reveal systematic deficiencies in evidence aggregation and grounding that remain hidden under conventional answer-only evaluation. BRIDGE provides a targeted testbed for diagnosing reasoning failures in long multimodal documents.
Diagnosing Causal Reasoning in Vision-Language Models via Structured Relevance Graphs
Feb 24, 2026Large Vision-Language Models (LVLMs) achieve strong performance on visual question answering benchmarks, yet often rely on spurious correlations rather than genuine causal reasoning. Existing evaluations primarily assess the correctness of the answers, making it unclear whether failures arise from limited reasoning capability or from misidentifying causally relevant information. We introduce Vision-Language Causal Graphs (VLCGs), a structured, query-conditioned representation that explicitly encodes causally relevant objects, attributes, relations, and scene-grounded assumptions. Building on this representation, we present ViLCaR, a diagnostic benchmark comprising tasks for Causal Attribution, Causal Inference, and Question Answering, along with graph-aligned evaluation metrics that assess relevance identification beyond final answer accuracy. Experiments in state-of-the-art LVLMs show that injecting structured relevance information significantly improves attribution and inference consistency compared to zero-shot and standard in-context learning. These findings suggest that current limitations in LVLM causal reasoning stem primarily from insufficient structural guidance rather than a lack of reasoning capacity.
Docs2Synth: A Synthetic Data Trained Retriever Framework for Scanned Visually Rich Documents Understanding
Jan 18, 2026Document understanding (VRDU) in regulated domains is particularly challenging, since scanned documents often contain sensitive, evolving, and domain specific knowledge. This leads to two major challenges: the lack of manual annotations for model adaptation and the difficulty for pretrained models to stay up-to-date with domain-specific facts. While Multimodal Large Language Models (MLLMs) show strong zero-shot abilities, they still suffer from hallucination and limited domain grounding. In contrast, discriminative Vision-Language Pre-trained Models (VLPMs) provide reliable grounding but require costly annotations to cover new domains. We introduce Docs2Synth, a synthetic-supervision framework that enables retrieval-guided inference for private and low-resource domains. Docs2Synth automatically processes raw document collections, generates and verifies diverse QA pairs via an agent-based system, and trains a lightweight visual retriever to extract domain-relevant evidence. During inference, the retriever collaborates with an MLLM through an iterative retrieval--generation loop, reducing hallucination and improving response consistency. We further deliver Docs2Synth as an easy-to-use Python package, enabling plug-and-play deployment across diverse real-world scenarios. Experiments on multiple VRDU benchmarks show that Docs2Synth substantially enhances grounding and domain generalization without requiring human annotations.
A Disease-Aware Dual-Stage Framework for Chest X-ray Report Generation
Nov 15, 2025Radiology report generation from chest X-rays is an important task in artificial intelligence with the potential to greatly reduce radiologists' workload and shorten patient wait times. Despite recent advances, existing approaches often lack sufficient disease-awareness in visual representations and adequate vision-language alignment to meet the specialized requirements of medical image analysis. As a result, these models usually overlook critical pathological features on chest X-rays and struggle to generate clinically accurate reports. To address these limitations, we propose a novel dual-stage disease-aware framework for chest X-ray report generation. In Stage~1, our model learns Disease-Aware Semantic Tokens (DASTs) corresponding to specific pathology categories through cross-attention mechanisms and multi-label classification, while simultaneously aligning vision and language representations via contrastive learning. In Stage~2, we introduce a Disease-Visual Attention Fusion (DVAF) module to integrate disease-aware representations with visual features, along with a Dual-Modal Similarity Retrieval (DMSR) mechanism that combines visual and disease-specific similarities to retrieve relevant exemplars, providing contextual guidance during report generation. Extensive experiments on benchmark datasets (i.e., CheXpert Plus, IU X-ray, and MIMIC-CXR) demonstrate that our disease-aware framework achieves state-of-the-art performance in chest X-ray report generation, with significant improvements in clinical accuracy and linguistic quality.
PROPA: Toward Process-level Optimization in Visual Reasoning via Reinforcement Learning
Nov 13, 2025Despite significant progress, Vision-Language Models (VLMs) still struggle with complex visual reasoning, where multi-step dependencies cause early errors to cascade through the reasoning chain. Existing post-training paradigms are limited: Supervised Fine-Tuning (SFT) relies on costly step-level annotations, while Reinforcement Learning with Verifiable Rewards (RLVR) methods like GRPO provide only sparse, outcome-level feedback, hindering stable optimization. We introduce PROPA (Process-level Reasoning Optimization with interleaved Policy Alignment), a novel framework that integrates Monte Carlo Tree Search (MCTS) with GRPO to generate dense, process-level rewards and optimize reasoning at each intermediate step without human annotations. To overcome the cold-start problem, PROPA interleaves GRPO updates with SFT, enabling the model to learn from both successful and failed reasoning trajectories. A Process Reward Model (PRM) is further trained to guide inference-time search, aligning the test-time search with the training signal. Across seven benchmarks and four VLM backbones, PROPA consistently outperforms both SFT- and RLVR-based baselines. It achieves up to 17.0% gains on in-domain tasks and 21.0% gains on out-of-domain tasks compared to existing state-of-the-art, establishing a strong reasoning and generalization capability for visual reasoning tasks. The code isavailable at: https://github.com/YanbeiJiang/PROPA.
Natural Language Processing in Support of Evidence-based Medicine: A Scoping Review
May 28, 2025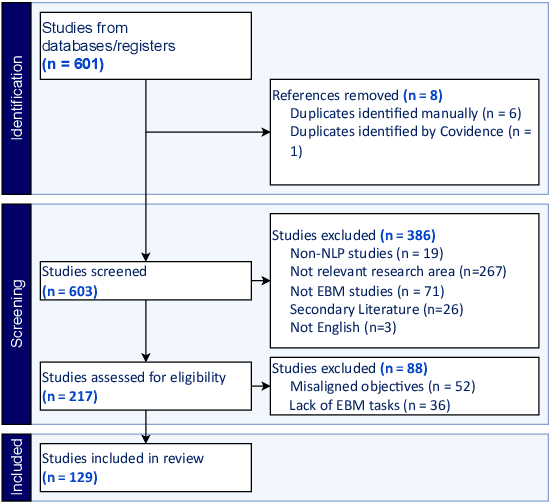
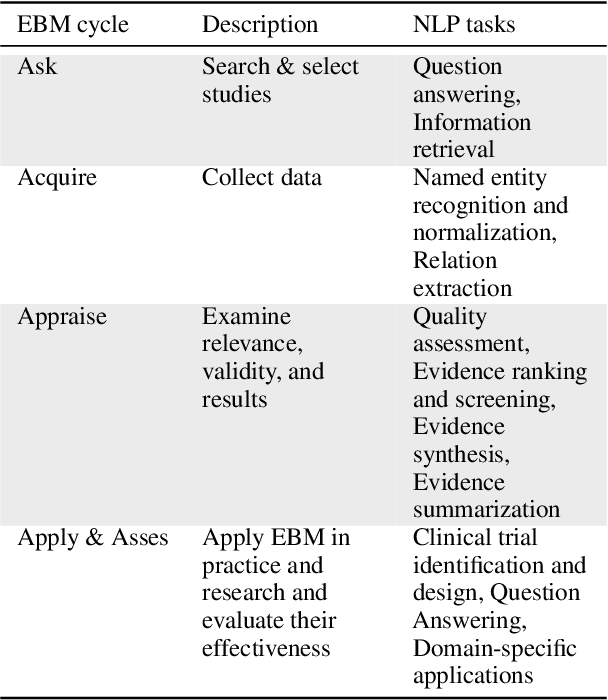
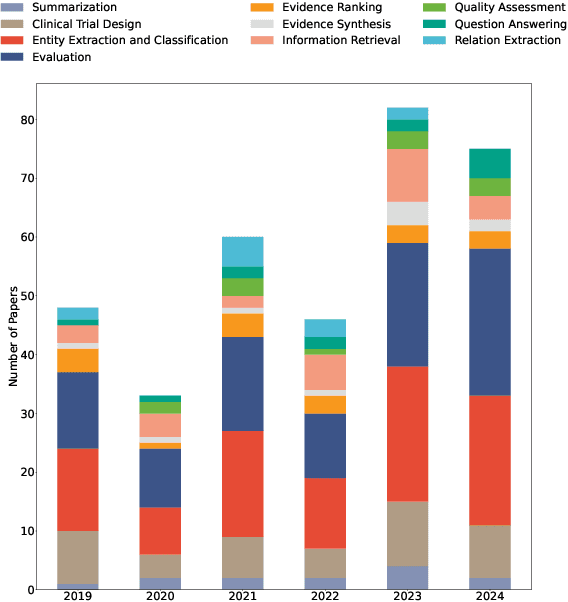
Evidence-based medicine (EBM) is at the forefront of modern healthcare, emphasizing the use of the best available scientific evidence to guide clinical decisions. Due to the sheer volume and rapid growth of medical literature and the high cost of curation, there is a critical need to investigate Natural Language Processing (NLP) methods to identify, appraise, synthesize, summarize, and disseminate evidence in EBM. This survey presents an in-depth review of 129 research studies on leveraging NLP for EBM, illustrating its pivotal role in enhancing clinical decision-making processes. The paper systematically explores how NLP supports the five fundamental steps of EBM -- Ask, Acquire, Appraise, Apply, and Assess. The review not only identifies current limitations within the field but also proposes directions for future research, emphasizing the potential for NLP to revolutionize EBM by refining evidence extraction, evidence synthesis, appraisal, summarization, enhancing data comprehensibility, and facilitating a more efficient clinical workflow.
Beyond Perception: Evaluating Abstract Visual Reasoning through Multi-Stage Task
May 28, 2025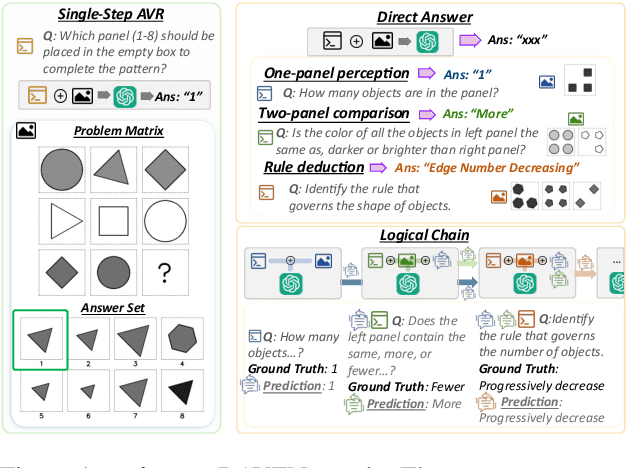
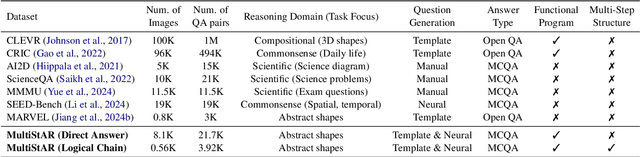
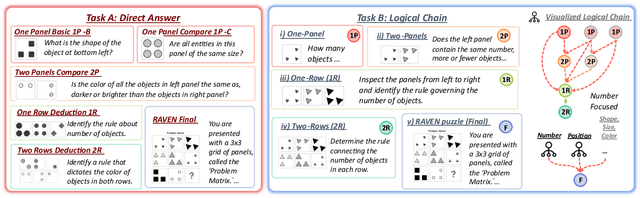
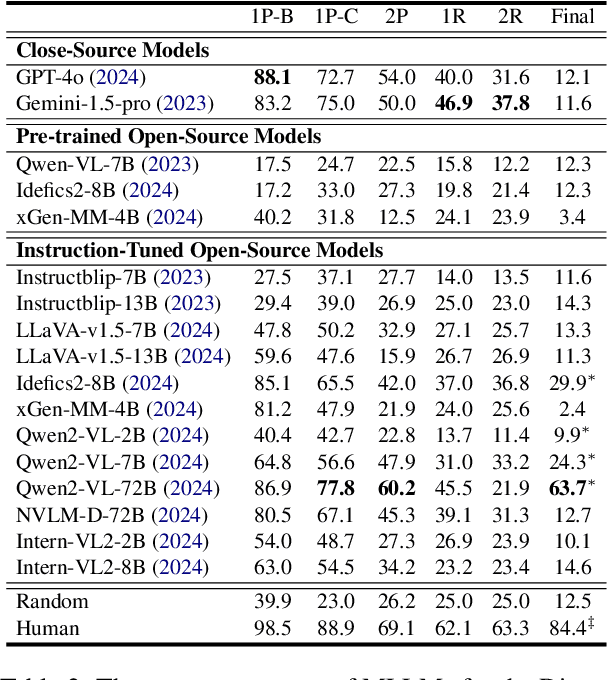
Current Multimodal Large Language Models (MLLMs) excel in general visual reasoning but remain underexplored in Abstract Visual Reasoning (AVR), which demands higher-order reasoning to identify abstract rules beyond simple perception. Existing AVR benchmarks focus on single-step reasoning, emphasizing the end result but neglecting the multi-stage nature of reasoning process. Past studies found MLLMs struggle with these benchmarks, but it doesn't explain how they fail. To address this gap, we introduce MultiStAR, a Multi-Stage AVR benchmark, based on RAVEN, designed to assess reasoning across varying levels of complexity. Additionally, existing metrics like accuracy only focus on the final outcomes while do not account for the correctness of intermediate steps. Therefore, we propose a novel metric, MSEval, which considers the correctness of intermediate steps in addition to the final outcomes. We conduct comprehensive experiments on MultiStAR using 17 representative close-source and open-source MLLMs. The results reveal that while existing MLLMs perform adequately on basic perception tasks, they continue to face challenges in more complex rule detection stages.