 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLosses that Cook: Topological Optimal Transport for Structured Recipe Generation
Jan 05, 2026Cooking recipes are complex procedures that require not only a fluent and factual text, but also accurate timing, temperature, and procedural coherence, as well as the correct composition of ingredients. Standard training procedures are primarily based on cross-entropy and focus solely on fluency. Building on RECIPE-NLG, we investigate the use of several composite objectives and present a new topological loss that represents ingredient lists as point clouds in embedding space, minimizing the divergence between predicted and gold ingredients. Using both standard NLG metrics and recipe-specific metrics, we find that our loss significantly improves ingredient- and action-level metrics. Meanwhile, the Dice loss excels in time/temperature precision, and the mixed loss yields competitive trade-offs with synergistic gains in quantity and time. A human preference analysis supports our finding, showing our model is preferred in 62% of the cases.
HydroChronos: Forecasting Decades of Surface Water Change
Jun 17, 2025Forecasting surface water dynamics is crucial for water resource management and climate change adaptation. However, the field lacks comprehensive datasets and standardized benchmarks. In this paper, we introduce HydroChronos, a large-scale, multi-modal spatiotemporal dataset for surface water dynamics forecasting designed to address this gap. We couple the dataset with three forecasting tasks. The dataset includes over three decades of aligned Landsat 5 and Sentinel-2 imagery, climate data, and Digital Elevation Models for diverse lakes and rivers across Europe, North America, and South America. We also propose AquaClimaTempo UNet, a novel spatiotemporal architecture with a dedicated climate data branch, as a strong benchmark baseline. Our model significantly outperforms a Persistence baseline for forecasting future water dynamics by +14% and +11% F1 across change detection and direction of change classification tasks, and by +0.1 MAE on the magnitude of change regression. Finally, we conduct an Explainable AI analysis to identify the key climate variables and input channels that influence surface water change, providing insights to inform and guide future modeling efforts.
Magnifier: A Multi-grained Neural Network-based Architecture for Burned Area Delineation
Apr 28, 2025In crisis management and remote sensing, image segmentation plays a crucial role, enabling tasks like disaster response and emergency planning by analyzing visual data. Neural networks are able to analyze satellite acquisitions and determine which areas were affected by a catastrophic event. The problem in their development in this context is the data scarcity and the lack of extensive benchmark datasets, limiting the capabilities of training large neural network models. In this paper, we propose a novel methodology, namely Magnifier, to improve segmentation performance with limited data availability. The Magnifier methodology is applicable to any existing encoder-decoder architecture, as it extends a model by merging information at different contextual levels through a dual-encoder approach: a local and global encoder. Magnifier analyzes the input data twice using the dual-encoder approach. In particular, the local and global encoders extract information from the same input at different granularities. This allows Magnifier to extract more information than the other approaches given the same set of input images. Magnifier improves the quality of the results of +2.65% on average IoU while leading to a restrained increase in terms of the number of trainable parameters compared to the original model. We evaluated our proposed approach with state-of-the-art burned area segmentation models, demonstrating, on average, comparable or better performances in less than half of the GFLOPs.
Turin3D: Evaluating Adaptation Strategies under Label Scarcity in Urban LiDAR Segmentation with Semi-Supervised Techniques
Apr 08, 20253D semantic segmentation plays a critical role in urban modelling, enabling detailed understanding and mapping of city environments. In this paper, we introduce Turin3D: a new aerial LiDAR dataset for point cloud semantic segmentation covering an area of around 1.43 km2 in the city centre of Turin with almost 70M points. We describe the data collection process and compare Turin3D with others previously proposed in the literature. We did not fully annotate the dataset due to the complexity and time-consuming nature of the process; however, a manual annotation process was performed on the validation and test sets, to enable a reliable evaluation of the proposed techniques. We first benchmark the performances of several point cloud semantic segmentation models, trained on the existing datasets, when tested on Turin3D, and then improve their performances by applying a semi-supervised learning technique leveraging the unlabelled training set. The dataset will be publicly available to support research in outdoor point cloud segmentation, with particular relevance for self-supervised and semi-supervised learning approaches given the absence of ground truth annotations for the training set.
Modelling Concurrent RTP Flows for End-to-end Predictions of QoS in Real Time Communications
Oct 21, 2024

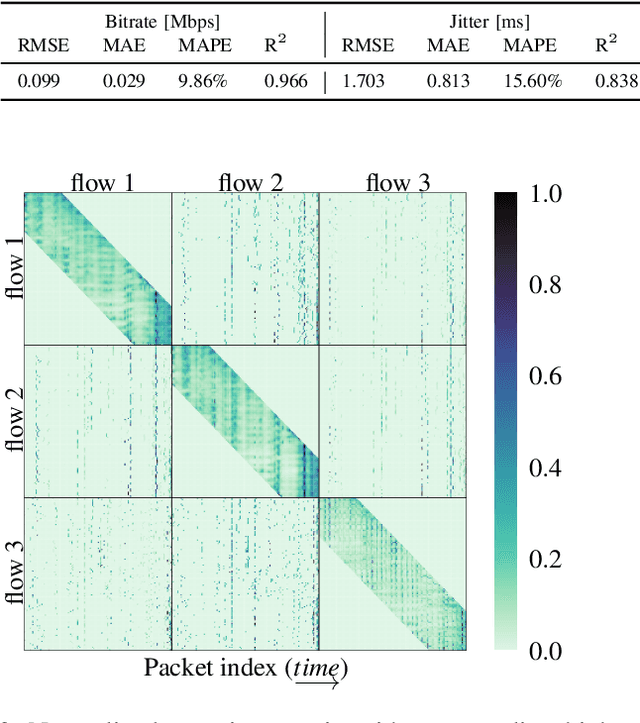

The Real-time Transport Protocol (RTP)-based real-time communications (RTC) applications, exemplified by video conferencing, have experienced an unparalleled surge in popularity and development in recent years. In pursuit of optimizing their performance, the prediction of Quality of Service (QoS) metrics emerges as a pivotal endeavor, bolstering network monitoring and proactive solutions. However, contemporary approaches are confined to individual RTP flows and metrics, falling short in relationship capture and computational efficiency. To this end, we propose Packet-to-Prediction (P2P), a novel deep learning (DL) framework that hinges on raw packets to simultaneously process concurrent RTP flows and perform end-to-end prediction of multiple QoS metrics. Specifically, we implement a streamlined architecture, namely length-free Transformer with cross and neighbourhood attention, capable of handling an unlimited number of RTP flows, and employ a multi-task learning paradigm to forecast four key metrics in a single shot. Our work is based on extensive traffic collected during real video calls, and conclusively, P2P excels comparative models in both prediction performance and temporal efficiency.
Level Up Your Tutorials: VLMs for Game Tutorials Quality Assessment
Aug 15, 2024



Designing effective game tutorials is crucial for a smooth learning curve for new players, especially in games with many rules and complex core mechanics. Evaluating the effectiveness of these tutorials usually requires multiple iterations with testers who have no prior knowledge of the game. Recent Vision-Language Models (VLMs) have demonstrated significant capabilities in understanding and interpreting visual content. VLMs can analyze images, provide detailed insights, and answer questions about their content. They can recognize objects, actions, and contexts in visual data, making them valuable tools for various applications, including automated game testing. In this work, we propose an automated game-testing solution to evaluate the quality of game tutorials. Our approach leverages VLMs to analyze frames from video game tutorials, answer relevant questions to simulate human perception, and provide feedback. This feedback is compared with expected results to identify confusing or problematic scenes and highlight potential errors for developers. In addition, we publish complete tutorial videos and annotated frames from different game versions used in our tests. This solution reduces the need for extensive manual testing, especially by speeding up and simplifying the initial development stages of the tutorial to improve the final game experience.
KAN You See It? KANs and Sentinel for Effective and Explainable Crop Field Segmentation
Aug 13, 2024Segmentation of crop fields is essential for enhancing agricultural productivity, monitoring crop health, and promoting sustainable practices. Deep learning models adopted for this task must ensure accurate and reliable predictions to avoid economic losses and environmental impact. The newly proposed Kolmogorov-Arnold networks (KANs) offer promising advancements in the performance of neural networks. This paper analyzes the integration of KAN layers into the U-Net architecture (U-KAN) to segment crop fields using Sentinel-2 and Sentinel-1 satellite images and provides an analysis of the performance and explainability of these networks. Our findings indicate a 2\% improvement in IoU compared to the traditional full-convolutional U-Net model in fewer GFLOPs. Furthermore, gradient-based explanation techniques show that U-KAN predictions are highly plausible and that the network has a very high ability to focus on the boundaries of cultivated areas rather than on the areas themselves. The per-channel relevance analysis also reveals that some channels are irrelevant to this task.
Depth Any Canopy: Leveraging Depth Foundation Models for Canopy Height Estimation
Aug 08, 2024Estimating global tree canopy height is crucial for forest conservation and climate change applications. However, capturing high-resolution ground truth canopy height using LiDAR is expensive and not available globally. An efficient alternative is to train a canopy height estimator to operate on single-view remotely sensed imagery. The primary obstacle to this approach is that these methods require significant training data to generalize well globally and across uncommon edge cases. Recent monocular depth estimation foundation models have show strong zero-shot performance even for complex scenes. In this paper we leverage the representations learned by these models to transfer to the remote sensing domain for measuring canopy height. Our findings suggest that our proposed Depth Any Canopy, the result of fine-tuning the Depth Anything v2 model for canopy height estimation, provides a performant and efficient solution, surpassing the current state-of-the-art with superior or comparable performance using only a fraction of the computational resources and parameters. Furthermore, our approach requires less than \$1.30 in compute and results in an estimated carbon footprint of 0.14 kgCO2. Code, experimental results, and model checkpoints are openly available at https://github.com/DarthReca/depth-any-canopy.
Estimating Earthquake Magnitude in Sentinel-1 Imagery via Ranking
Jul 25, 2024

Earthquakes are commonly estimated using physical seismic stations, however, due to the installation requirements and costs of these stations, global coverage quickly becomes impractical. An efficient and lower-cost alternative is to develop machine learning models to globally monitor earth observation data to pinpoint regions impacted by these natural disasters. However, due to the small amount of historically recorded earthquakes, this becomes a low-data regime problem requiring algorithmic improvements to achieve peak performance when learning to regress earthquake magnitude. In this paper, we propose to pose the estimation of earthquake magnitudes as a metric-learning problem, training models to not only estimate earthquake magnitude from Sentinel-1 satellite imagery but to additionally rank pairwise samples. Our experiments show at max a 30%+ improvement in MAE over prior regression-only based methods, particularly transformer-based architectures.
Benchmarking Representations for Speech, Music, and Acoustic Events
May 02, 2024

Limited diversity in standardized benchmarks for evaluating audio representation learning (ARL) methods may hinder systematic comparison of current methods' capabilities. We present ARCH, a comprehensive benchmark for evaluating ARL methods on diverse audio classification domains, covering acoustic events, music, and speech. ARCH comprises 12 datasets, that allow us to thoroughly assess pre-trained SSL models of different sizes. ARCH streamlines benchmarking of ARL techniques through its unified access to a wide range of domains and its ability to readily incorporate new datasets and models. To address the current lack of open-source, pre-trained models for non-speech audio, we also release new pre-trained models that demonstrate strong performance on non-speech datasets. We argue that the presented wide-ranging evaluation provides valuable insights into state-of-the-art ARL methods, and is useful to pinpoint promising research directions.