 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydroChronos: Forecasting Decades of Surface Water Change
Jun 17, 2025Forecasting surface water dynamics is crucial for water resource management and climate change adaptation. However, the field lacks comprehensive datasets and standardized benchmarks. In this paper, we introduce HydroChronos, a large-scale, multi-modal spatiotemporal dataset for surface water dynamics forecasting designed to address this gap. We couple the dataset with three forecasting tasks. The dataset includes over three decades of aligned Landsat 5 and Sentinel-2 imagery, climate data, and Digital Elevation Models for diverse lakes and rivers across Europe, North America, and South America. We also propose AquaClimaTempo UNet, a novel spatiotemporal architecture with a dedicated climate data branch, as a strong benchmark baseline. Our model significantly outperforms a Persistence baseline for forecasting future water dynamics by +14% and +11% F1 across change detection and direction of change classification tasks, and by +0.1 MAE on the magnitude of change regression. Finally, we conduct an Explainable AI analysis to identify the key climate variables and input channels that influence surface water change, providing insights to inform and guide future modeling efforts.
DeepDialogue: A Multi-Turn Emotionally-Rich Spoken Dialogue Dataset
May 26, 2025Recent advances in conversational AI have demonstrated impressive capabilities in single-turn responses, yet multi-turn dialogues remain challenging for even the most sophisticated language models. Current dialogue datasets are limited in their emotional range, domain diversity, turn depth, and are predominantly text-only, hindering progress in developing more human-like conversational systems across modalities. To address these limitations, we present DeepDialogue, a large-scale multimodal dataset containing 40,150 high-quality multi-turn dialogues spanning 41 domains and incorporating 20 distinct emotions with coherent emotional progressions. Our approach pairs 9 different language models (4B-72B parameters) to generate 65,600 initial conversations, which we then evaluate through a combination of human annotation and LLM-based quality filtering. The resulting dataset reveals fundamental insights: smaller models fail to maintain coherence beyond 6 dialogue turns; concrete domains (e.g., "cars," "travel") yield more meaningful conversations than abstract ones (e.g., "philosophy"); and cross-model interactions produce more coherent dialogues than same-model conversations. A key contribution of DeepDialogue is its speech component, where we synthesize emotion-consistent voices for all 40,150 dialogues, creating the first large-scale open-source multimodal dialogue dataset that faithfully preserves emotional context across multi-turn conversations.
MVP: Multi-source Voice Pathology detection
May 26, 2025Voice disorders significantly impact patient quality of life, yet non-invasive automated diagnosis remains under-explored due to both the scarcity of pathological voice data, and the variability in recording sources. This work introduces MVP (Multi-source Voice Pathology detection), a novel approach that leverages transformers operating directly on raw voice signals. We explore three fusion strategies to combine sentence reading and sustained vowel recordings: waveform concatenation, intermediate feature fusion, and decision-level combination. Empirical validation across the German, Portuguese, and Italian languages shows that intermediate feature fusion using transformers best captures the complementary characteristics of both recording types. Our approach achieves up to +13% AUC improvement over single-source methods.
"KAN you hear me?" Exploring Kolmogorov-Arnold Networks for Spoken Language Understanding
May 26, 2025



Kolmogorov-Arnold Networks (KANs) have recently emerged as a promising alternative to traditional neural architectures, yet their application to speech processing remains under explored. This work presents the first investigation of KANs for Spoken Language Understanding (SLU) tasks. We experiment with 2D-CNN models on two datasets, integrating KAN layers in five different configurations within the dense block. The best-performing setup, which places a KAN layer between two linear layers, is directly applied to transformer-based models and evaluated on five SLU datasets with increasing complexity. Our results show that KAN layers can effectively replace the linear layers, achieving comparable or superior performance in most cases. Finally, we provide insights into how KAN and linear layers on top of transformers differently attend to input regions of the raw waveforms.
"Alexa, can you forget me?" Machine Unlearning Benchmark in Spoken Language Understanding
May 21, 2025Machine unlearning, the process of efficiently removing specific information from machine learning models, is a growing area of interest for responsible AI. However, few studies have explored the effectiveness of unlearning methods on complex tasks, particularly speech-related ones. This paper introduces UnSLU-BENCH, the first benchmark for machine unlearning in spoken language understanding (SLU), focusing on four datasets spanning four languages. We address the unlearning of data from specific speakers as a way to evaluate the quality of potential "right to be forgotten" requests. We assess eight unlearning techniques and propose a novel metric to simultaneously better capture their efficacy, utility, and efficiency. UnSLU-BENCH sets a foundation for unlearning in SLU and reveals significant differences in the effectiveness and computational feasibility of various techniques.
voc2vec: A Foundation Model for Non-Verbal Vocalization
Feb 22, 2025



Speech foundation models have demonstrated exceptional capabilities in speech-related tasks. Nevertheless, these models often struggle with non-verbal audio data, such as vocalizations, baby crying, etc., which are critical for various real-world applications. Audio foundation models well handle non-speech data but also fail to capture the nuanced features of non-verbal human sounds. In this work, we aim to overcome the above shortcoming and propose a novel foundation model, termed voc2vec, specifically designed for non-verbal human data leveraging exclusively open-source non-verbal audio datasets. We employ a collection of 10 datasets covering around 125 hours of non-verbal audio. Experimental results prove that voc2vec is effective in non-verbal vocalization classification, and it outperforms conventional speech and audio foundation models. Moreover, voc2vec consistently outperforms strong baselines, namely OpenSmile and emotion2vec, on six different benchmark datasets. To the best of the authors' knowledge, voc2vec is the first universal representation model for vocalization tasks.
Detecting Interpretable Subgroup Drifts
Aug 26, 2024


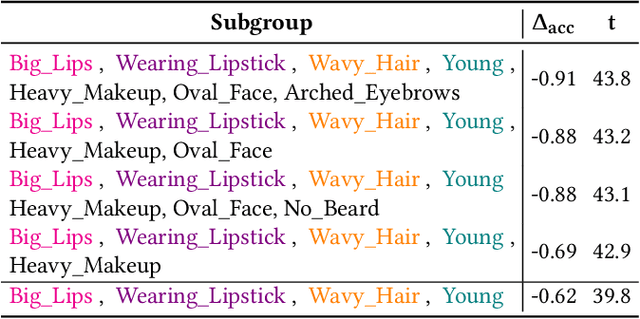
The ability to detect and adapt to changes in data distributions is crucial to maintain the accuracy and reliability of machine learning models. Detection is generally approached by observing the drift of model performance from a global point of view. However, drifts occurring in (fine-grained) data subgroups may go unnoticed when monitoring global drift. We take a different perspective, and introduce methods for observing drift at the finer granularity of subgroups. Relevant data subgroups are identified during training and monitored efficiently throughout the model's life. Performance drifts in any subgroup are detected, quantified and characterized so as to provide an interpretable summary of the model behavior over time. Experimental results confirm that our subgroup-level drift analysis identifies drifts that do not show at the (coarser) global dataset level. The proposed approach provides a valuable tool for monitoring model performance in dynamic real-world applications, offering insights into the evolving nature of data and ultimately contributing to more robust and adaptive models.
A Synthetic Benchmark to Explore Limitations of Localized Drift Detections
Aug 26, 2024Concept drift is a common phenomenon in data streams where the statistical properties of the target variable change over time. Traditionally, drift is assumed to occur globally, affecting the entire dataset uniformly. However, this assumption does not always hold true in real-world scenarios where only specific subpopulations within the data may experience drift. This paper explores the concept of localized drift and evaluates the performance of several drift detection techniques in identifying such localized changes. We introduce a synthetic dataset based on the Agrawal generator, where drift is induced in a randomly chosen subgroup. Our experiments demonstrate that commonly adopted drift detection methods may fail to detect drift when it is confined to a small subpopulation. We propose and test various drift detection approaches to quantify their effectiveness in this localized drift scenario. We make the source code for the generation of the synthetic benchmark available at https://github.com/fgiobergia/subgroup-agrawal-drift.
KAN You See It? KANs and Sentinel for Effective and Explainable Crop Field Segmentation
Aug 13, 2024Segmentation of crop fields is essential for enhancing agricultural productivity, monitoring crop health, and promoting sustainable practices. Deep learning models adopted for this task must ensure accurate and reliable predictions to avoid economic losses and environmental impact. The newly proposed Kolmogorov-Arnold networks (KANs) offer promising advancements in the performance of neural networks. This paper analyzes the integration of KAN layers into the U-Net architecture (U-KAN) to segment crop fields using Sentinel-2 and Sentinel-1 satellite images and provides an analysis of the performance and explainability of these networks. Our findings indicate a 2\% improvement in IoU compared to the traditional full-convolutional U-Net model in fewer GFLOPs. Furthermore, gradient-based explanation techniques show that U-KAN predictions are highly plausible and that the network has a very high ability to focus on the boundaries of cultivated areas rather than on the areas themselves. The per-channel relevance analysis also reveals that some channels are irrelevant to this task.
Speech Analysis of Language Varieties in Italy
Jun 22, 2024
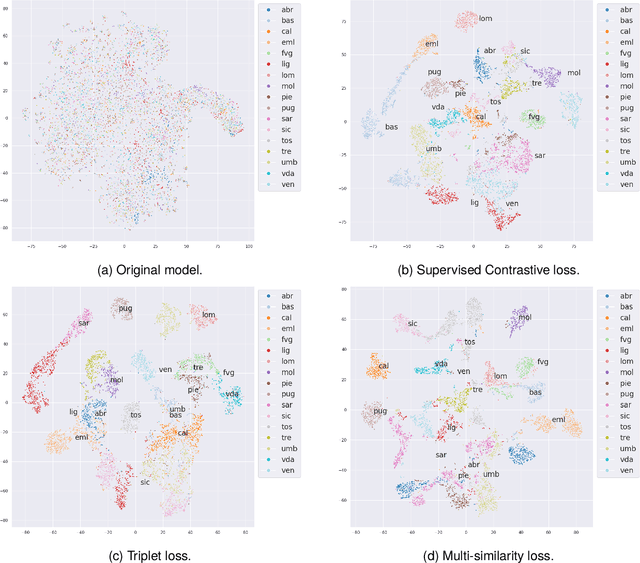

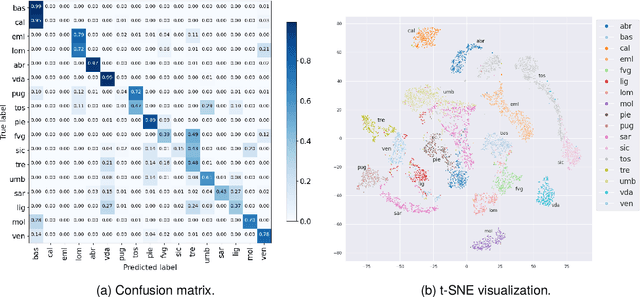
Italy exhibits rich linguistic diversity across its territory due to the distinct regional languages spoken in different areas. Recent advances in self-supervised learning provide new opportunities to analyze Italy's linguistic varieties using speech data alone. This includes the potential to leverage representations learned from large amounts of data to better examine nuances between closely related linguistic varieties. In this study, we focus on automatically identifying the geographic region of origin of speech samples drawn from Italy's diverse language varieties. We leverage self-supervised learning models to tackle this task and analyze differences and similarities between Italy's regional languages. In doing so, we also seek to uncover new insights into the relationships among these diverse yet closely related varieties, which may help linguists understand their interconnected evolution and regional development over time and space. To improve the discriminative ability of learned representations, we evaluate several supervised contrastive learning objectives, both as pre-training steps and additional fine-tuning objectives. Experimental evidence shows that pre-trained self-supervised models can effectively identify regions from speech recording. Additionally, incorporating contrastive objectives during fine-tuning improves classification accuracy and yields embeddings that distinctly separate regional varieties, demonstrating the value of combining self-supervised pre-training and contrastive learning for this task.